glow tts
1.0.0
Dalam makalah kami baru-baru ini, kami mengusulkan Glow-TTS: Aliran generatif untuk teks-ke-speech melalui pencarian penyelarasan monotonik.
Baru-baru ini, model Text-to-Speech (TTS) seperti FastSpeech dan Paranet telah diusulkan untuk menghasilkan Mel-spectrograms dari teks secara paralel. Terlepas dari keuntungannya, model TTS paralel tidak dapat dilatih tanpa panduan dari model TTS Autoregresif sebagai pelurus eksternal mereka. Dalam karya ini, kami mengusulkan GLOW-TTS, model generatif berbasis aliran untuk TTS paralel yang tidak memerlukan pelurus eksternal. Dengan menggabungkan sifat -sifat aliran dan pemrograman dinamis, model yang diusulkan mencari penyelarasan monotonik yang paling mungkin antara teks dan representasi laten dari pidato sendiri. Kami menunjukkan bahwa menegakkan keberpihakan monotonik yang keras memungkinkan TT yang kuat, yang menggeneralisasi untuk ucapan yang lama, dan menggunakan aliran generatif memungkinkan sintesis ucapan yang cepat, beragam, dan terkendali. GLOW-TTS memperoleh kecepatan-up-of-magnitude di atas model autoregresif, Tacotron 2, pada sintesis dengan kualitas bicara yang sebanding. Kami selanjutnya menunjukkan bahwa model kami dapat dengan mudah diperluas ke pengaturan multi-speaker.
Kunjungi demo kami untuk sampel audio.
Kami juga menyediakan model pretrained.
| Glow-tts saat pelatihan | Glow-tts saat inferensi |
|---|---|
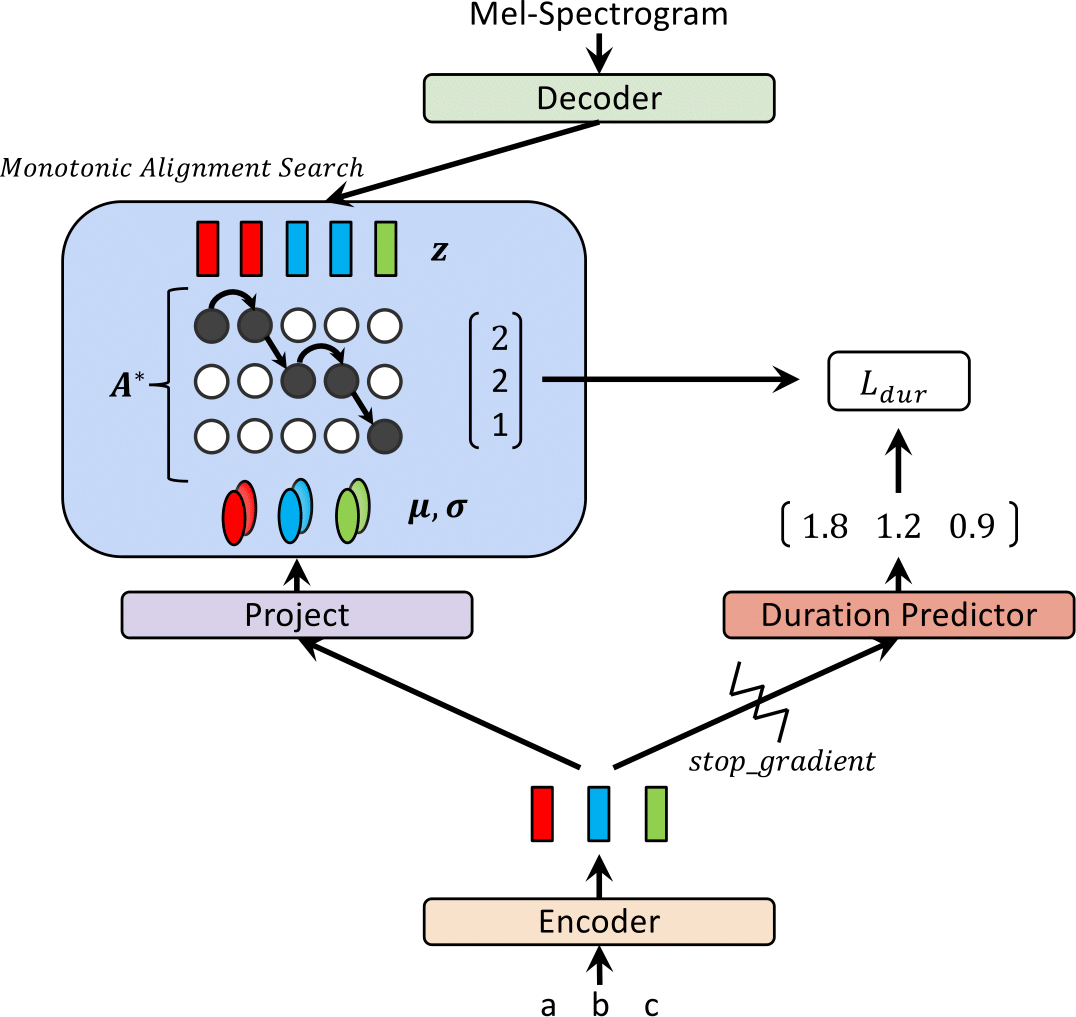 | 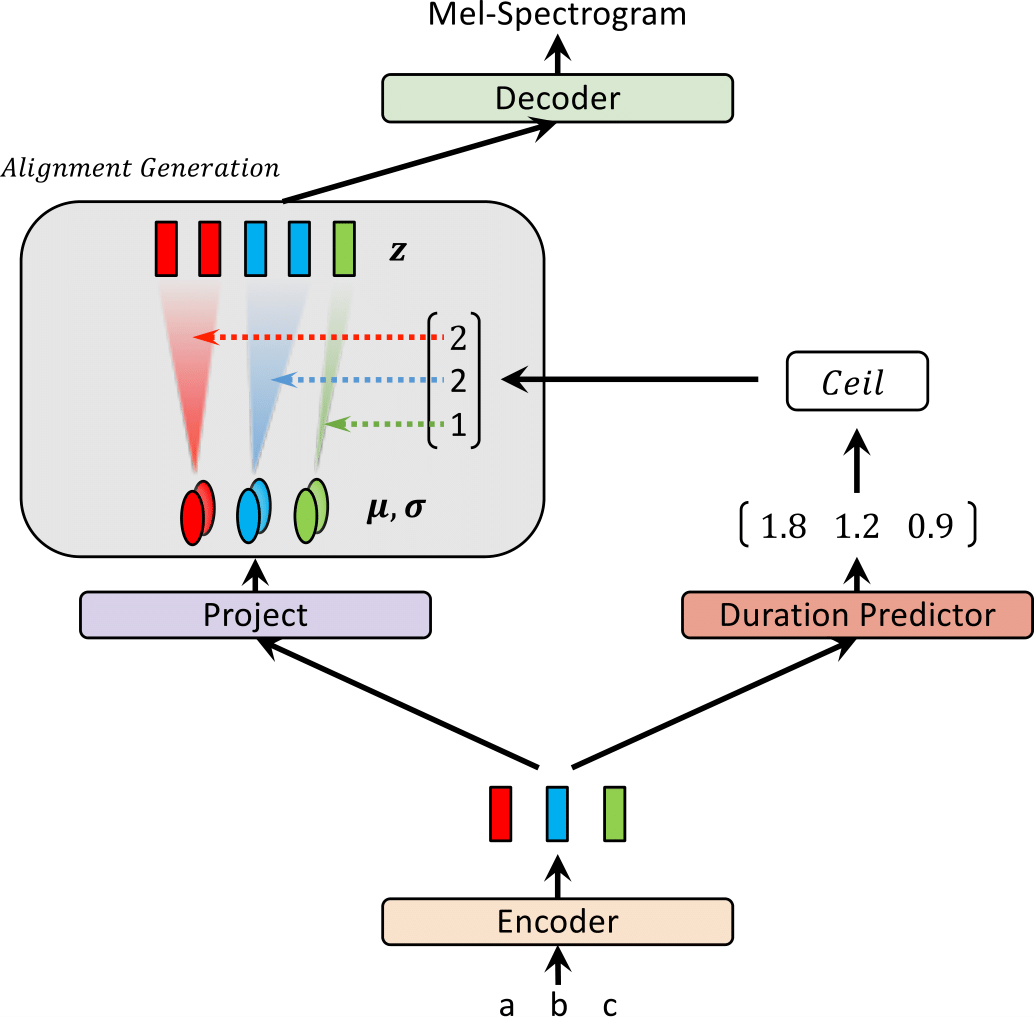 |
Hasil ini tidak termasuk dalam kertas. Akhir-akhir ini, kami menemukan bahwa dua modifikasi membantu meningkatkan kualitas sintesis Glow-Tts; 1) Pindah ke vocoder, Hifi-gan untuk mengurangi noise, 2) menempatkan token kosong antara dua token input untuk meningkatkan pengucapan. Secara khusus, kami menggunakan vocoder yang disesuaikan dengan Tacotron 2 yang disediakan sebagai model pretrained dalam repo HiFi-Gan. Jika Anda tertarik, dengarkan sampel di demo kami.
Untuk menambahkan token kosong, kami menyediakan file konfigurasi dan model pretrained. Kami juga memberikan contoh inferensi inferensi_hifigan.ipynb. Anda mungkin perlu menginisialisasi submodule hifi: git submodule init; git submodule update
Untuk pelatihan presisi campuran, kami menggunakan APEX; Komit: 37CDAF4
a) Unduh dan ekstrak dataset LJ Speech, lalu ganti nama atau buat tautan ke folder dataset: ln -s /path/to/LJSpeech-1.1/wavs DUMMY
b) Inisialisasi Submodule Waveglow: git submodule init; git submodule update
Jangan lupa untuk mengunduh model Waveglow pretrained dan menempatkannya ke folder Waveglow.
c) Membangun Kode Pencarian Alignment Monotonik (Cython): cd monotonic_align; python setup.py build_ext --inplace
sh train_ddi.sh configs/base.json baseLihat inferensi.ipynb
Implementasi kami sangat dipengaruhi oleh repo berikut:


