glow tts
1.0.0
在最近的论文中,我们提出了Glow-TTS:通过单调对准搜索进行文本到语音的生成流程。
最近,已经提出了文本对语音(TTS)模型,例如FastSpeech和Paranet,以并行从文本中生成MEL-SEXPROGRAM。尽管有优势,但如果没有自回归TTS模型作为其外部对齐器的指导,则不能对平行的TTS模型进行培训。在这项工作中,我们提出了Glow-TTS,这是一种基于流动的生成模型,用于并行TT,不需要任何外部对齐器。通过结合流量和动态编程的属性,提出的模型可以搜索文本和语音潜在语音之间最可能的单调比对。我们证明,执行硬单调的对准可以实现强大的TT,从而概括了长时间的话语,并且采用生成流动可以快速,多样化和可控制的语音综合。 Glow-TTS在合成时以相当的语音质量而获得了自回归模型TaCotron 2的速度速度加速。我们进一步表明,我们的模型可以轻松扩展到多演讲者的设置。
访问我们的演示以获取音频样本。
我们还提供了验证的模型。
| 在训练中发光 | 推理时发光 |
|---|---|
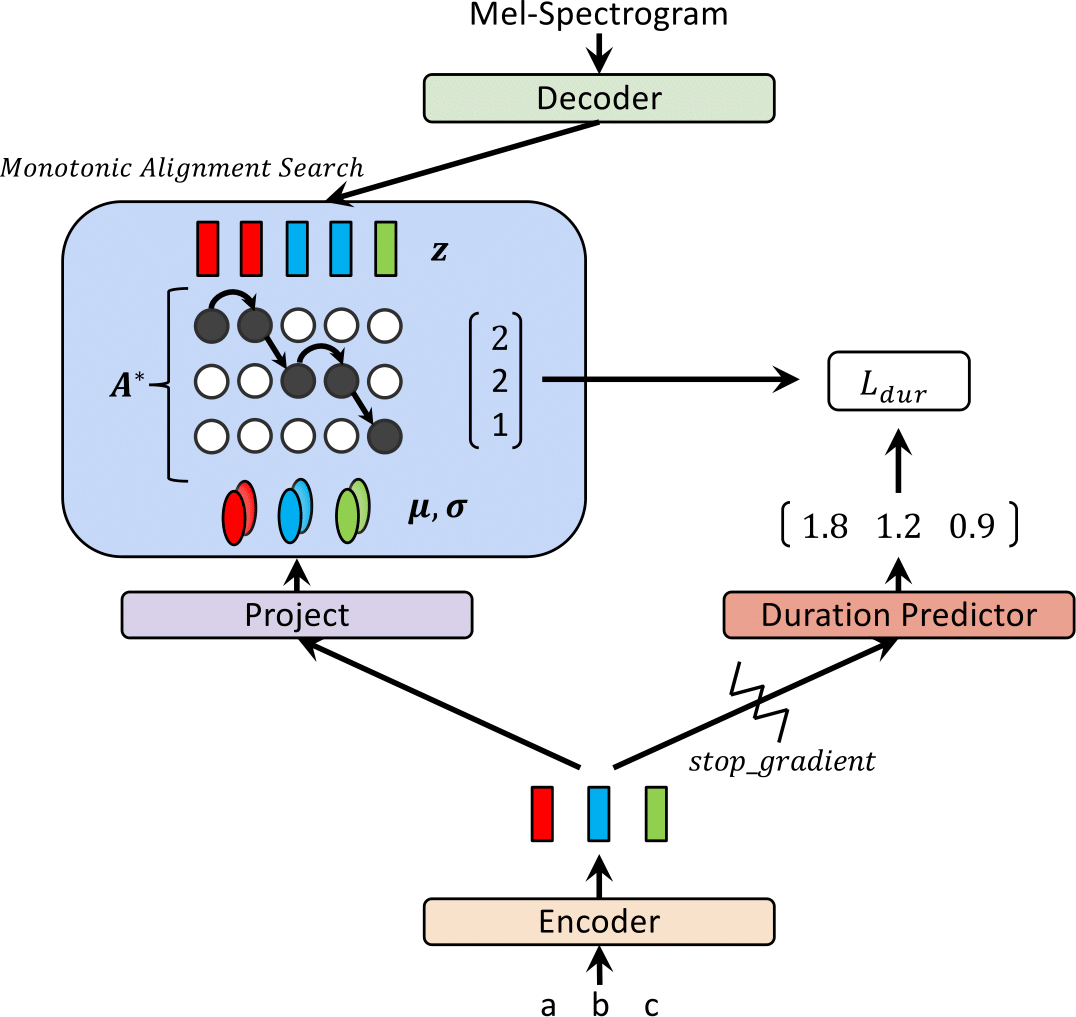 | 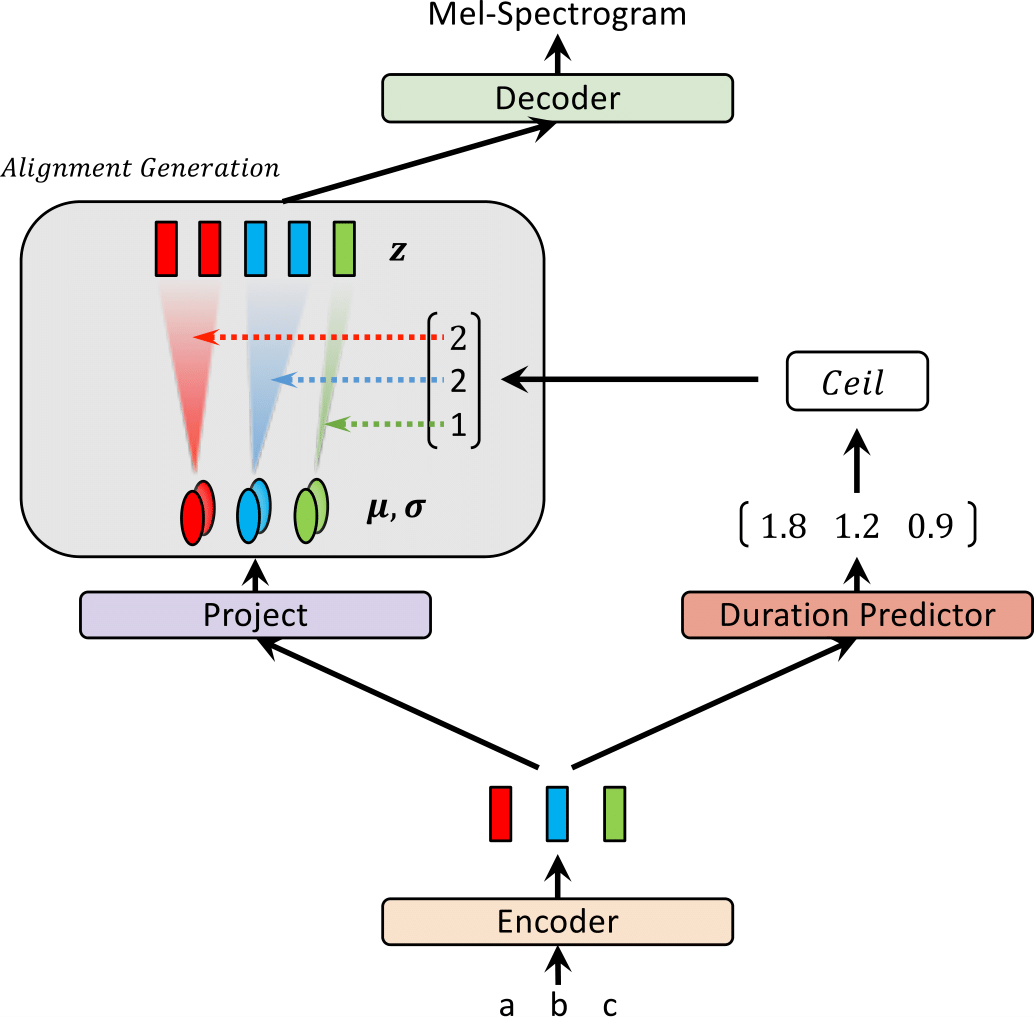 |
该结果不包括在论文中。最近,我们发现两种修改有助于提高Glow-TTS的合成质量。 1)搬到Vocoder,Hifi-GAN以减少噪声,2)将空白令牌放在任何两个输入令牌之间以改善发音。具体而言,我们使用了带有Tacotron 2的微型辅助声码器,该声音器在HIFI-GAN存储库中作为验证模型提供。如果您有兴趣,请听我们的演示中的样本。
为了添加空白令牌,我们提供了一个配置文件和验证的模型。我们还提供了一个推理示例temperion_hifigan.ipynb。您可能需要初始化hifi-gan子模块: git submodule init; git submodule update
对于混合精确培训,我们使用APEX;提交:37CDAF4
a)下载并提取LJ语音数据集,然后重命名或创建指向数据集文件夹的链接: ln -s /path/to/LJSpeech-1.1/wavs DUMMY
b)初始化wavelow subsodule: git submodule init; git submodule update
不要忘记下载验证的Wavellow模型,然后将其放入Wavellow文件夹中。
c)构建单调对齐搜索代码(Cython): cd monotonic_align; python setup.py build_ext --inplace
sh train_ddi.sh configs/base.json base请参阅推理。IPYNB
我们的实施受到以下存储库的极大影响:


