tf_multispeakerTTS_fc
1.0.0
นี่คือการใช้งาน tensorflow ของเครือข่าย TTS Multispeaker ที่แนะนำในกระดาษจากการตรวจสอบลำโพงไปจนถึงการสังเคราะห์คำพูดหลายครั้งการถ่ายโอนลึกพร้อมข้อ จำกัด ข้อเสนอแนะ ที่เก็บนี้ยังมีรูปแบบการตรวจสอบลำโพงลึกที่ใช้ในโมเดล TTS หลายลำโพงเป็นเครือข่ายข้อเสนอแนะ ตัวอย่างสังเคราะห์มีให้ออนไลน์
@inproceedings{Cai2020,
author={Zexin Cai and Chuxiong Zhang and Ming Li},
title={{From Speaker Verification to Multispeaker Speech Synthesis, Deep Transfer with Feedback Constraint}},
year=2020,
booktitle={Proc. Interspeech 2020}
}
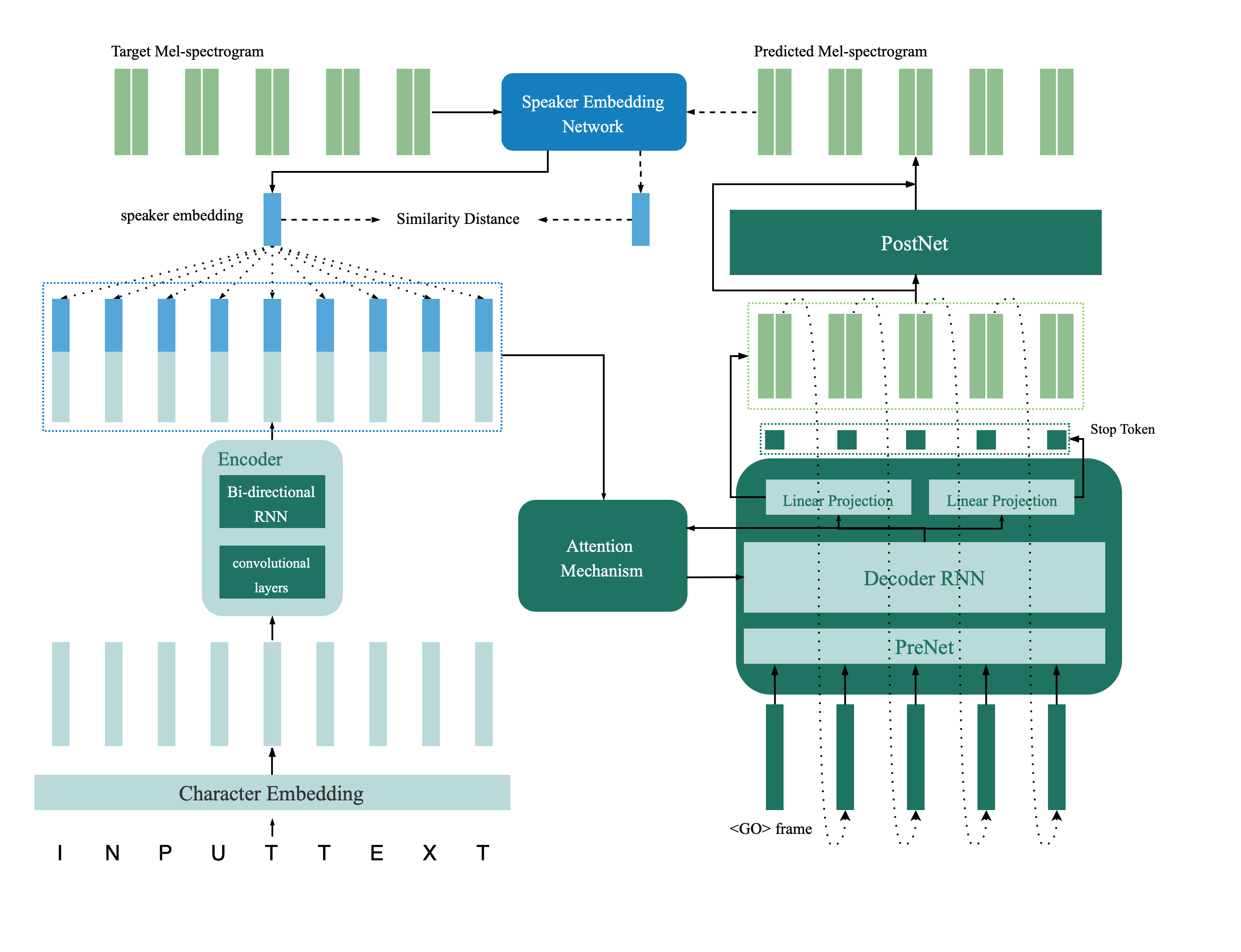
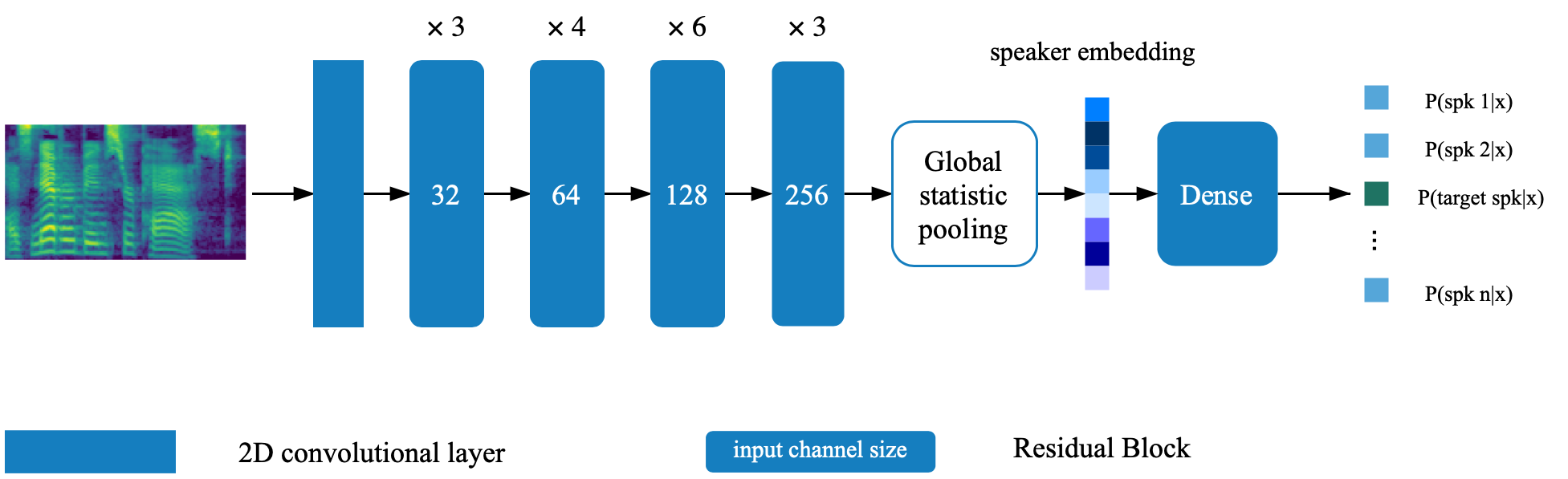
รูปแบบการตรวจสอบลำโพงตั้งอยู่ในไดเรกทอรี deep_speaker โดยการตั้งค่าเริ่มต้นรูปแบบการตรวจสอบลำโพงได้รับการฝึกฝนด้วยข้อมูล voxceleb 1 และ voxceleb 2 คุณสามารถค้นหารายการไฟล์ในไดเรกทอรี Hyperparameters ถูกตั้งค่าใน vox12_hparams.py
ในการฝึกอบรมโมเดล Verificaiton ของลำโพงตั้งแต่เริ่มต้นให้เตรียมข้อมูลตามที่ระบุไว้ในรายการไฟล์และเรียกใช้:
CUDA_VISIBLE_DEVICES=0 python train.pyโดยการตั้งค่าเริ่มต้น synthesizer ได้รับการฝึกฝนโดยใช้ชุดข้อมูล VCTK
แยกคุณสมบัติเสียงโดยใช้ process_audio.ipynb
Extract Speaker Embeddings โดยใช้ Ipython Notebook Deep_Speaker/get_gvector.ipynb
ฝึกอบรมระบบ TTS Multispeaker พื้นฐาน
CUDA_VISIBLE_DEVICES=0 python synthesizer_train.py vctk datasets/vctk/synthesizerอย่าลังเลที่จะประเมินและสังเคราะห์ตัวอย่างโดยใช้ syn.ipynb ระหว่างการฝึกอบรม
โดยการตั้งค่าเริ่มต้น Vocoder ยังได้รับการฝึกฝนโดยใช้ชุดข้อมูล VCTK มันจะง่ายหลังจากที่คุณมีคุณสมบัติอะคูสติกที่สกัดจากส่วนก่อนหน้า ( TTS synthesizer ) เพื่อประสิทธิภาพที่ดีขึ้นโปรดใช้ GTA mel-spectrogram ที่ได้รับจาก Vocoder_preprocess.py หลังจากการฝึกซ้อมซินธิไซเซอร์เสร็จสิ้น
CUDA_VISIBLE_DEVICES=0 python vocoder_train.py -g --syn_dir datasets/vctk/synthesizer vctk datasets/vctkตั้งค่าเส้นทางไปยังทั้งสองรุ่นที่ได้รับการฝึกฝน (โมเดลการตรวจสอบลำโพงและซินธิไซเซอร์แบบหลายวง) โดยการเปลี่ยนคีย์ที่เกี่ยวข้องใน hparams.py
ฝึกอบรมแบบจำลองและประเมินผลทุกเวลาด้วย feedback_syn.ipynb
CUDA_VISIBLE_DEVICES=0 python fc_synthesizer_train.py

