glow tts
1.0.0
Em nosso artigo recente, propomos GLOW-TTS: um fluxo generativo para a fala em fala através da pesquisa de alinhamento monotônico.
Recentemente, modelos de texto para fala (TTS), como FastSpeech e Paranet, foram propostos para gerar espectrogramas MEL a partir do texto em paralelo. Apesar da vantagem, os modelos TTS paralelos não podem ser treinados sem orientação de modelos de TTS autoregressivos como alinhadores externos. Neste trabalho, propomos GLOW-TTS, um modelo generativo baseado em fluxo para TTS paralelo que não requer nenhum alinhador externo. Ao combinar as propriedades dos fluxos e a programação dinâmica, o modelo proposto procura o alinhamento monotônico mais provável entre o texto e a representação latente da fala por conta própria. Demonstramos que a aplicação de alinhamentos monotônicos difíceis permite TTS robustos, que generalizam para enredos longos, e o emprego de fluxos generativos permite a síntese de fala rápida, diversa e controlável. O GLOW-TTS obtém uma aceleração da ordem de magnitude sobre o modelo autoregressivo, o Tacotron 2, na síntese com a qualidade comparável da fala. Mostramos ainda que nosso modelo pode ser facilmente estendido a uma configuração de vários falantes.
Visite nossa demonstração para amostras de áudio.
Também fornecemos o modelo pré -treinado.
| Glow-tts no treinamento | Brilho-tts em inferência |
|---|---|
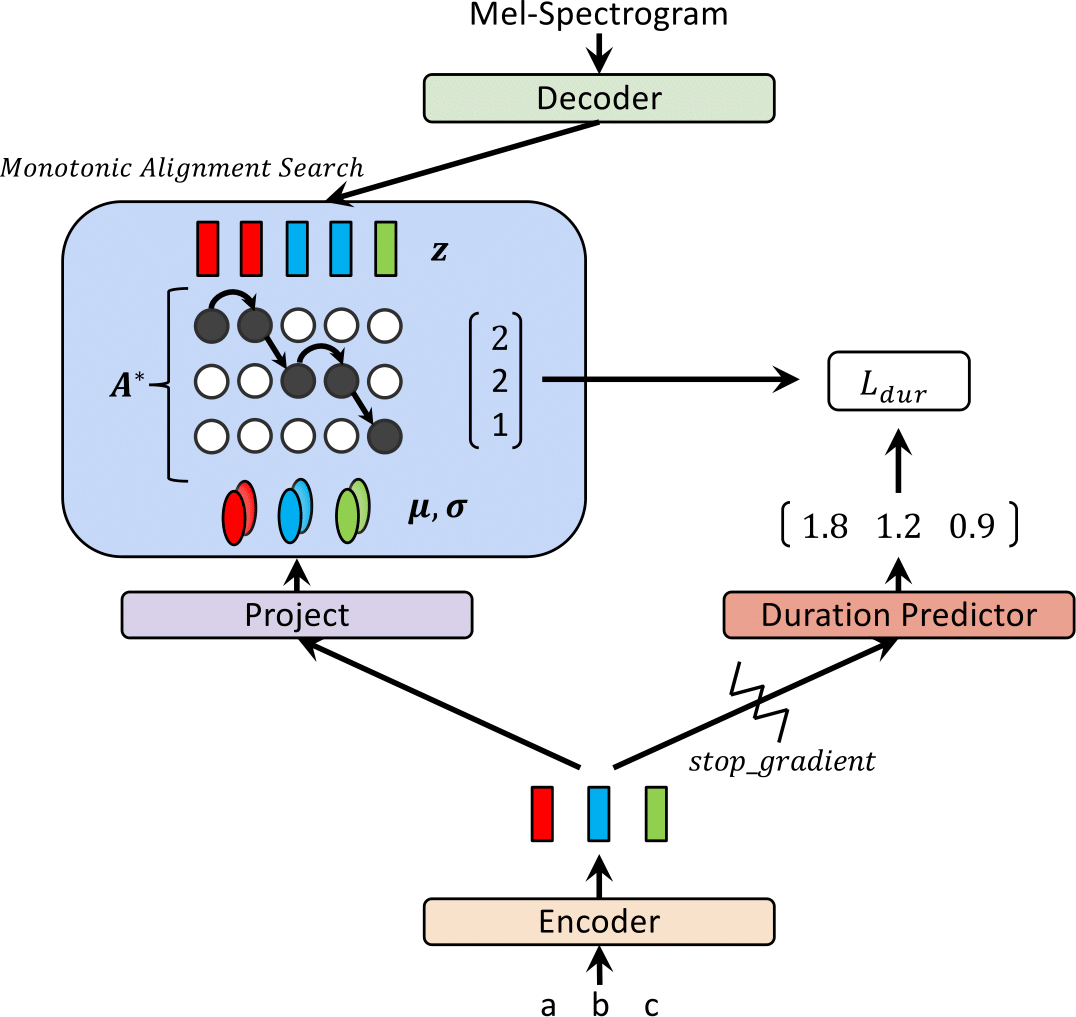 | 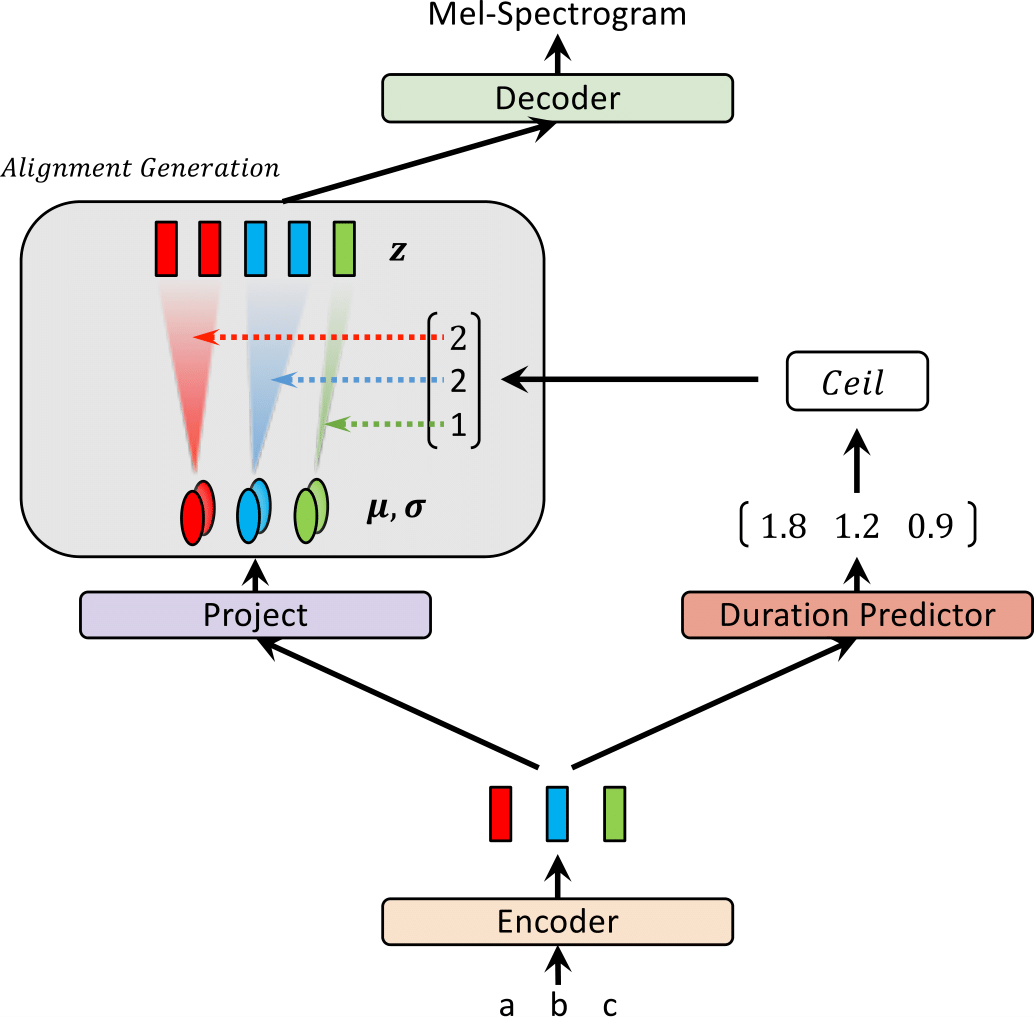 |
Este resultado não foi incluído no artigo. Ultimamente, descobrimos que duas modificações ajudam a melhorar a qualidade da síntese do Glow-TTS.; 1) Movendo-se para um vocoder, Hifi-Gan para reduzir o ruído, 2) colocando um token em branco entre quaisquer dois tokens de entrada para melhorar a pronúncia. Especificamente, usamos um vocoder de ajuste fino com o Tacotron 2, que é fornecido como um modelo pré-treinado no repositório HIFI-GAN. Se você estiver interessado, ouça as amostras em nossa demonstração.
Para adicionar um token em branco, fornecemos um arquivo de configuração e um modelo pré -traido. Também fornecemos um exemplo de inferência inference_hifigan.ipynb. Pode ser necessário inicializar o submódulo HIFI-GAN: git submodule init; git submodule update
Para treinamento de precisão mista, usamos o Apex; Compromisso: 37CDAF4
a) Faça o download e extraia o conjunto de dados de discursos LJ, depois renomeie ou crie um link para a pasta do conjunto de dados: ln -s /path/to/LJSpeech-1.1/wavs DUMMY
b) Inicialize o submódulo Waveglow: git submodule init; git submodule update
Não se esqueça de baixar o modelo de glow de onda pré -treinado e colocá -lo na pasta Waveglow.
c) Construir código de pesquisa de alinhamento monotônico (CYTHON): cd monotonic_align; python setup.py build_ext --inplace
sh train_ddi.sh configs/base.json baseVeja inference.ipynb
Nossa implementação é extremamente influenciada pelos seguintes repositórios:


