tf_multispeakerTTS_fc
1.0.0
هذا هو تطبيق Tensorflow لشبكة TTS متعددة الأدوات التي تم تقديمها في الورق من التحقق من السماعات إلى تخليق الكلام متعدد النطاقات ، ونقل عميق مع قيود التعليقات. يحتوي هذا المستودع أيضًا على نموذج التحقق من مكبر الصوت العميق الذي يتم استخدامه في نموذج TTS متعدد الناطقين كشبكة التغذية المرتدة. يتم توفير عينات توليف عبر الإنترنت.
@inproceedings{Cai2020,
author={Zexin Cai and Chuxiong Zhang and Ming Li},
title={{From Speaker Verification to Multispeaker Speech Synthesis, Deep Transfer with Feedback Constraint}},
year=2020,
booktitle={Proc. Interspeech 2020}
}
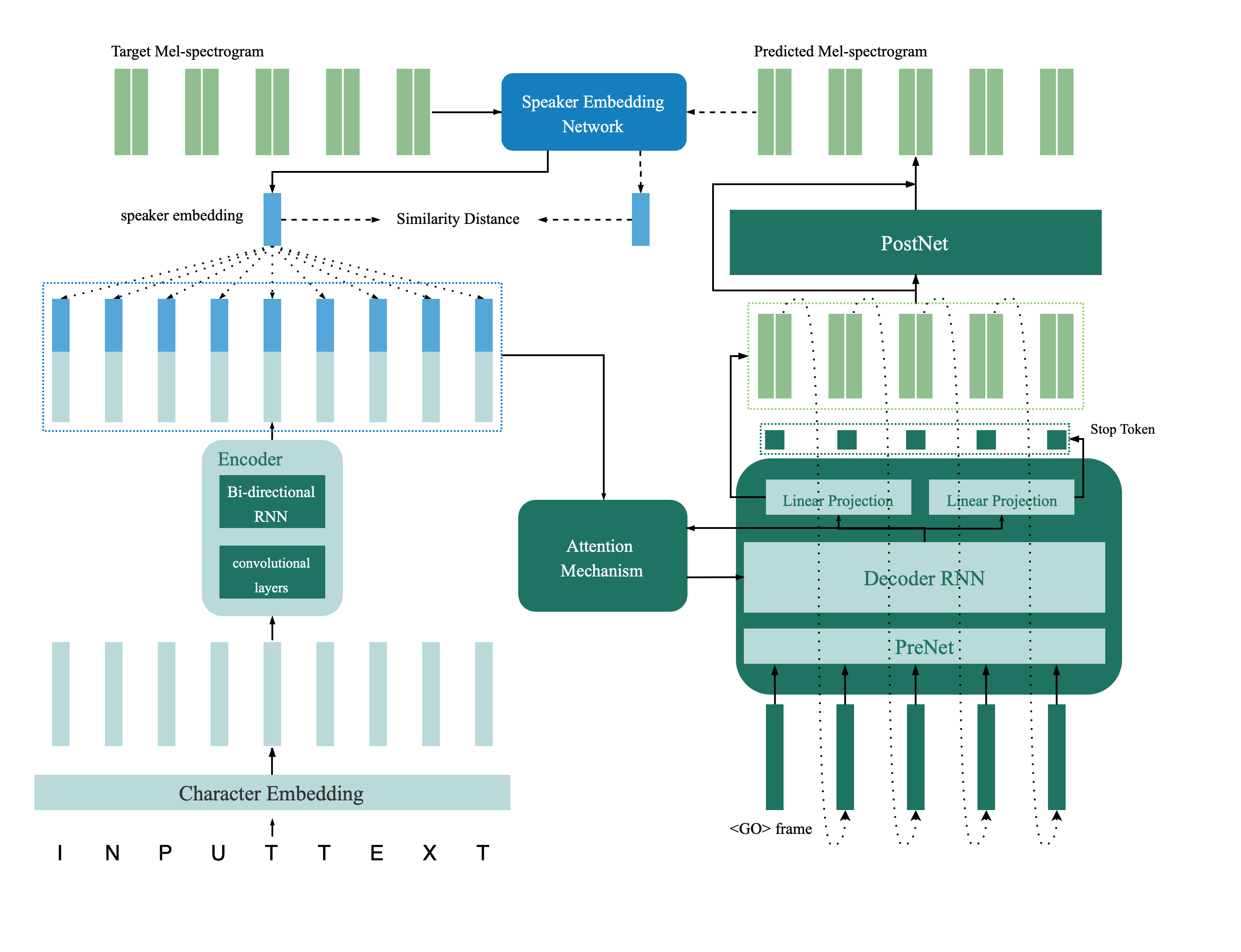
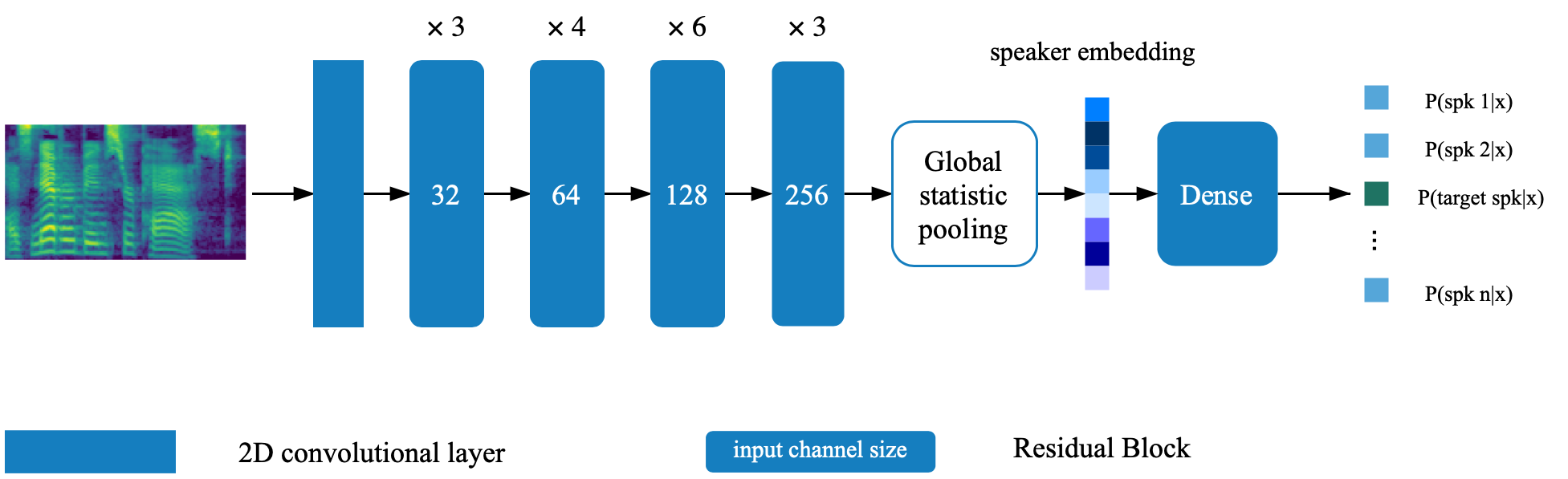
يقع نموذج التحقق من السماعة في Directory Deep_Speaker. بشكل افتراضي ، يتم تدريب نموذج التحقق من السماعات باستخدام Data Voxceleb 1 و Voxceleb 2. يمكنك العثور على قائمة الملفات في الدليل. يتم تعيين Hyperparameters في Vox12_hparams.py.
لتدريب نموذج المتحدث الواقعي من نقطة الصفر ، قم بإعداد البيانات كما هو مدرج في قائمة الملفات وتشغيلها:
CUDA_VISIBLE_DEVICES=0 python train.pyبشكل افتراضي ، يتم تدريب Synthesizer باستخدام مجموعة البيانات VCTK.
استخراج ميزة الصوت باستخدام process_audio.ipynb
استخراج التضمينات مكبر الصوت باستخدام ipython Notebook deep_speaker/get_gvector.ipynb
قم بتدريب نظام TTS الأساسي Multispeaker
CUDA_VISIBLE_DEVICES=0 python synthesizer_train.py vctk datasets/vctk/synthesizerلا تتردد في تقييم العينات وتوليفها باستخدام syn.ipynb أثناء التدريب
بشكل افتراضي ، يتم تدريب Vocoder أيضًا باستخدام DataSet VCTK. سيكون الأمر سهلاً بعد أن يكون لديك الميزة الصوتية المستخرجة من القسم السابق ( TTS Clothesizer ). للحصول على أداء أفضل ، يرجى استخدام GTA MEL-SPECTROMBER التي تم الحصول عليها بواسطة vocoder_preprocess.py بعد الانتهاء من تدريب المزج.
CUDA_VISIBLE_DEVICES=0 python vocoder_train.py -g --syn_dir datasets/vctk/synthesizer vctk datasets/vctkاضبط المسار على النموذجين المسبق (نموذج التحقق من السماعات ومزج ملزم Multispeaker) عن طريق تغيير المفاتيح المقابلة في HParams.py.
تدريب النموذج وتقييمه في أي وقت باستخدام Feedback_syn.ipynb
CUDA_VISIBLE_DEVICES=0 python fc_synthesizer_train.py

