tf_multispeakerTTS_fc
1.0.0
Il s'agit d'une implémentation TensorFlow du réseau TTS multispeaker introduit dans l'article de la vérification des haut-parleurs à la synthèse de la parole multipseaker, transfert en profondeur avec contrainte de rétroaction. Ce référentiel contient également un modèle de vérification de haut-parleur profond qui est utilisé dans le modèle TTS multi-haut-parleurs comme réseau de rétroaction. Des échantillons synthétisés sont fournis en ligne.
@inproceedings{Cai2020,
author={Zexin Cai and Chuxiong Zhang and Ming Li},
title={{From Speaker Verification to Multispeaker Speech Synthesis, Deep Transfer with Feedback Constraint}},
year=2020,
booktitle={Proc. Interspeech 2020}
}
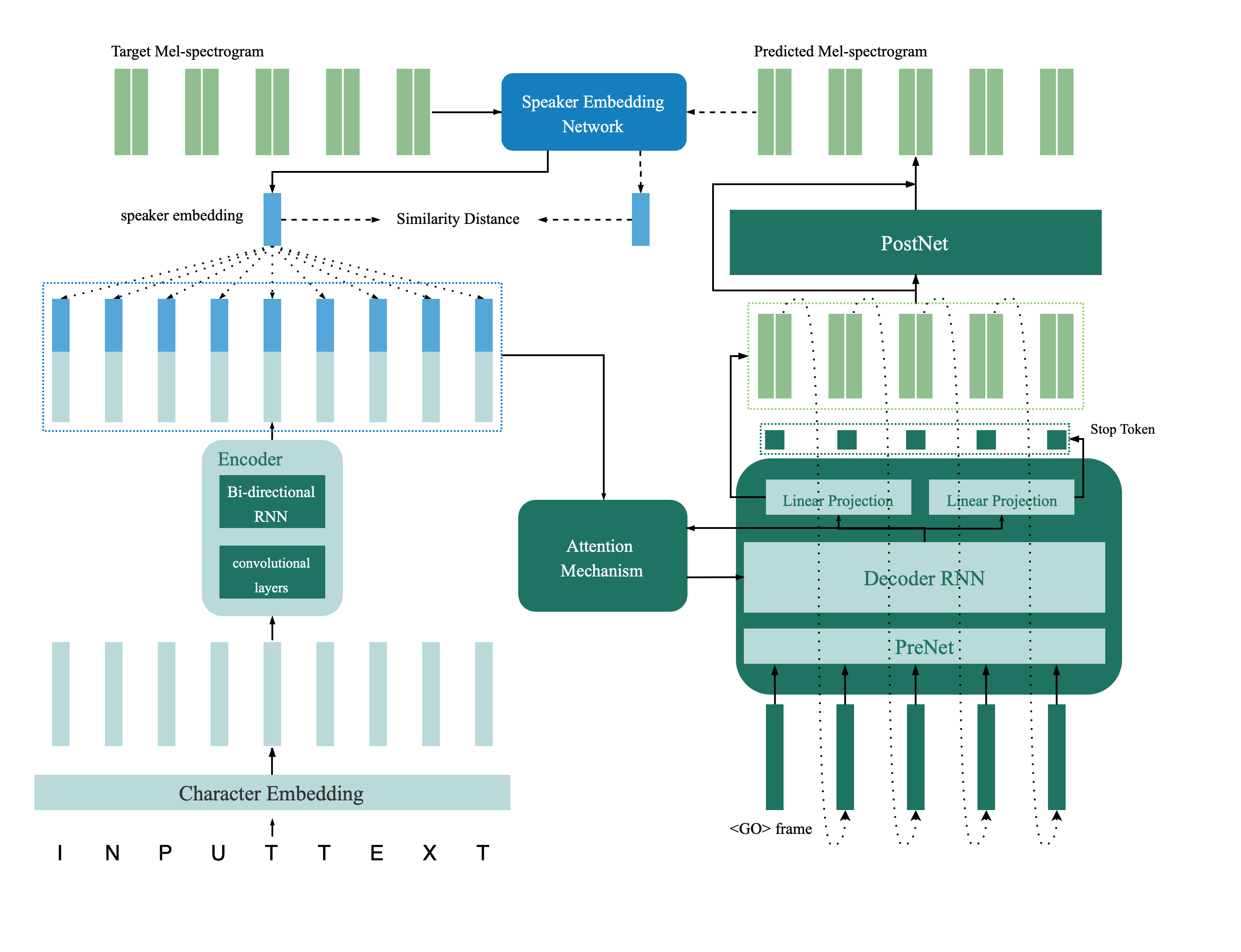
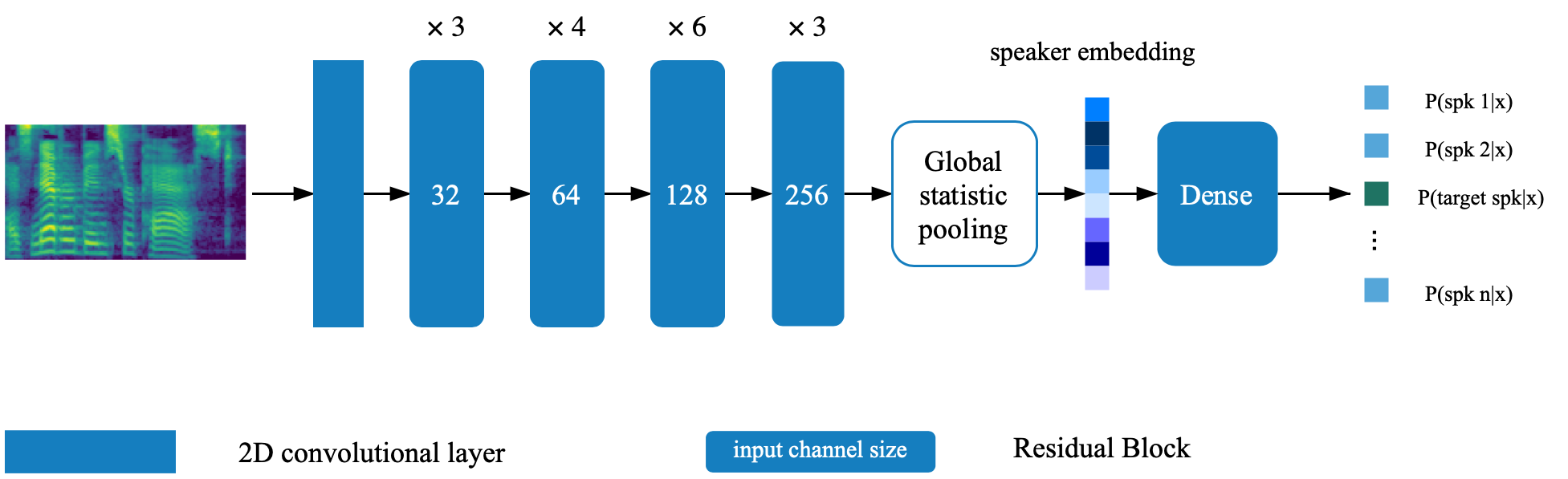
Le modèle de vérification du haut-parleur est situé dans le répertoire Deep_speaker. Par défaut par défaut, le modèle de vérification des haut-parleurs est formé avec Data Voxceleb 1 et Voxceleb 2. Vous pouvez trouver la liste de fichiers dans le répertoire. Les hyperparamètres sont définis dans vox12_hparams.py.
Pour former le modèle Vérificait de haut-parleur à partir de zéro, préparez les données répertoriées dans la liste des fichiers et exécutez:
CUDA_VISIBLE_DEVICES=0 python train.pyPar défaut par défaut, le synthétiseur est formé à l'aide de DataSet VCTK.
Extraire la fonction audio à l'aide de process_audio.ipynb
Extraire les incorporations du haut-parleur à l'aide d'Ipython Notebook Deep_speaker / get_gvector.ipynb
Former un système TTS multispeaker de base
CUDA_VISIBLE_DEVICES=0 python synthesizer_train.py vctk datasets/vctk/synthesizerN'hésitez pas à évaluer et à synthétiser des échantillons à l'aide de syn.ipynb pendant la formation
Par défaut par défaut, le vocodeur est également formé à l'aide de DataSet VCTK. Il serait facile après la fonctionnalité acoustique extraite de la section précédente ( synthétiseur TTS ). Pour de meilleures performances, veuillez utiliser le spectrogramme MEL GTA obtenu par vocoder_preprocess.py une fois la formation du synthétiseur terminé.
CUDA_VISIBLE_DEVICES=0 python vocoder_train.py -g --syn_dir datasets/vctk/synthesizer vctk datasets/vctkDéfinissez le chemin d'accès aux deux modèles pré-entraînés (le modèle de vérification du haut-parleur et le synthétiseur multipakeur) en modifiant les touches correspondantes dans hparams.py.
Former le modèle et évaluer à tout moment avec Feedback_Syn.ipynb
CUDA_VISIBLE_DEVICES=0 python fc_synthesizer_train.py

