glow tts
1.0.0
Dans notre article récent, nous proposons GLOW-TTS: un flux génératif pour le texte à la dissection via la recherche d'alignement monotonique.
Récemment, des modèles de texte à dispection (TTS) tels que FastSpeech et Paranet ont été proposés pour générer des spectrogrammes de MEL à partir de texte en parallèle. Malgré l'avantage, les modèles TTS parallèles ne peuvent pas être formés sans guidage des modèles TTS autorégressifs comme aligneurs externes. Dans ce travail, nous proposons Glow-TTS, un modèle génératif basé sur le débit pour les TT parallèles qui ne nécessite aucun aligneur externe. En combinant les propriétés des flux et de la programmation dynamique, le modèle proposé recherche l'alignement monotonique le plus probable entre le texte et la représentation latente de la parole en soi. Nous démontrons que l'application des alignements monotoniques dures permet des TT robustes, qui se généralisent à de longues énoncés, et l'utilisation de flux génératifs permet une synthèse de la parole rapide, diverse et contrôlable. Glow-TTS obtient une accélération de l'ordre de magnitude sur le modèle autorégressif, Tacotron 2, à la synthèse avec une qualité de parole comparable. Nous montrons en outre que notre modèle peut être facilement étendu à un paramètre multi-haut-parleurs.
Visitez notre démo pour des échantillons audio.
Nous fournissons également le modèle pré-entraîné.
| Glow-Tts à la formation | Glow-tts à l'inférence |
|---|---|
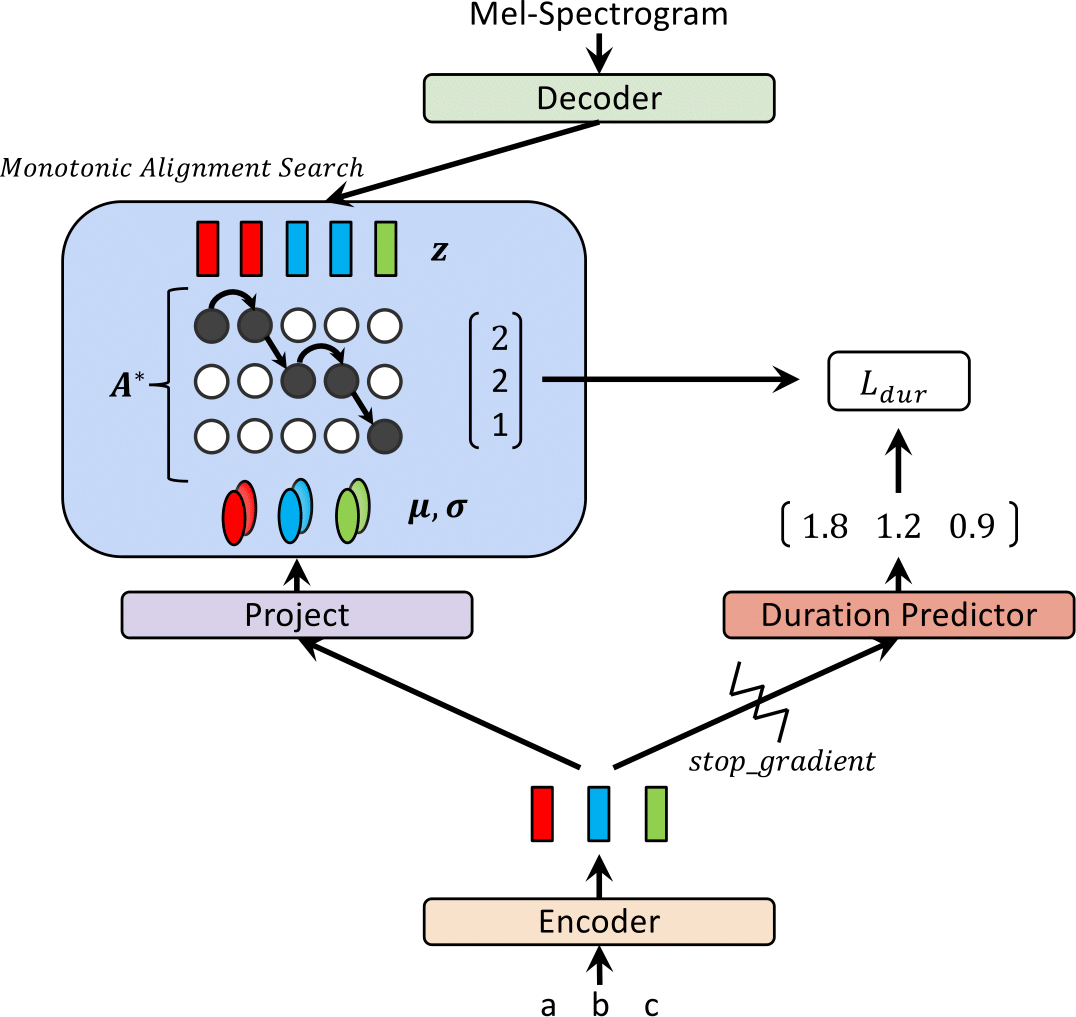 | 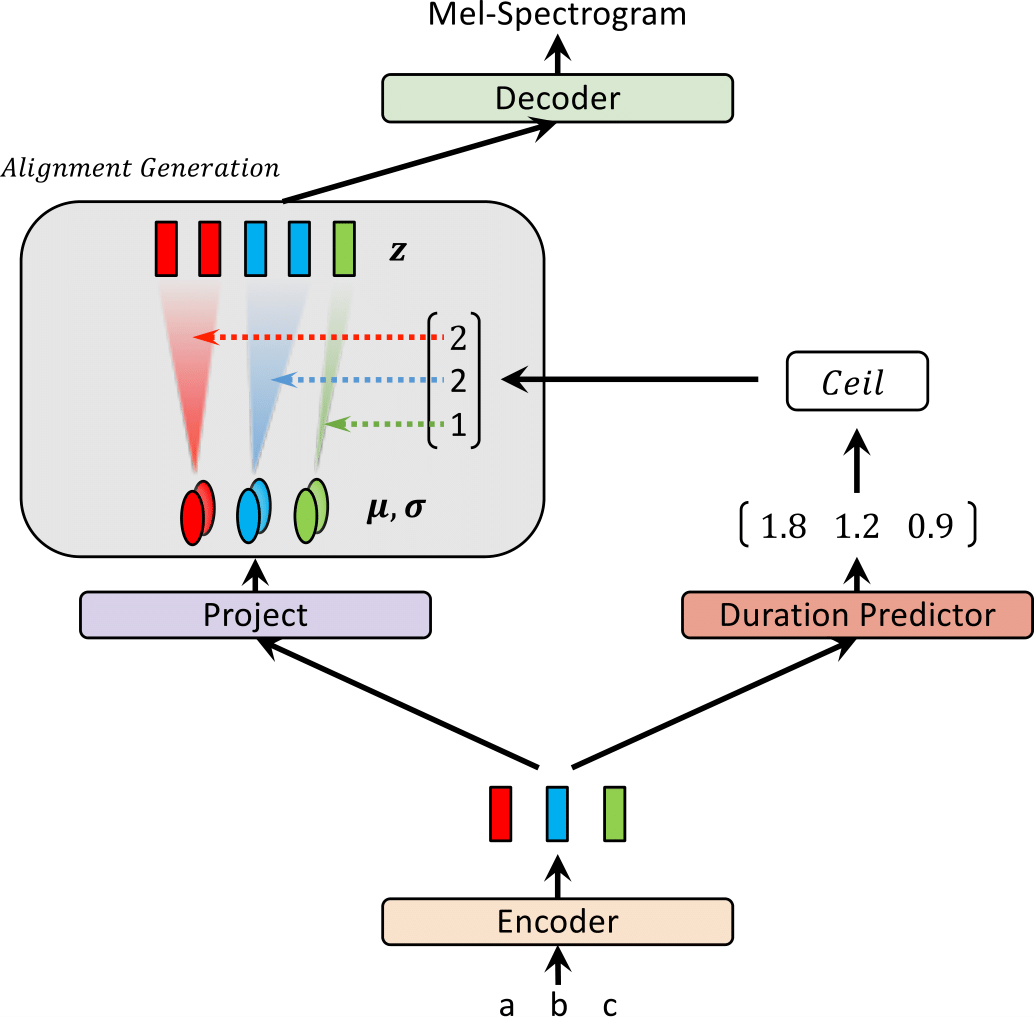 |
Ce résultat n'a pas été inclus dans le journal. Dernièrement, nous avons constaté que deux modifications aident à améliorer la qualité de synthèse de Glow-Tts.; 1) Se déplaçant vers un vocodeur, Hifi-Gan pour réduire le bruit, 2) mettant un jeton vide entre deux jetons d'entrée pour améliorer la prononciation. Plus précisément, nous avons utilisé un vocodeur affiné avec le tacotron 2 qui est fourni comme modèle pré-entraîné dans le référentiel HIFI-GAN. Si vous êtes intéressé, écoutez les échantillons dans notre démo.
Pour ajouter un jeton vide, nous fournissons un fichier de configuration et un modèle pré-entraîné. Nous fournissons également un exemple d'inférence Inference_Hifigan.ipynb. Vous devrez peut-être initialiser le sous-module HIFI-GAN: git submodule init; git submodule update
Pour une formation de précision mixte, nous utilisons Apex; commit: 37cdaf4
a) Télécharger et extraire l'ensemble de données LJ Speech, puis renommer ou créer un lien vers le dossier de l'ensemble de données: ln -s /path/to/LJSpeech-1.1/wavs DUMMY
b) Initialiser le sous-module d'éclairage d'onde: git submodule init; git submodule update
N'oubliez pas de télécharger le modèle de luminaire prétrainé et de le placer dans le dossier des éclats d'onde.
C) COILLER CODE DE RECHERCHE D'ALIGNAGE MONOTONIQUE (CYTHON): cd monotonic_align; python setup.py build_ext --inplace
sh train_ddi.sh configs/base.json baseVoir inférence.Ipynb
Notre mise en œuvre est extrêmement influencée par les références suivantes:


