glow tts
1.0.0
In unserem jüngsten Artikel schlagen wir Glow-TTs vor: einen generativen Fluss für Text-zu-Sprache über die monotonische Ausrichtungssuche.
Kürzlich wurden Text-to-Speech-Modelle (TTS) wie Fastspeech und Paranet vorgeschlagen, um Melspektrogramme aus Text parallel zu erzeugen. Trotz des Vorteils können die parallelen TTS -Modelle nicht ohne Anleitung durch autoregressive TTS -Modelle als externe Aligner ausgebildet werden. In dieser Arbeit schlagen wir Glow-TTs vor, ein fließbasiertes generatives Modell für parallele TTs, für das kein externer Aligner erforderlich ist. Durch die Kombination der Eigenschaften von Strömungen und dynamischen Programmierungen sucht das vorgeschlagene Modell nach der wahrscheinlichsten monotonischen Ausrichtung zwischen Text und der latenten Repräsentation der Sprache alleine. Wir zeigen, dass die Durchsetzung harter monotoner Ausrichtungen robuste TTs ermöglicht, die sich auf lange Äußerungen verallgemeinern und generative Flüsse eine schnelle, vielfältige und kontrollierbare Sprachsynthese ermöglichen. Glow-TTs erhält eine Geschwindigkeit der Größenordnung über das autoregressive Modell Tacotron 2 bei Synthese mit vergleichbarer Sprachqualität. Wir zeigen weiter, dass unser Modell leicht auf eine Multi-Sprecher-Einstellung ausgedehnt werden kann.
Besuchen Sie unsere Demo für Audio -Beispiele.
Wir bieten auch das vorbereitete Modell an.
| Glow-TTS beim Training | Glow-Tts bei Inferenz |
|---|---|
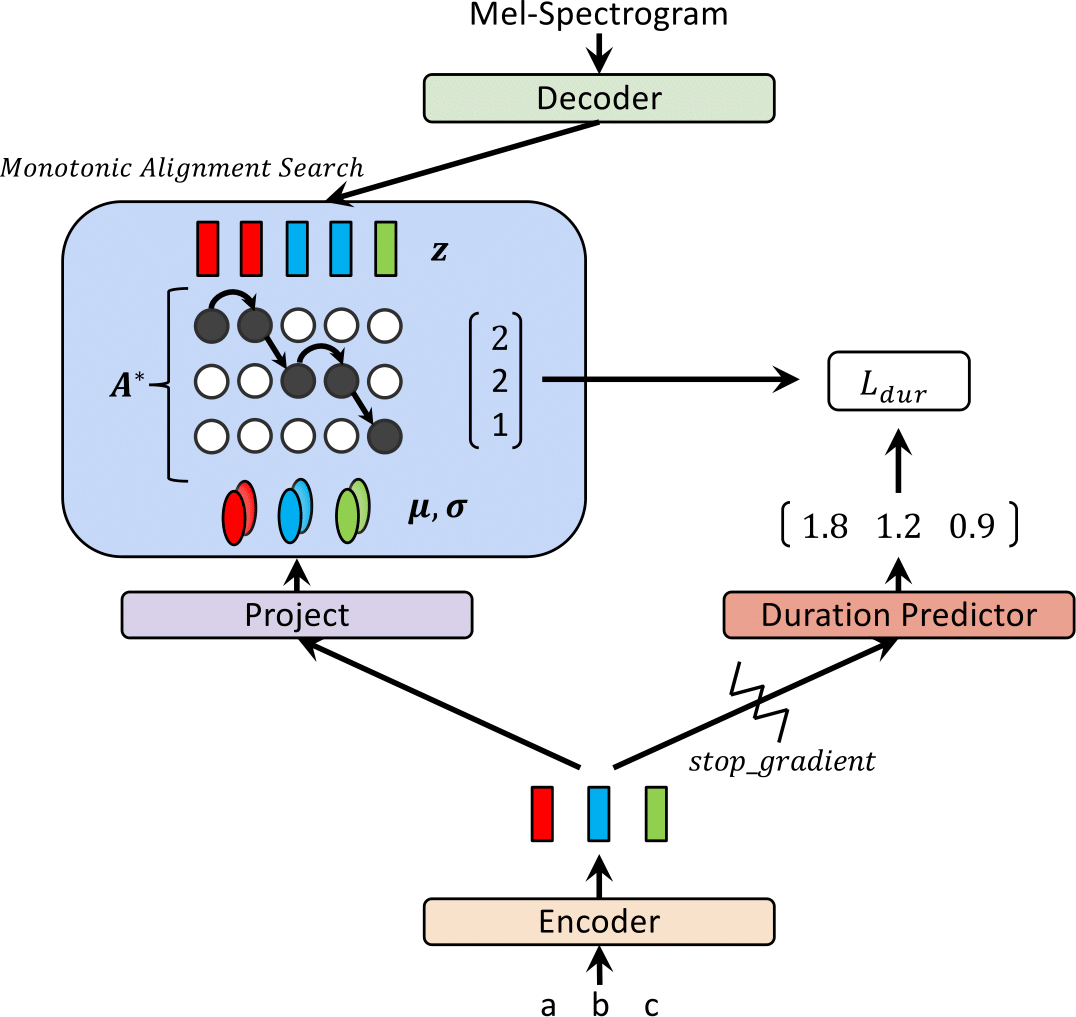 | 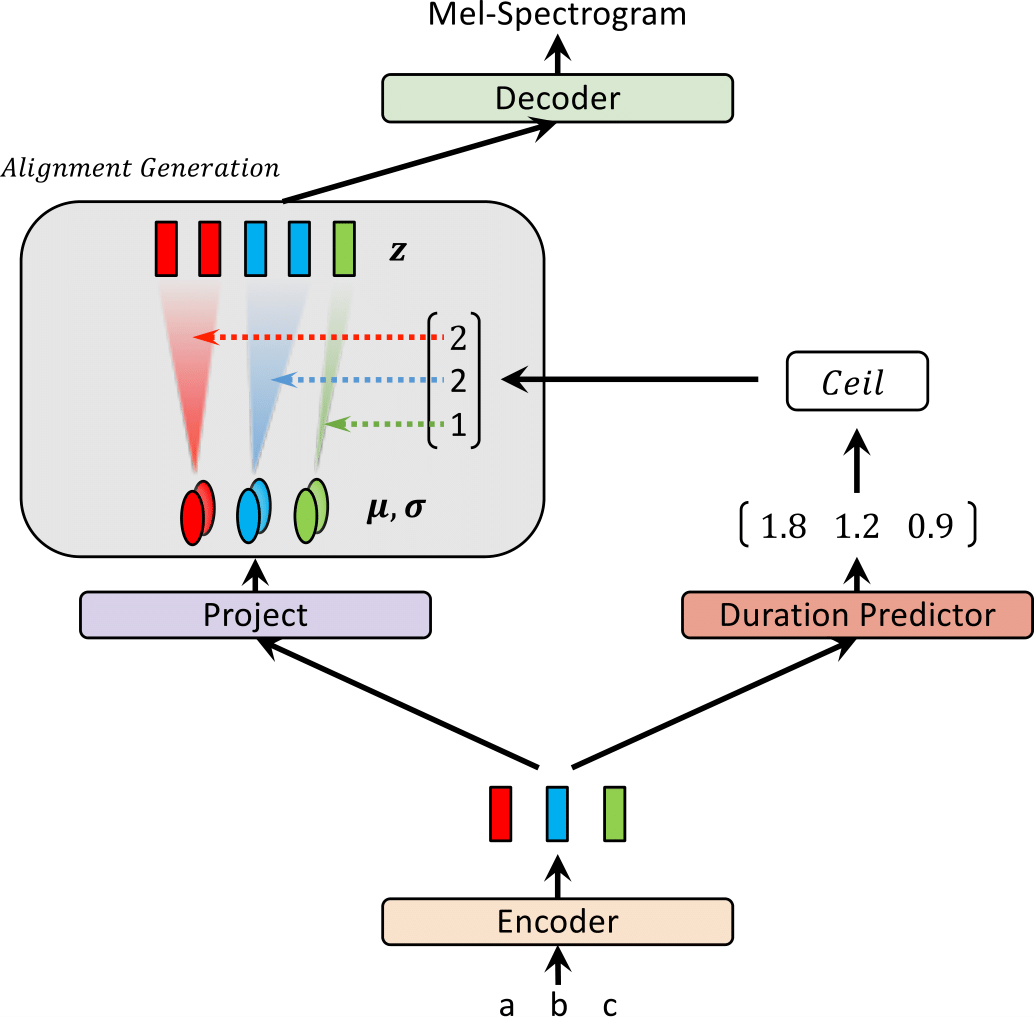 |
Dieses Ergebnis wurde nicht in das Papier enthalten. In letzter Zeit stellten wir fest, dass zwei Modifikationen dazu beitragen, die Synthesequalität von Glow-TTs zu verbessern. 1) Umzug in einen Vokoder, Hifi-Gan, um das Geräusch zu reduzieren, 2) Ein leeres Token zwischen zwei beliebigen Eingangs-Token, um die Aussprache zu verbessern. Insbesondere haben wir einen fein abgestimmten Vocoder mit Tacotron 2 verwendet, der als vorbereitete Modell im Hifi-Gan-Repo bereitgestellt wird. Wenn Sie interessiert sind, hören Sie bitte die Muster in unserer Demo an.
Für das Hinzufügen eines leeren Tokens stellen wir eine Konfigurationsdatei und ein vorgezogenes Modell bereit. Wir bieten auch ein Inferenzbeispiel Inference_HiFigan.ipynb. Möglicherweise müssen Sie Hifi-Gan-Submodul: git submodule init; git submodule update
Für Schulungen mit gemischtem Präzision verwenden wir Apex. Commit: 37CDAF4
a) Laden Sie den LJ -Sprachdatensatz herunter und extrahieren Sie sie und erstellen Sie dann einen Link zum Dataset -Ordner: ln -s /path/to/LJSpeech-1.1/wavs DUMMY
b) Initialisieren von Wellenlow -Submodul: git submodule init; git submodule update
Vergessen Sie nicht, ein vorgezogenes Wellenlow -Modell herunterzuladen und es in den Wellenlow -Ordner zu legen.
c) Suchcode für den monotonischen Alignment -Suchcode (Cython) erstellen: cd monotonic_align; python setup.py build_ext --inplace
sh train_ddi.sh configs/base.json baseSiehe Inferenz.ipynb
Unsere Umsetzung wird stark von den folgenden Repos beeinflusst:


