tf_multispeakerTTS_fc
1.0.0
Esta é uma implementação do TensorFlow da rede TTS multispicoy introduzida em papel, desde a verificação do alto -falante até a síntese de fala multispicot, a transferência profunda com a restrição de feedback. Esse repositório também contém um modelo de verificação de alto-falante profundo que é usado no modelo TTS de vários falantes como rede de feedback. Amostras sintetizadas são fornecidas online.
@inproceedings{Cai2020,
author={Zexin Cai and Chuxiong Zhang and Ming Li},
title={{From Speaker Verification to Multispeaker Speech Synthesis, Deep Transfer with Feedback Constraint}},
year=2020,
booktitle={Proc. Interspeech 2020}
}
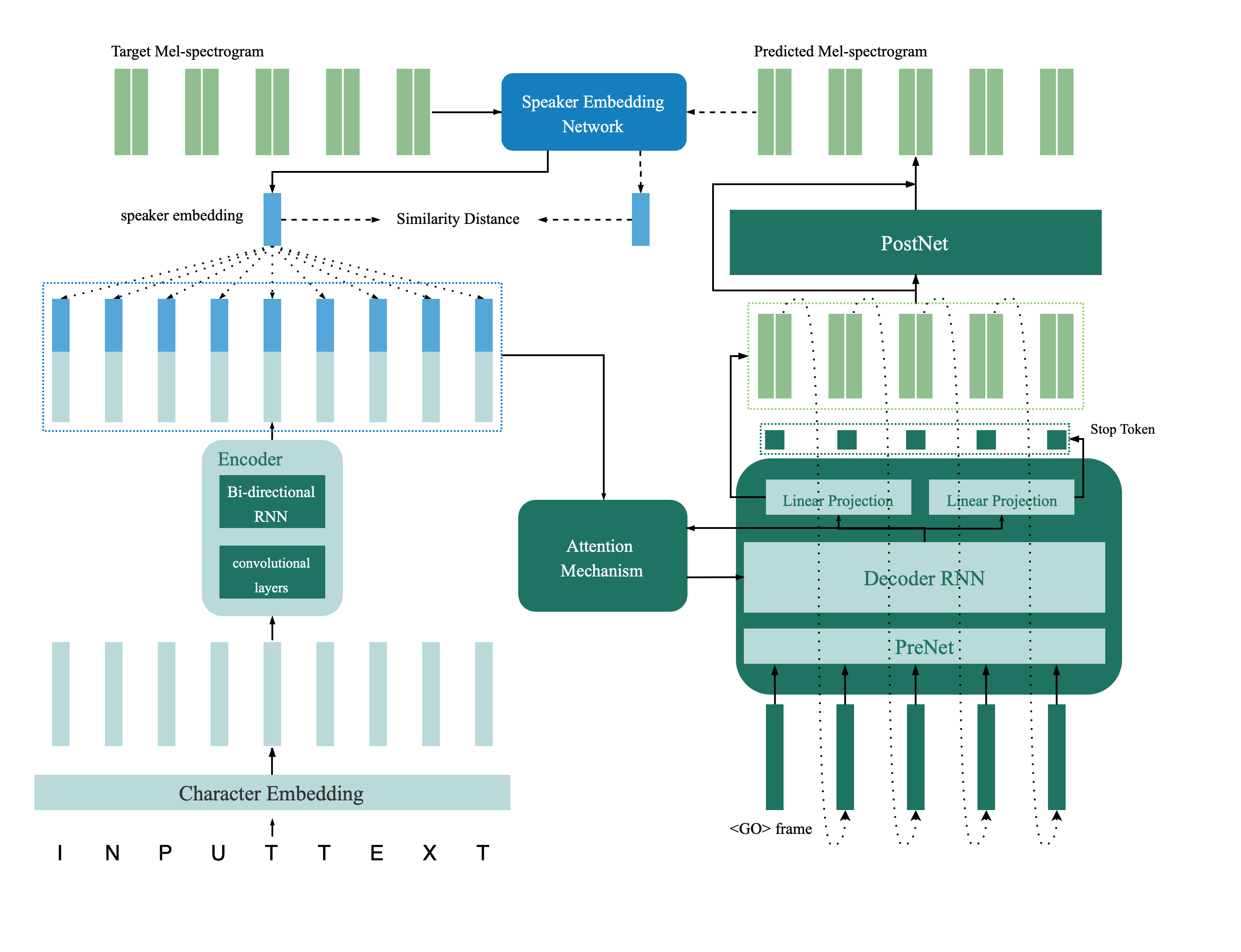
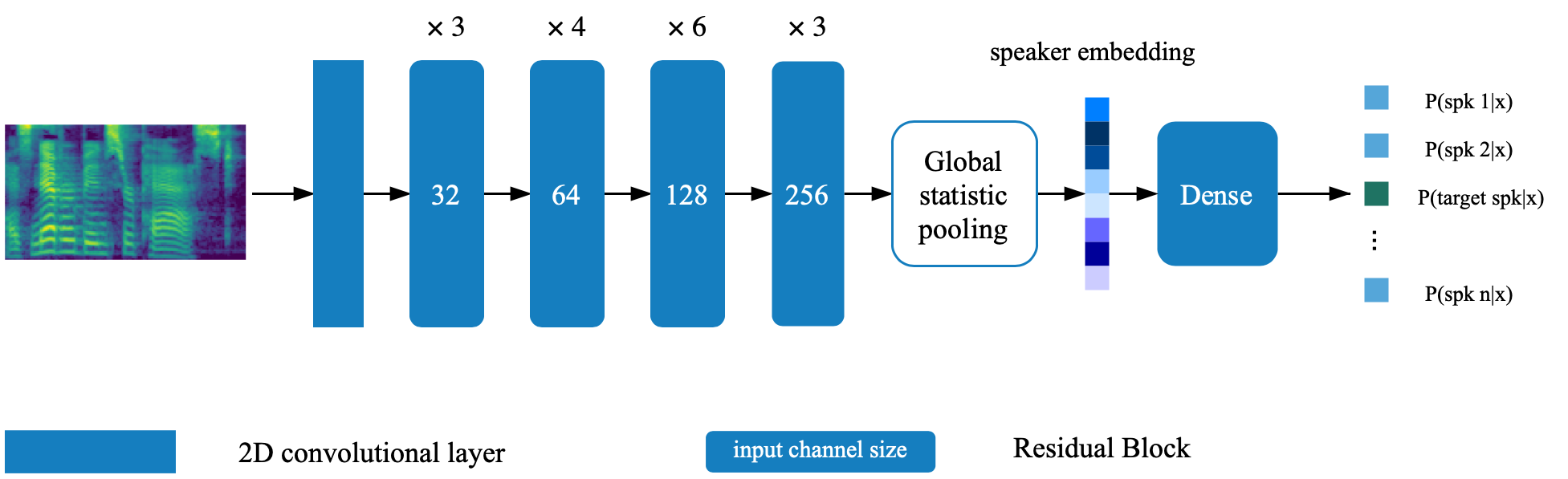
O modelo de verificação do alto -falante está localizado no diretório Deep_Speaker. Por configuração padrão, o modelo de verificação do alto -falante é treinado com dados voxceleb 1 e voxceleb 2. Você pode encontrar a lista de arquivos no diretório. Os hyperparameters são definidos em Vox12_Hparams.py.
Para treinar o modelo do alto -falante Verificiton do zero, prepare os dados listados na lista de arquivos e execute:
