tf_multispeakerTTS_fc
1.0.0
这是从纸张验证到多言扬声器语音综合,深层转移和反馈约束的深层传输的纸张tts网络的张量实现。该存储库还包含一个深扬声器验证模型,该模型在多演讲者TTS模型中用作反馈网络。合成样品在线提供。
@inproceedings{Cai2020,
author={Zexin Cai and Chuxiong Zhang and Ming Li},
title={{From Speaker Verification to Multispeaker Speech Synthesis, Deep Transfer with Feedback Constraint}},
year=2020,
booktitle={Proc. Interspeech 2020}
}
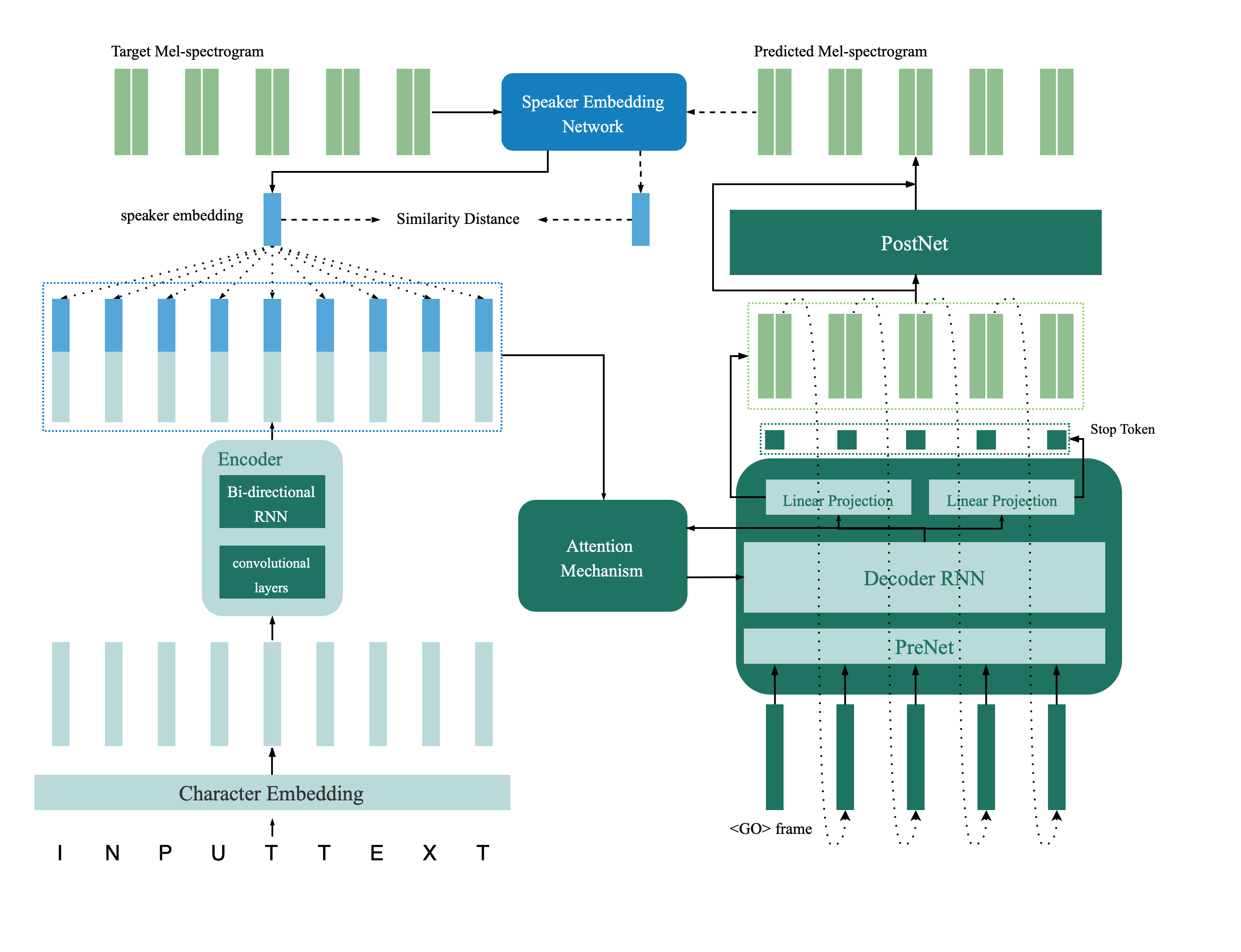
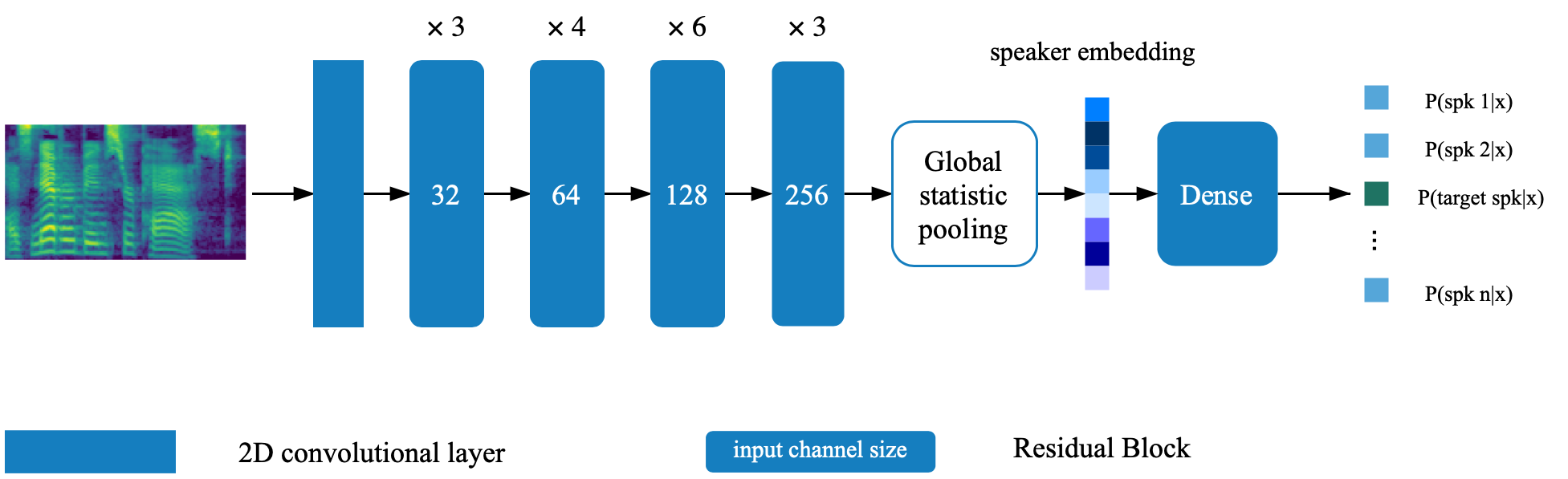
扬声器验证模型位于目录deep_speaker中。默认情况下,使用Data Voxceleb 1和Voxceleb 2进行了扬声器验证模型。您可以在目录中找到文件列表。超参数设置在vox12_hparams.py中。
要训练扬声器verificaiton模型从头开始,请按文件列表中列出的数据进行准备并运行:
CUDA_VISIBLE_DEVICES=0 python train.py默认情况下,使用数据集VCTK对合成器进行了训练。
使用process_audio.ipynb提取音频功能
使用ipython笔记本deep_speaker/get_gvector.ipynb提取扬声器嵌入
训练基线多孔TTS系统
CUDA_VISIBLE_DEVICES=0 python synthesizer_train.py vctk datasets/vctk/synthesizer在训练期间,请随时使用Syn.ipynb评估和合成样品
默认情况下,还使用DataSet VCTK对Vocoder进行了训练。从上一节( TTS合成器)中提取声学特征后,这将很容易。为了获得更好的性能,请使用合成器训练完成后Vocoder_preprocess.py获得的GTA MEL-SPECTROGRAM。
CUDA_VISIBLE_DEVICES=0 python vocoder_train.py -g --syn_dir datasets/vctk/synthesizer vctk datasets/vctk通过更改HPARAMS.PY中的相应键来设置两个预验证模型(扬声器验证模型和多座式合成器)的路径。
训练模型并随时用反馈_syn.ipynb进行评估
CUDA_VISIBLE_DEVICES=0 python fc_synthesizer_train.py

