tf_multispeakerTTS_fc
1.0.0
Ini adalah implementasi TensorFlow dari jaringan TTS multispeaker yang diperkenalkan dalam kertas dari verifikasi speaker hingga sintesis ucapan multispeaker, transfer mendalam dengan kendala umpan balik. Repositori ini juga berisi model verifikasi speaker mendalam yang digunakan dalam model TTS multi-speaker sebagai jaringan umpan balik. Sampel yang disintesis disediakan secara online.
@inproceedings{Cai2020,
author={Zexin Cai and Chuxiong Zhang and Ming Li},
title={{From Speaker Verification to Multispeaker Speech Synthesis, Deep Transfer with Feedback Constraint}},
year=2020,
booktitle={Proc. Interspeech 2020}
}
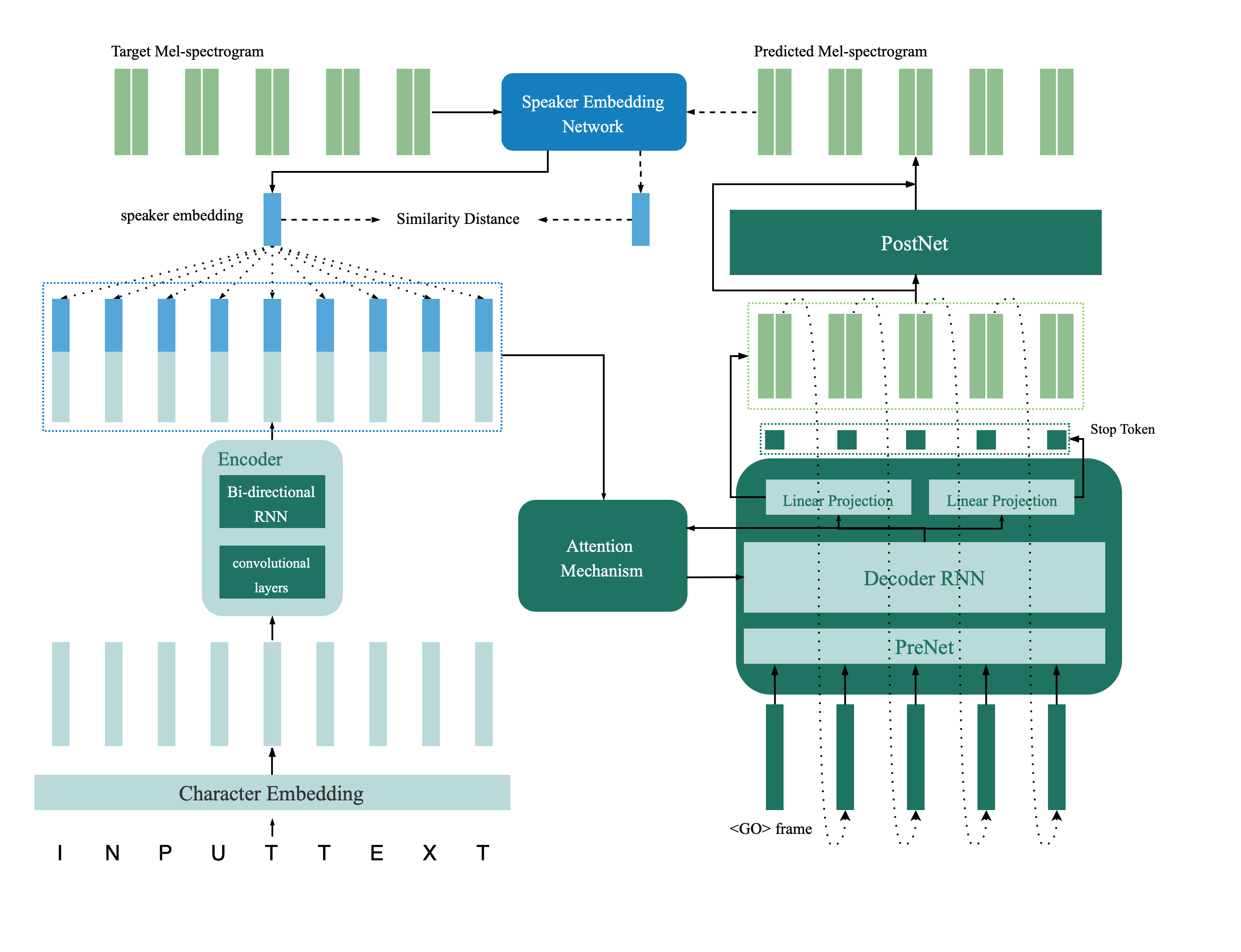
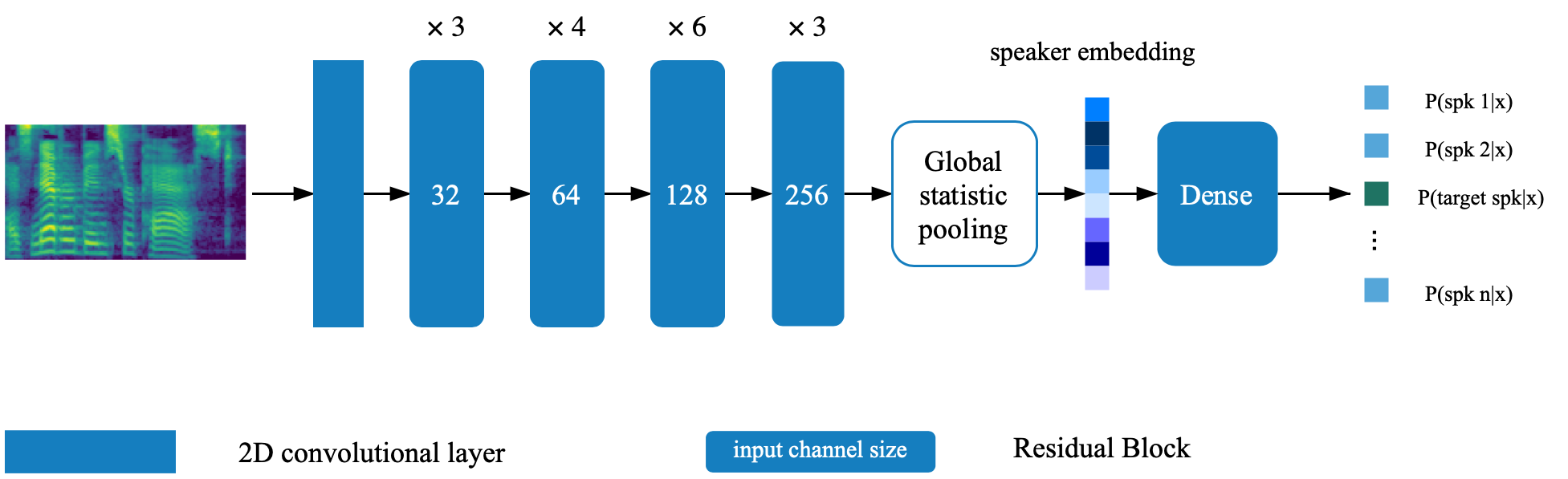
Model verifikasi speaker terletak di direktori Deep_speaker. Secara default pengaturan, model verifikasi speaker dilatih dengan data voxceleb 1 dan voxceleb 2. Anda dapat menemukan daftar file di direktori. Hyperparameters diatur dalam vox12_hparams.py.
Untuk melatih model speaker verificaiton dari awal, siapkan data seperti yang tercantum dalam daftar file dan jalankan:
