glow tts
1.0.0
最近の論文では、Glow-TTSを提案します。単調なアライメント検索を介したテキストからスピーチの生成フローです。
最近、FastSpeechやParanetなどのテキストからスピーチ(TTS)モデルが提案されており、テキストからMELスペクトルグラムを並行して生成しています。利点にもかかわらず、並列TTSモデルは、外部アライナーとしての自己回帰TTSモデルからのガイダンスなしではトレーニングすることはできません。この作業では、外部アライナーを必要としない並列TTSのフローベースの生成モデルであるGlow-TTSを提案します。フローと動的プログラミングの特性を組み合わせることにより、提案されたモデルは、テキストとそれ自体で音声の潜在的な表現との間の最も可能性の高い単調アライメントを検索します。硬い単調アライメントを強制することにより、長い発話に一般化する堅牢なTTSが可能になり、生成フローを使用することにより、高速で多様で制御可能な音声合成が可能になることを実証します。 Glow-TTSは、同等の音声品質を備えた合成時に、自己回帰モデルであるTacotron 2にわたってマグニチュードのスピードアップを取得します。さらに、モデルをマルチスピーカー設定に簡単に拡張できることを示します。
オーディオサンプルについては、デモにアクセスしてください。
また、事前に保護されたモデルを提供します。
| トレーニングでグラウツ | 推論時のglow-tt |
|---|---|
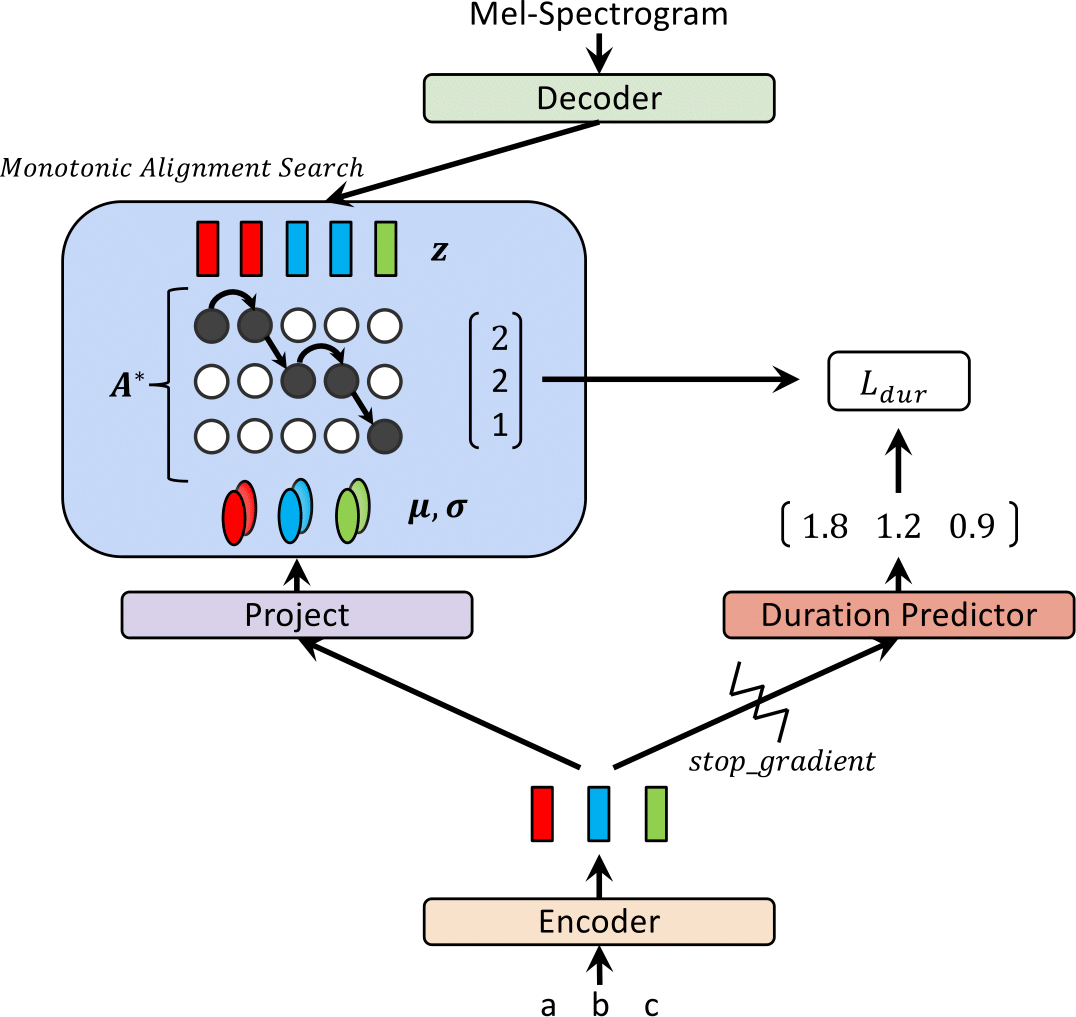 | 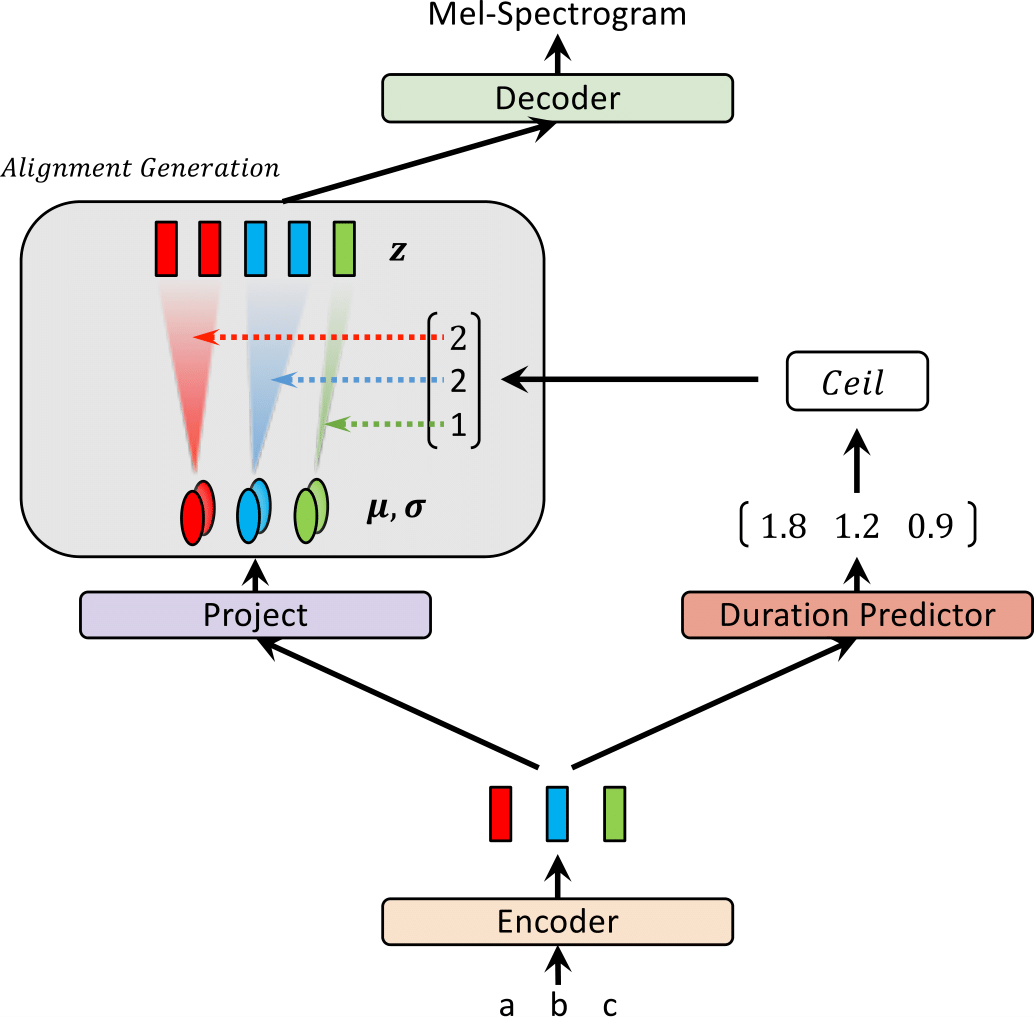 |
この結果は論文に含まれていませんでした。最近、2つの修正がGlow-TTSの合成品質を改善するのに役立つことがわかりました。 1)ボコーダーに移動するHifi-Ganはノイズを減らし、2)任意の2つの入力トークンの間に空白のトークンを置いて発音を改善します。具体的には、Hifi-Ganリポジトリの前提型モデルとして提供されるタコトロン2を備えた微調整されたボコーダーを使用しました。興味がある場合は、デモのサンプルを聞いてください。
空白のトークンを追加するために、構成ファイルと前処理されたモデルを提供します。また、推論の例inference_hifigan.ipynbも提供します。 Hifi-Ganサブモジュールを初期化する必要がある場合があります: git submodule init; git submodule update
混合精度トレーニングには、頂点を使用します。コミット:37CDAF4
a)LJスピーチデータセットをダウンロードして抽出し、データセットフォルダーへのリンクを変更または作成します: ln -s /path/to/LJSpeech-1.1/wavs DUMMY
b)波動グローのサブモジュールを初期化: git submodule init; git submodule update
前提条件のWaveglowモデルをダウンロードして、WaveGlowフォルダーに配置することを忘れないでください。
c)単調アライメント検索コード(CYTHON)を構築する: cd monotonic_align; python setup.py build_ext --inplace
sh train_ddi.sh configs/base.json baseInference.ipynbを参照してください
私たちの実装は、次のリポジトリの影響を大きく受けています。