CUDA_VISIBLE_DEVICES=0 python train.pyPor configuração padrão, o sintetizador é treinado usando o conjunto de dados VCTK.
Extrair recurso de áudio usando process_audio.ipynb
Extrair incorporações de alto -falante usando o notebook ipython Deep_speaker/get_gvector.ipynb
Treine um sistema TTS multispicoker de linha de base
CUDA_VISIBLE_DEVICES=0 python synthesizer_train.py vctk datasets/vctk/synthesizerSinta -se à vontade para avaliar e sintetizar amostras usando syn.ipynb durante o treinamento
Por configuração padrão, o vocoder também é treinado usando o DataSet VCTK. Seria fácil depois de extrair o recurso acústico da seção anterior ( sintetizador TTS ). Para melhor desempenho, use o GTA MEL-Spectrograma obtido pelo vocoder_preprocess.py após o término do treinamento do sintetizador.
CUDA_VISIBLE_DEVICES=0 python vocoder_train.py -g --syn_dir datasets/vctk/synthesizer vctk datasets/vctkDefina o caminho para o modelo de dois pré -terem previsto (o modelo de verificação do alto -falante e o sintetizador multispicoker) alterando as teclas correspondentes em hparams.py.
Treine o modelo e avalie a qualquer momento com feedback_syn.ipynb
CUDA_VISIBLE_DEVICES=0 python fc_synthesizer_train.py

