tf_multispeakerTTS_fc
1.0.0
이것은 스피커 검증에서 멀티 스피커 음성 합성에 이르기까지 종이에 소개 된 멀티 스피커 TTS 네트워크의 텐서 플로 구현, 피드백 제약 조건으로 깊은 전송입니다. 이 저장소에는 피드백 네트워크로서 멀티 스피커 TTS 모델에서 사용되는 딥 스피커 검증 모델도 포함되어 있습니다. 합성 된 샘플은 온라인으로 제공됩니다.
@inproceedings{Cai2020,
author={Zexin Cai and Chuxiong Zhang and Ming Li},
title={{From Speaker Verification to Multispeaker Speech Synthesis, Deep Transfer with Feedback Constraint}},
year=2020,
booktitle={Proc. Interspeech 2020}
}
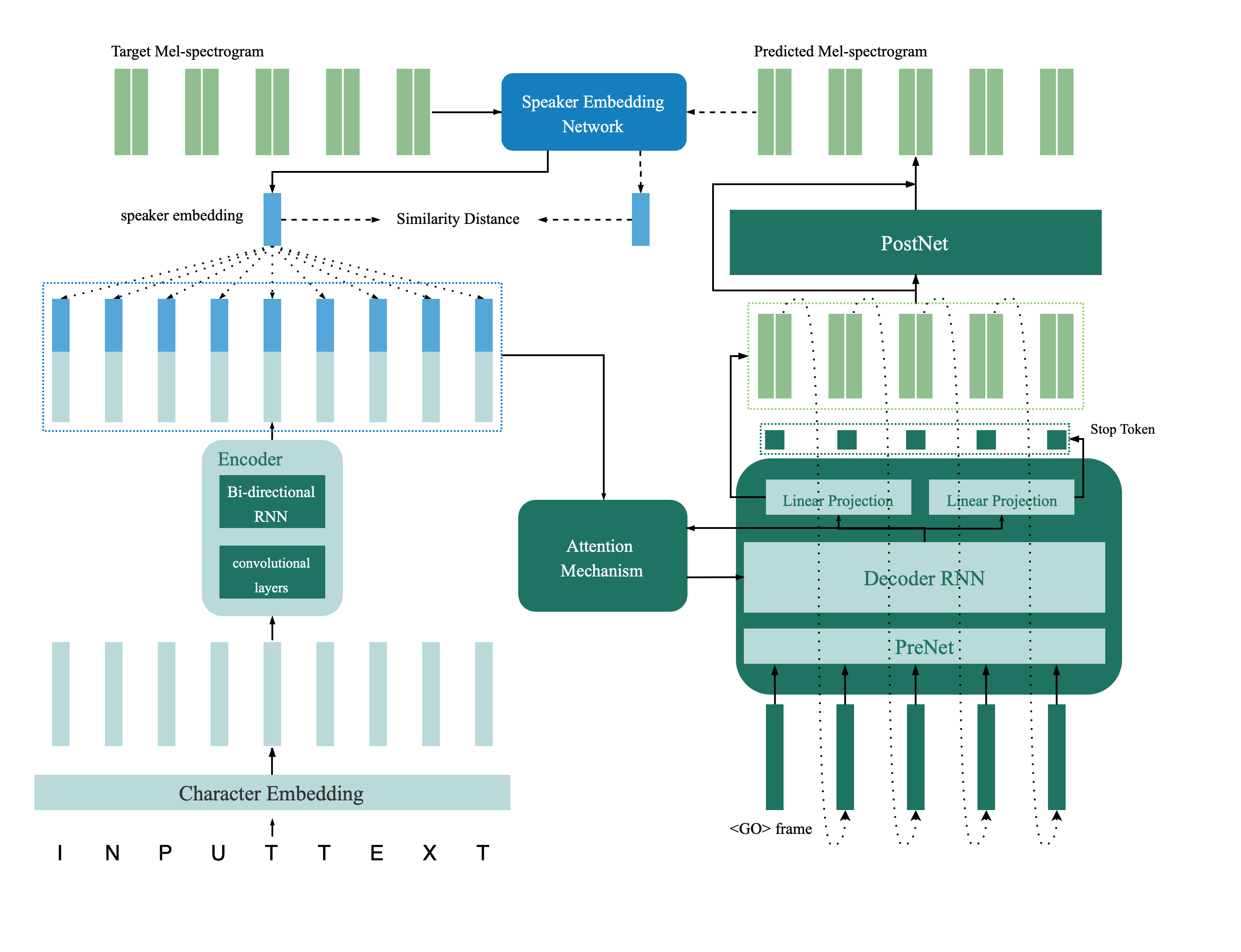
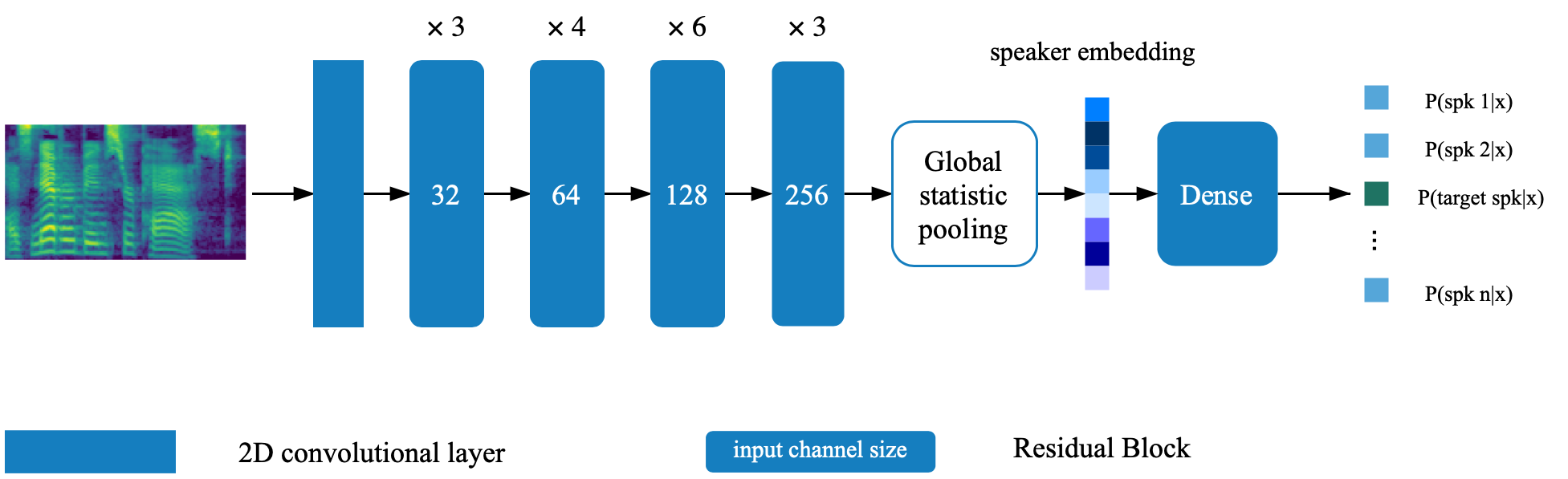
스피커 확인 모델은 Directory Deep_Speaker에 있습니다. 기본적으로 스피커 검증 모델은 Data Voxceleb 1 및 VoxcelEB 2로 교육을받습니다. 디렉토리에서 파일 목록을 찾을 수 있습니다. 하이퍼 파라미터는 vox12_hparams.py로 설정됩니다.
스피커 인 Verificaiton 모델을 처음부터 훈련 시키려면 파일 목록에 나열된 데이터를 준비하고 실행하십시오.
CUDA_VISIBLE_DEVICES=0 python train.py기본적으로 신디사이저는 데이터 세트 VCTK를 사용하여 교육을받습니다.
process_audio.ipynb를 사용하여 오디오 기능을 추출합니다
ipython 노트북 Deep_speaker/get_gvector.ipynb를 사용한 스피커 임베딩 추출
기본 멀티 스피커 TTS 시스템을 훈련하십시오
CUDA_VISIBLE_DEVICES=0 python synthesizer_train.py vctk datasets/vctk/synthesizer훈련 중에 syn.ipynb를 사용하여 샘플을 평가하고 합성하십시오.
기본적으로 보코더는 DataSet VCTK를 사용하여 교육을받습니다. 이전 섹션 ( TTS 합성기 )에서 음향 기능을 추출한 후에는 쉽습니다. 더 나은 성능을 보려면 신시사이저 훈련이 완료된 후 vocoder_preprocess.py에서 얻은 GTA Mel-spectrogram을 사용하십시오.
CUDA_VISIBLE_DEVICES=0 python vocoder_train.py -g --syn_dir datasets/vctk/synthesizer vctk datasets/vctkHPARAMS.PY에서 해당 키를 변경하여 두 개의 사전 여지가있는 모델 (스피커 검증 모델 및 멀티 스피커 합성기)으로 경로를 설정하십시오.
피드백 _syn.ipynb로 모델을 훈련시키고 언제든지 평가하십시오
CUDA_VISIBLE_DEVICES=0 python fc_synthesizer_train.py

