glow tts
1.0.0
В нашей недавней статье мы предлагаем Glow-TTS: генеративный поток для текста в речь с помощью монотонного поиска выравнивания.
В последнее время были предложены модели текста в речь (TTS), такие как Fastspeech и Paranet для генерации мель-спектрограммов из текста параллельно. Несмотря на преимущество, модели параллельных TTS не могут быть обучены без руководства из авторегрессивных моделей TTS в качестве их внешних выравнивателей. В этой работе мы предлагаем Glow-TTS, генеративную модель на основе потока для параллельных TTS, которая не требует никакого внешнего выравнивателя. Сочетая свойства потоков и динамического программирования, предлагаемая модель ищет наиболее вероятное монотонное выравнивание между текстом и скрытым представлением речи самостоятельно. Мы демонстрируем, что обеспечение соблюдения жестких монотонных выравниваний позволяет обеспечивать надежные TTS, что обобщается до длинных высказываний, а использование генеративных потоков позволяет быстро, разнообразно и контролируемый синтез речи. Glow-TTS получает ускорение порядка матча над авторегрессивной моделью Tacotron 2, при синтезе с сопоставимым качеством речи. Мы также показываем, что наша модель может быть легко расширена на многопрофильную настройку.
Посетите нашу демонстрацию для образцов аудио.
Мы также предоставляем предварительную модель.
| Glow-TTS на тренировке | Glow-TTS при выводе |
|---|---|
