glow tts
1.0.0
En nuestro artículo reciente, proponemos GLOW-TTS: un flujo generativo para texto a voz a través de la búsqueda de alineación monotónica.
Recientemente, se han propuesto modelos de texto a voz (TTS) como FastSpeech y Paranet para generar espectrogramas MEL a partir de texto en paralelo. A pesar de la ventaja, los modelos TTS paralelos no pueden ser entrenados sin orientación de los modelos TTS autorregresivos como sus alineadores externos. En este trabajo, proponemos GLOW-TTS, un modelo generativo basado en el flujo para TTS paralelos que no requiere ningún alineador externo. Al combinar las propiedades de los flujos y la programación dinámica, el modelo propuesto busca la alineación monotónica más probable entre el texto y la representación latente del habla por sí solo. Demostramos que hacer cumplir las alineaciones monotónicas duras permite TTS robustos, lo que se generaliza a largas expresiones, y emplear flujos generativos permite la síntesis de habla rápida, diversa y controlable. Glow-TTS obtiene una aceleración de orden de magnitud sobre el modelo autorregresivo, Tacotron 2, en síntesis con calidad de voz comparable. Además, mostramos que nuestro modelo se puede extender fácilmente a una configuración de múltiples altavoces.
Visite nuestra demostración para muestras de audio.
También proporcionamos el modelo previo al estado previo.
| Glow-TTS en el entrenamiento | Glow-Tts a inferencia |
|---|---|
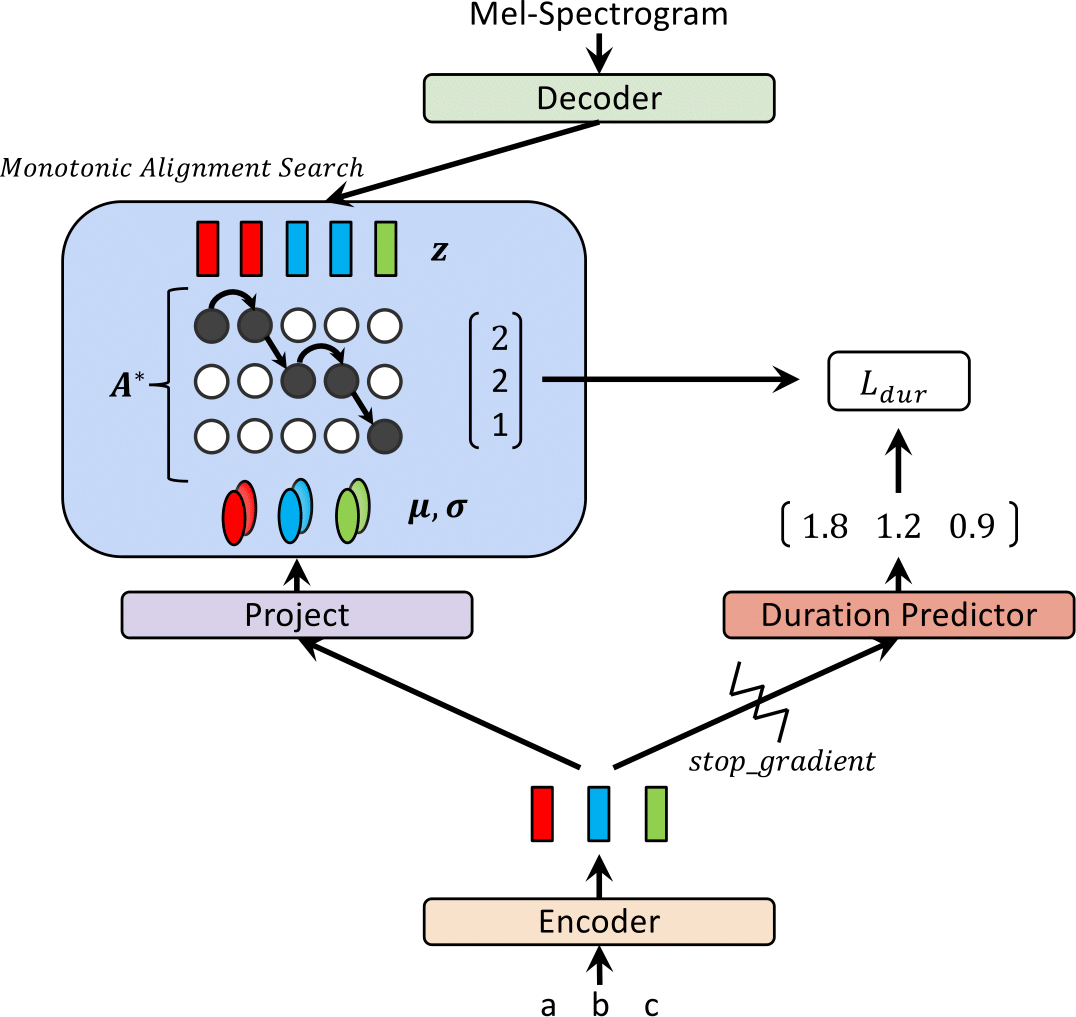 | 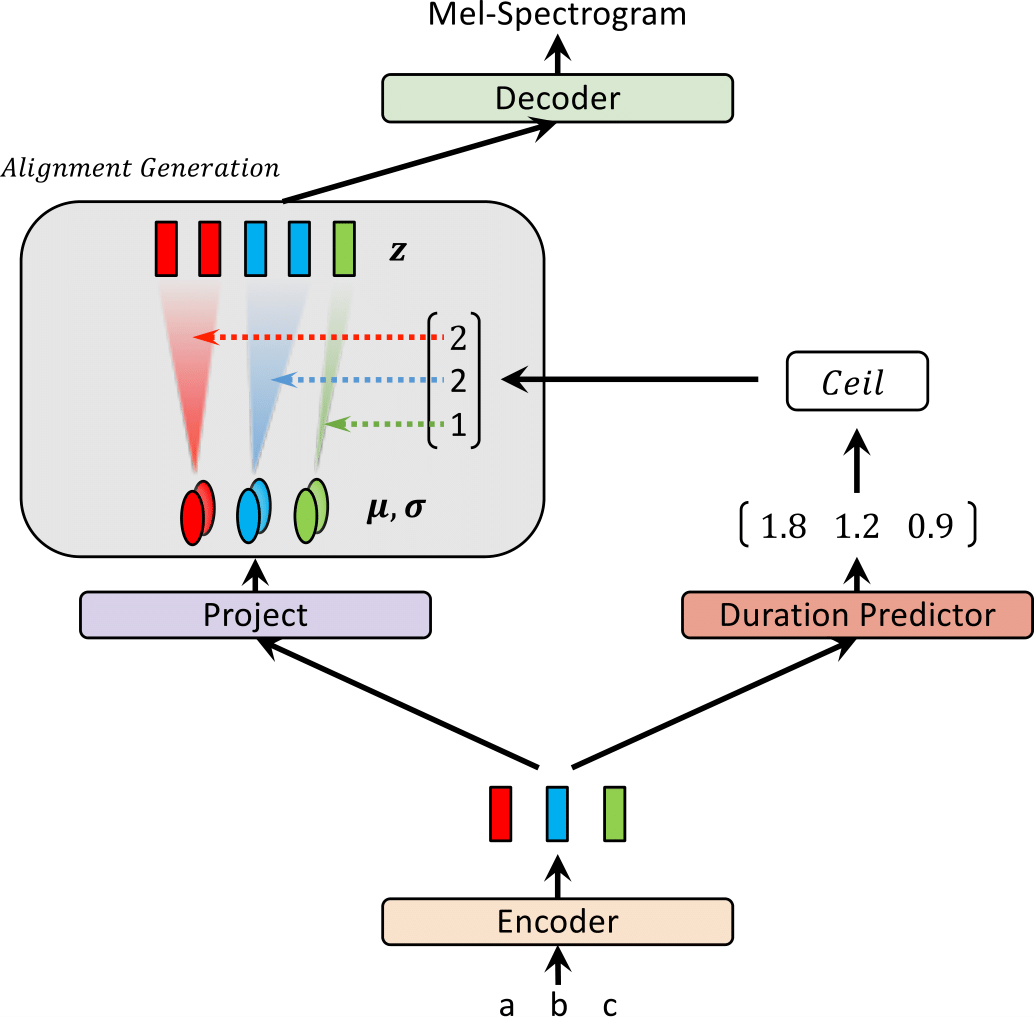 |
Este resultado no fue incluido en el documento. Últimamente, encontramos que dos modificaciones ayudan a mejorar la calidad de síntesis de Glow-TTS.; 1) Movirse a un vocoder, Hifi-Gan para reducir el ruido, 2) poner una ficha en blanco entre dos tokens de entrada para mejorar la pronunciación. Específicamente, utilizamos un vocoder ajustado con Tacotron 2, que se proporciona como un modelo previo a la petróleo en el repositorio de Hifi-Gan. Si está interesado, escuche las muestras en nuestra demostración.
Para agregar un token en blanco, proporcionamos un archivo de configuración y un modelo de petróleo. También proporcionamos un ejemplo de inferencia Inferencia_hifigan.ipynb. Es posible que deba inicializar Hifi-Gan Submódulo: git submodule init; git submodule update
Para el entrenamiento de precisión mixta, usamos APEX; Compromiso: 37CDAF4
a) Descargue y extraiga el conjunto de datos de discurso LJ, luego cambie el nombre o cree un enlace a la carpeta del conjunto de datos: ln -s /path/to/LJSpeech-1.1/wavs DUMMY
b) Inicializar Submódulo de Glow: git submodule init; git submodule update
No olvides descargar el modelo de Glow de Wave Wave y colóquelo en la carpeta de Glow de Wave.
c) construir código de búsqueda de alineación monotónica (Cython): cd monotonic_align; python setup.py build_ext --inplace
sh train_ddi.sh configs/base.json baseVer inferencia.ipynb
Nuestra implementación está enormemente influenciada por los siguientes Repos:


