tf_multispeakerTTS_fc
1.0.0
Dies ist eine Tensorflow -Implementierung des Multispeaker -TTS -Netzwerks, das in Papier von der Sprecherverifizierung bis zur Multispeaker -Sprachsynthese und einer tiefen Übertragung mit Feedback -Einschränkungen eingeführt wurde. Dieses Repository enthält auch ein Deep-Lautsprecher-Verifizierungsmodell, das im TTS-Modell mit mehreren Sprechern als Feedback-Netzwerk verwendet wird. Synthetisierte Muster werden online bereitgestellt.
@inproceedings{Cai2020,
author={Zexin Cai and Chuxiong Zhang and Ming Li},
title={{From Speaker Verification to Multispeaker Speech Synthesis, Deep Transfer with Feedback Constraint}},
year=2020,
booktitle={Proc. Interspeech 2020}
}
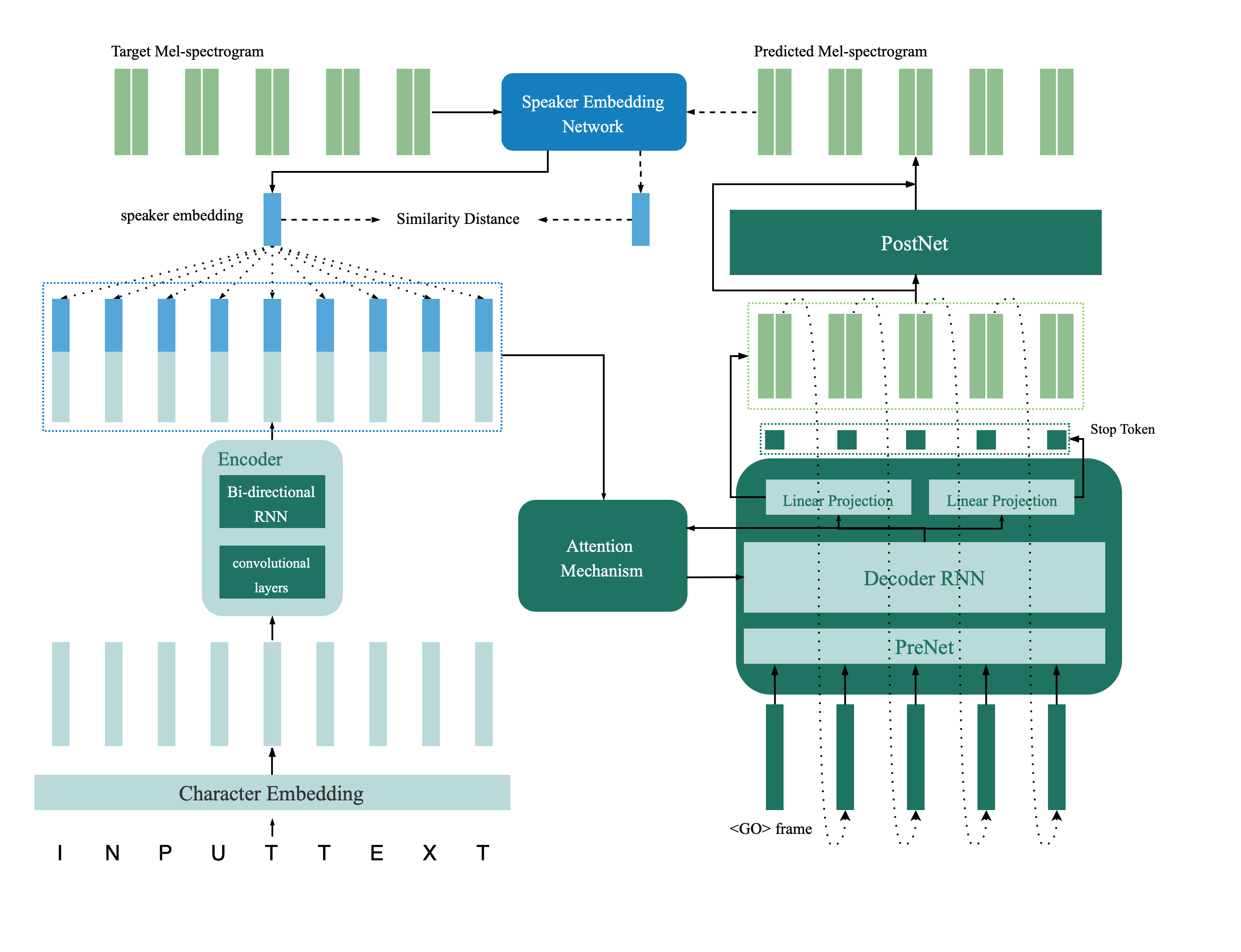
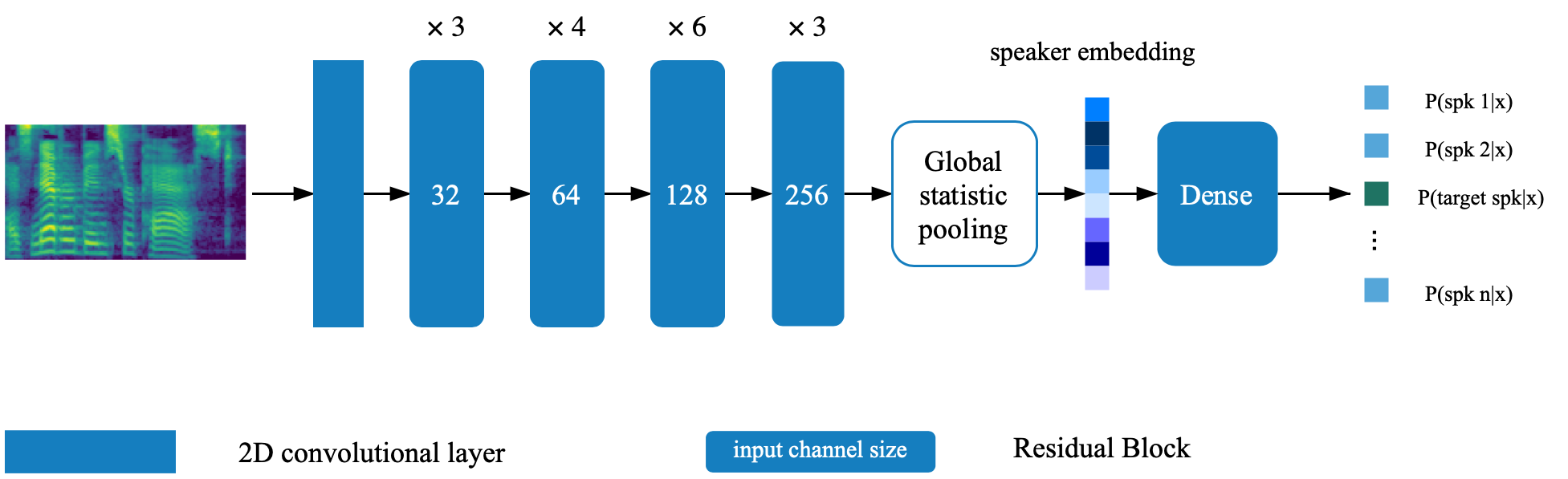
Das Lautsprecherüberprüfungsmodell befindet sich im Verzeichnis Deep_speaker. Standardmäßig wird das Lautsprecherüberprüfungsmodell mit Data voxceleb 1 und Voxceleb 2 geschult. Die Dateiliste finden Sie im Verzeichnis. Hyperparameter sind in vox12_hparams.py festgelegt.
Um das Modell des Lautsprechers Verificaiton von Grund auf neu zu trainieren, bereiten Sie die in der Dateiliste aufgeführten Daten vor und laufen Sie aus:
CUDA_VISIBLE_DEVICES=0 python train.pyStandardmäßig wird der Synthesizer mit Datensatz vctk geschult.
Extrahieren Sie die Audiofunktion mit process_audio.ipynb
Extraktlautsprecher -Einbettung mit ipython Notebook Deep_speaker/get_gVector.ipynb
Trainieren Sie ein Basis -Multispeaker -TTS -System
CUDA_VISIBLE_DEVICES=0 python synthesizer_train.py vctk datasets/vctk/synthesizerFühlen Sie sich frei, Proben mit Syn.ipynb während des Trainings zu bewerten und zu synthetisieren
Standardmäßig wird der Vocoder auch mit Datensatz vctk trainiert. Es wäre einfach, nachdem Sie die akustische Funktion aus dem vorherigen Abschnitt ( TTS -Synthesizer ) extrahiert haben. Für eine bessere Leistung verwenden Sie bitte GTA-Melspektrogramm, das von Vocoder_Proprocess.py nach Abschluss des Synthesizer-Trainings erhalten wurde.
CUDA_VISIBLE_DEVICES=0 python vocoder_train.py -g --syn_dir datasets/vctk/synthesizer vctk datasets/vctkStellen Sie den Pfad auf das beiden vorbereiteten Modell (das Lautsprecherüberprüfungsmodell und den Multispeaker -Synthesizer), indem Sie die entsprechenden Schlüssel in hparams.py ändern.
Trainieren Sie das Modell und bewerten Sie jederzeit mit feedback_syn.ipynb
CUDA_VISIBLE_DEVICES=0 python fc_synthesizer_train.py