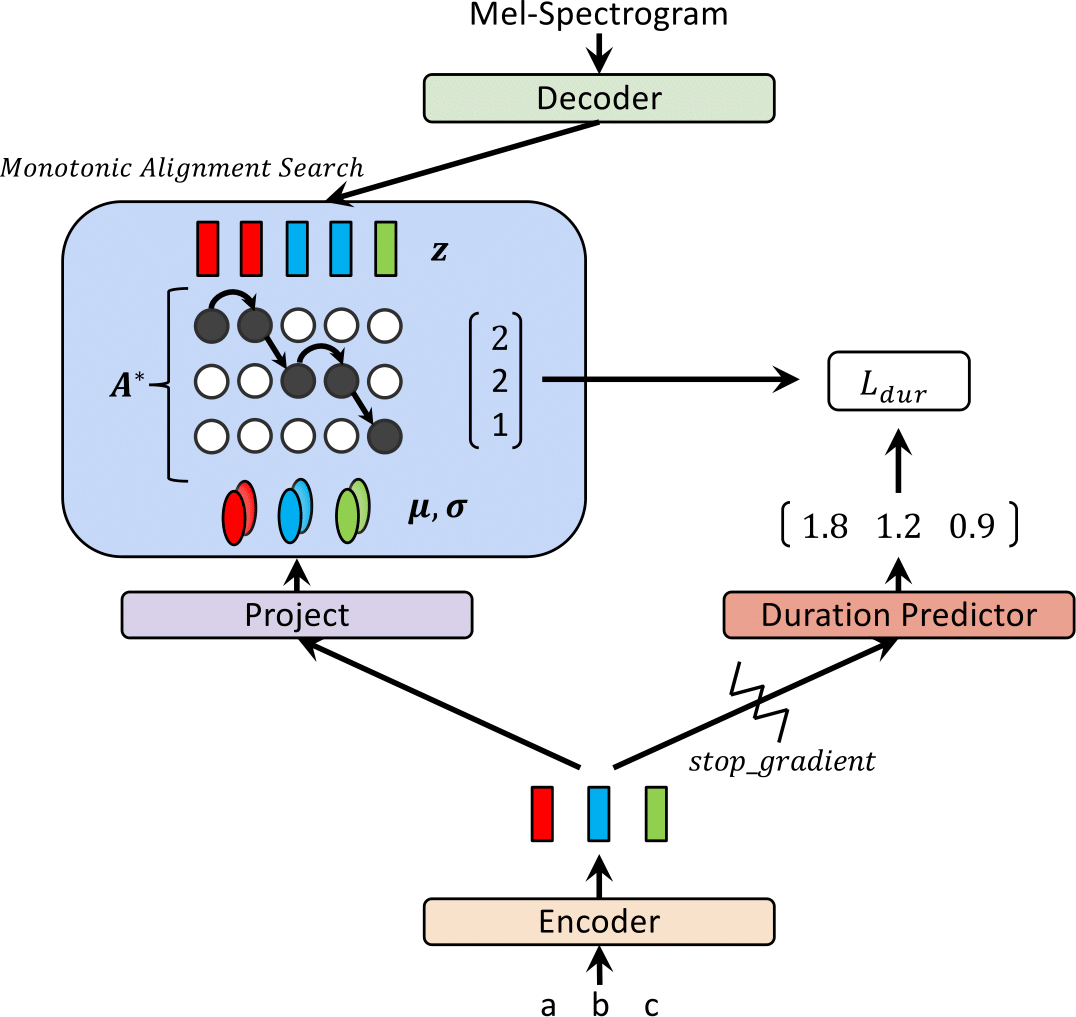 | 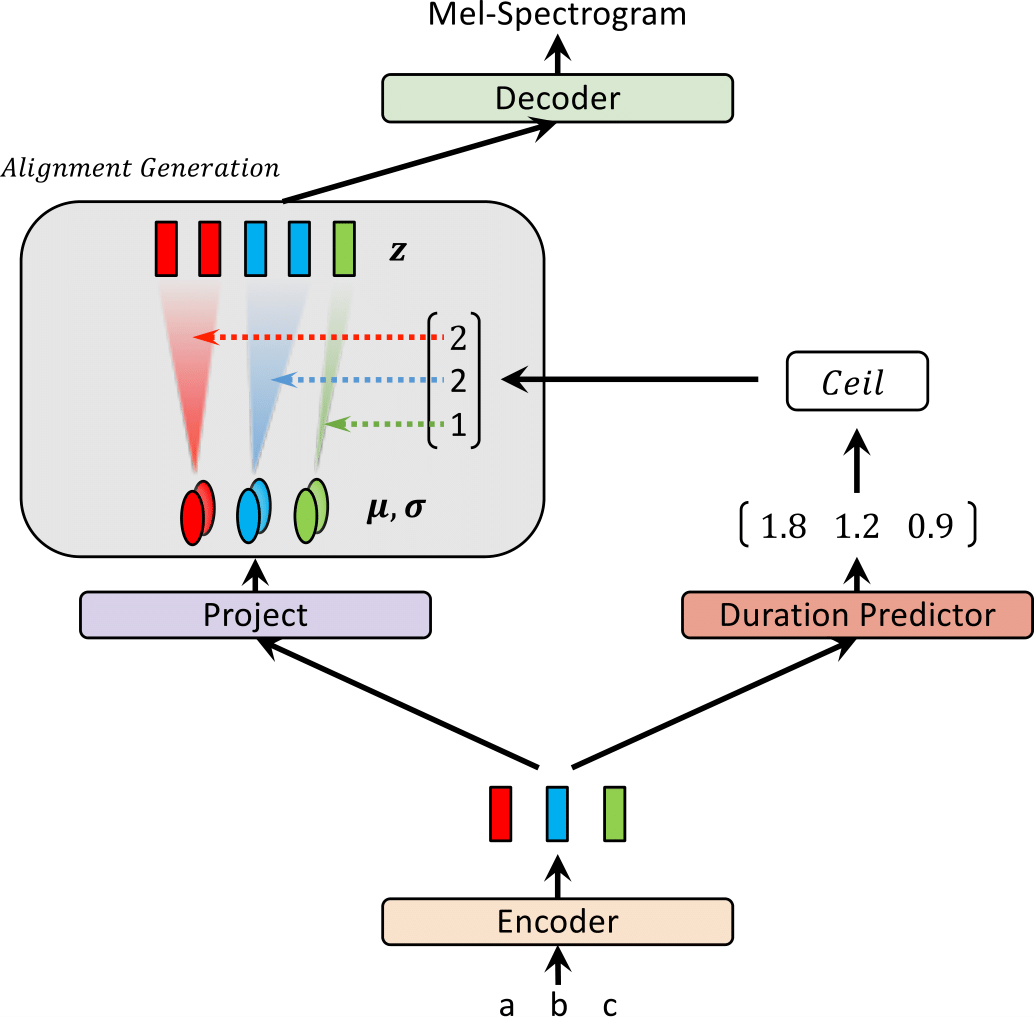 |
Этот результат не был включен в статью. В последнее время мы обнаружили, что две модификации помогают улучшить качество синтеза Glow-TTS.; 1) Переход к вокадеру, Hifi-Gan, чтобы уменьшить шум, 2) поместить пустой токен между любыми двумя входными токенами для улучшения произношения. В частности, мы использовали тонко настроенный вокадер с Tacotron 2, который предоставляется в качестве предварительной модели в репо. Если вам интересно, пожалуйста, послушайте образцы в нашей демонстрации.
Для добавления пустого токена мы предоставляем файл конфигурации и предварительную модель. Мы также предоставляем пример вывода sepence_hifigan.ipynb. Вам может потребоваться инициализировать Hifi-Gan Submodule: git submodule init; git submodule update
Для обучения смешанного назначения мы используем Apex; Коммит: 37cdaf4
A) Загрузить и извлечь набор данных речи LJ, затем переименовать или создать ссылку на папку набора данных: ln -s /path/to/LJSpeech-1.1/wavs DUMMY
б) инициализировать подмодуль волнового хлопка: git submodule init; git submodule update
Не забудьте скачать модель с предварительным волновым хлопком и поместить ее в папку волнового замка.
c) Создание кода поиска монотонного выравнивания (Cython): cd monotonic_align; python setup.py build_ext --inplace
sh train_ddi.sh configs/base.json baseСмотрите senuction.ipynb
На нашу реализацию чрезвычайно влияет следующие репо:


