glow tts
1.0.0
최근 논문에서 우리는 단조로운 정렬 검색을 통한 텍스트 음성 연설을위한 Glow-Tts : 생성 흐름을 제안합니다.
최근에, FastSpeech 및 Paranet과 같은 TTS (Text-To-Steeech) 모델은 텍스트에서 Mel-spectrogram을 병렬로 생성하기 위해 제안되었습니다. 이점에도 불구하고, 평행 TTS 모델은 외부 정렬기로서 자동 회귀 TTS 모델의 지침없이 교육을받을 수 없습니다. 이 작업에서는 외부 정렬기가 필요하지 않은 병렬 TTS에 대한 유량 기반 생성 모델 인 Glow-TTS를 제안합니다. 흐름과 동적 프로그래밍의 속성을 결합함으로써 제안 된 모델은 텍스트와 스피치의 잠재적 표현 사이의 가장 가능성있는 단조로운 정렬을 검색합니다. 우리는 단단한 단조 적 정렬을 시행하면 강력한 TTS가 가능하며, 이는 긴 발언으로 일반화되며 생성 흐름을 사용하면 빠르고 다양하며 제어 가능한 음성 합성을 가능하게합니다. Glow-TTS는 비슷한 음성 품질과 합성하여자가 회귀 모델 인 Tacotron 2에 비해 크기의 속도 속도를 높입니다. 또한 모델을 멀티 스피커 설정으로 쉽게 확장 할 수 있음을 보여줍니다.
오디오 샘플은 데모를 방문하십시오.
우리는 또한 사전 치료 된 모델을 제공합니다.
| 훈련시 빛을 발합니다 | 추론에 빛을 발합니다 |
|---|---|
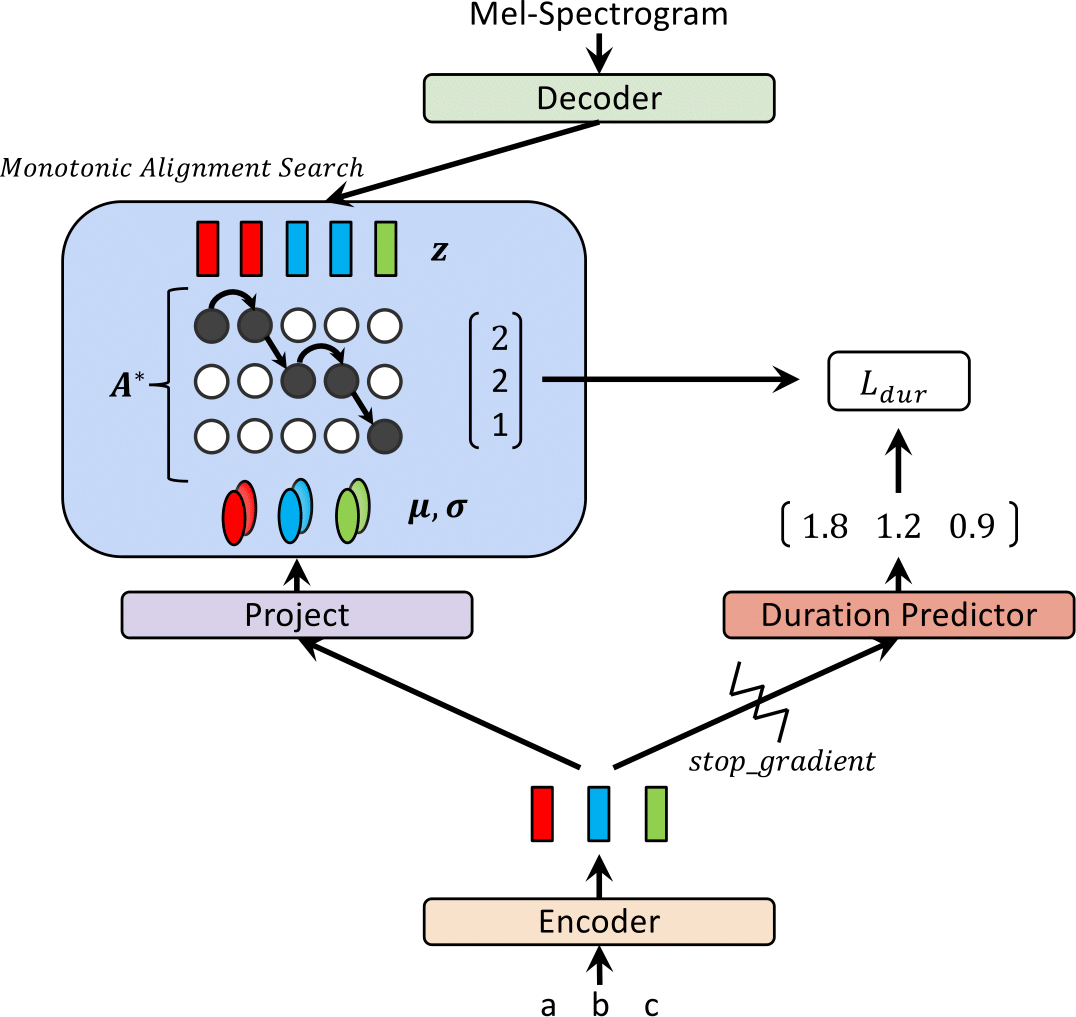 | 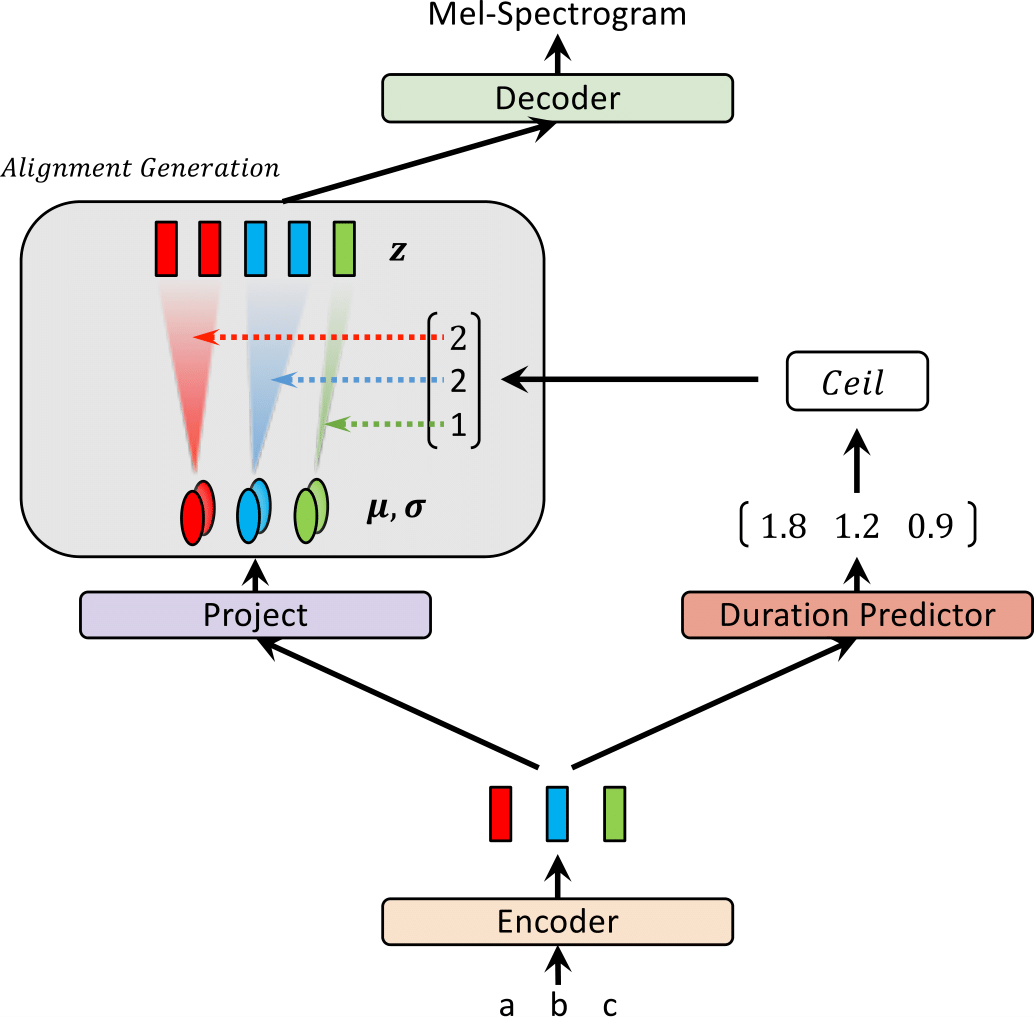 |
이 결과는 논문에 포함되지 않았습니다. 최근에, 우리는 두 가지 변형이 글로우 -Tts의 합성 품질을 향상시키는 데 도움이된다는 것을 발견했습니다.; 1) 소음을 줄이기 위해 Hifi-Gan, 보코더로 이동, 2) 발음을 향상시키기 위해 두 개의 입력 토큰 사이에 빈 토큰을 넣습니다. 구체적으로, 우리는 Hifi-Gan Repo에서 사전 각인 모델로 제공되는 Tacotron 2와 함께 미세 조정 된 보코더를 사용했습니다. 관심이 있으시면 데모의 샘플을 들어보세요.
빈 토큰을 추가하기 위해 구성 파일과 사전 예방 모델을 제공합니다. 또한 추론 예제 inference_hifigan.ipynb를 제공합니다. hifi-gan 하위 모듈을 초기화해야 할 수도 있습니다 : git submodule init; git submodule update
혼합-정밀 훈련의 경우 Apex를 사용합니다. 커밋 : 37CDAF4
A) LJ Speech DataSet을 다운로드하여 추출한 다음 데이터 세트 폴더로 이름을 바꾸거나 만듭니다 : ln -s /path/to/LJSpeech-1.1/wavs DUMMY
b) waveglow submodule 초기화 : git submodule init; git submodule update
사전에 사전 된 WaveGlow 모델을 다운로드하여 WaveGlow 폴더에 배치하는 것을 잊지 마십시오.
c) Monotonic Alignment Search Code (Cython) 빌드 : cd monotonic_align; python setup.py build_ext --inplace
sh train_ddi.sh configs/base.json base추론 .ipynb를 참조하십시오
우리의 구현은 다음과 같은 저장소에 큰 영향을받습니다.


