tf_multispeakerTTS_fc
1.0.0
Esta es una implementación de TensorFlow de la red TTS multiespeaker introducida en papel desde la verificación de los altavoces hasta la síntesis del habla multiespeaker, transferencia profunda con restricción de retroalimentación. Este repositorio también contiene un modelo de verificación de altavoz profundo que se utiliza en el modelo TTS de múltiples altavoces como la red de retroalimentación. Las muestras sintetizadas se proporcionan en línea.
@inproceedings{Cai2020,
author={Zexin Cai and Chuxiong Zhang and Ming Li},
title={{From Speaker Verification to Multispeaker Speech Synthesis, Deep Transfer with Feedback Constraint}},
year=2020,
booktitle={Proc. Interspeech 2020}
}
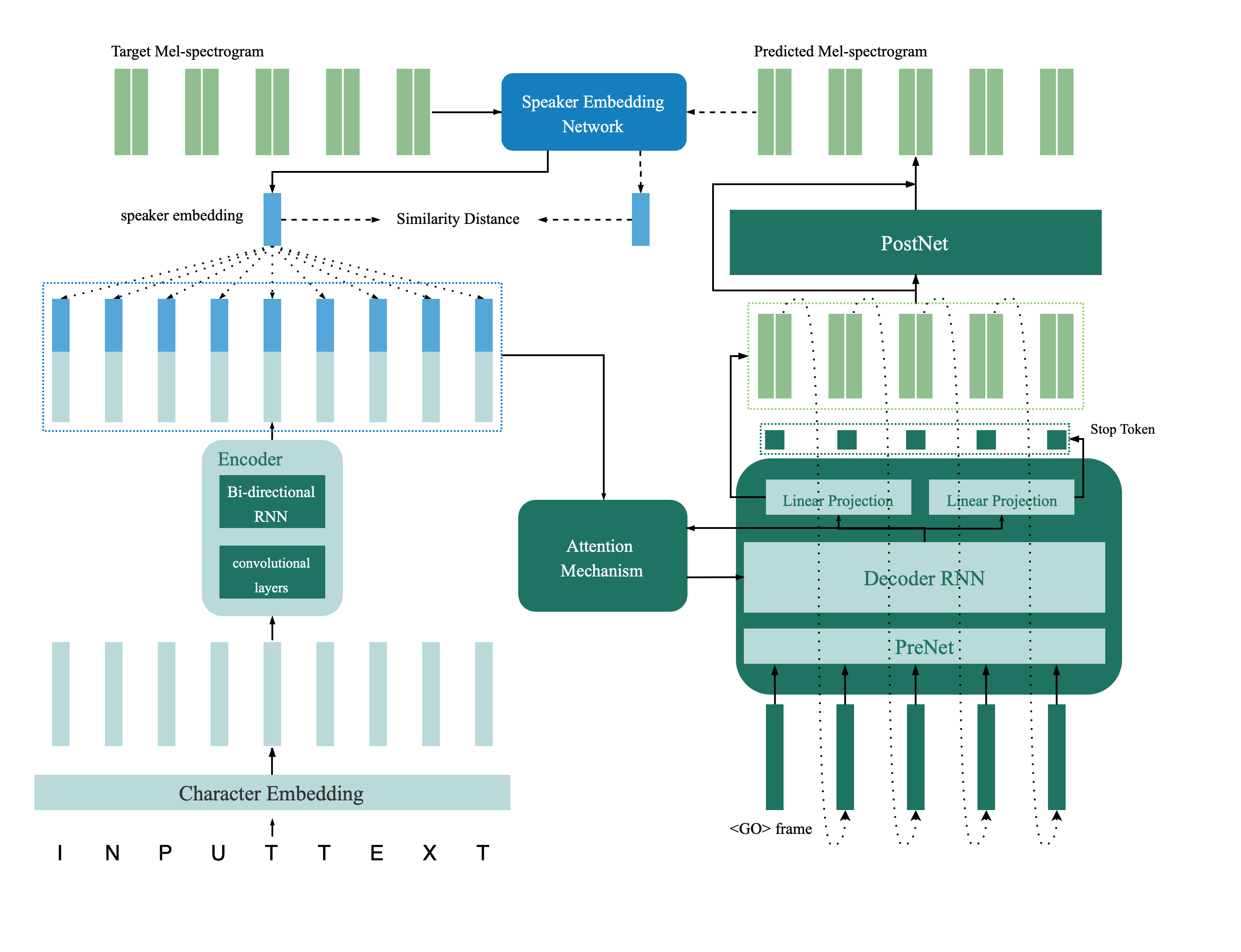
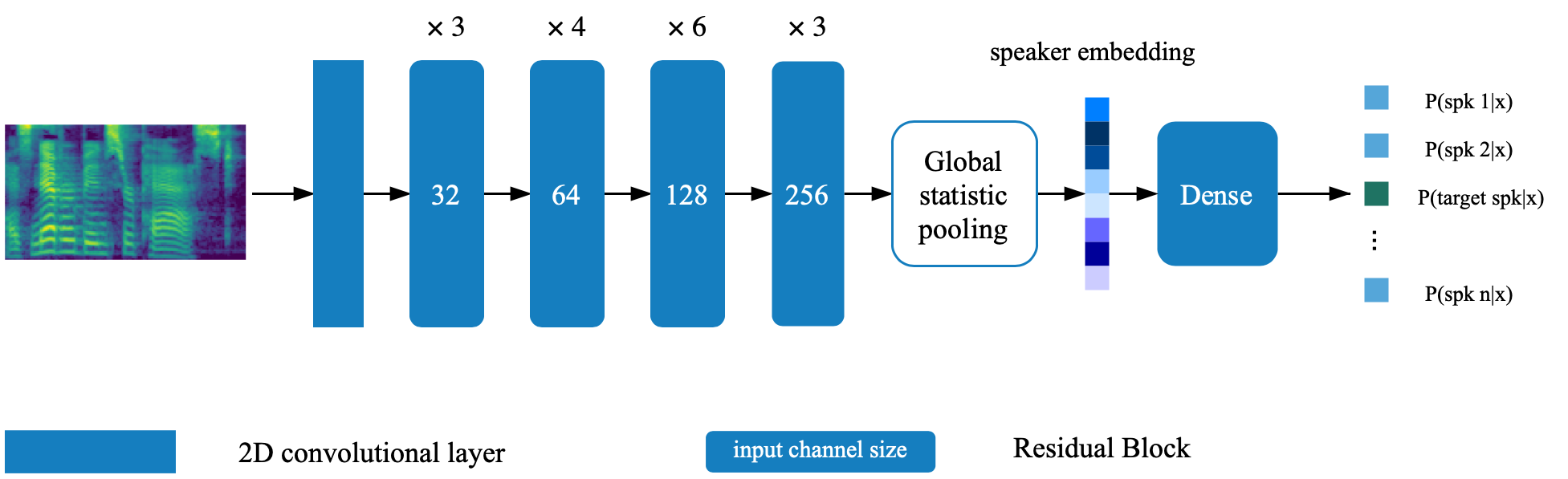
El modelo de verificación del altavoz se encuentra en el directorio profundo_speaker. De forma predeterminada, el modelo de verificación del altavoz está entrenado con datos VoxCeleb 1 y VoxCeleb 2. Puede encontrar la lista de archivos en el directorio. Los hiperparámetros se establecen en VOX12_HPARAMS.PY.
Para capacitar al modelo VerificAiton del altavoz desde cero, prepare los datos como se enumeran en la lista de archivos y ejecuten:
CUDA_VISIBLE_DEVICES=0 python train.pyDe forma predeterminada, el sintetizador está capacitado utilizando DataSet VCTK.
Extraer función de audio usando process_audio.ipynb
Extraer incrustaciones de altavoces utilizando iPython Notebook profundo_speaker/get_gvector.ipynb
Capacitar un sistema de basura multiespeaker TTS
CUDA_VISIBLE_DEVICES=0 python synthesizer_train.py vctk datasets/vctk/synthesizerSiéntase libre de evaluar y sintetizar muestras usando syn.ipynb durante el entrenamiento
De forma predeterminada, el Vocoder también está capacitado utilizando DataSet VCTK. Sería fácil después de que se extraiga la característica acústica de la sección anterior ( sintetizador TTS ). Para un mejor rendimiento, utilice el espectrograma GTA MEL obtenido por VOCODER_PREPROCESS.PY después de que termine el entrenamiento del sintetizador.
CUDA_VISIBLE_DEVICES=0 python vocoder_train.py -g --syn_dir datasets/vctk/synthesizer vctk datasets/vctkEstablezca la ruta en el modelo de dos petróleo (el modelo de verificación del altavoz y el sintetizador multiespeaker) cambiando las teclas correspondientes en hparams.py.
Capacite al modelo y evalúe en cualquier momento con Townleg_syn.ipynb
CUDA_VISIBLE_DEVICES=0 python fc_synthesizer_train.py