CUDA_VISIBLE_DEVICES=0 python train.pySecara default pengaturan, synthesizer dilatih menggunakan dataset VCTK.
Ekstrak fitur audio menggunakan proses_audio.ipynb
Ekstrak speaker embeddings menggunakan iPython notebook Deep_speaker/get_gvector.ipynb
Latih sistem TTS Multispeaker Baseline
CUDA_VISIBLE_DEVICES=0 python synthesizer_train.py vctk datasets/vctk/synthesizerJangan ragu untuk mengevaluasi dan mensintesis sampel menggunakan syn.ipynb selama pelatihan
Secara default pengaturan, vocoder juga dilatih menggunakan dataset vctk. Akan mudah setelah Anda memiliki fitur akustik yang diekstraksi dari bagian sebelumnya ( TTS synthesizer ). Untuk kinerja yang lebih baik, silakan gunakan GTA Mel-Spectrogram yang diperoleh oleh vocoder_preprocess.py setelah pelatihan synthesizer selesai.
CUDA_VISIBLE_DEVICES=0 python vocoder_train.py -g --syn_dir datasets/vctk/synthesizer vctk datasets/vctkAtur jalur ke dua model pretrained (model verifikasi speaker dan multispeaker synthesizer) dengan mengubah tombol yang sesuai di hparams.py.
Latih model dan evaluasi kapan saja dengan feedback_syn.ipynb
CUDA_VISIBLE_DEVICES=0 python fc_synthesizer_train.py

