tf_multispeakerTTS_fc
1.0.0
これは、スピーカーの検証からマルチスピーカーの音声合成まで、フィードバック制約を伴う深い転送まで、紙で導入されたマルチスピーカーTTSネットワークのターンフロー実装です。このリポジトリには、マルチスピーカーTTSモデルでフィードバックネットワークとして使用されるディープスピーカー検証モデルも含まれています。合成されたサンプルはオンラインで提供されます。
@inproceedings{Cai2020,
author={Zexin Cai and Chuxiong Zhang and Ming Li},
title={{From Speaker Verification to Multispeaker Speech Synthesis, Deep Transfer with Feedback Constraint}},
year=2020,
booktitle={Proc. Interspeech 2020}
}
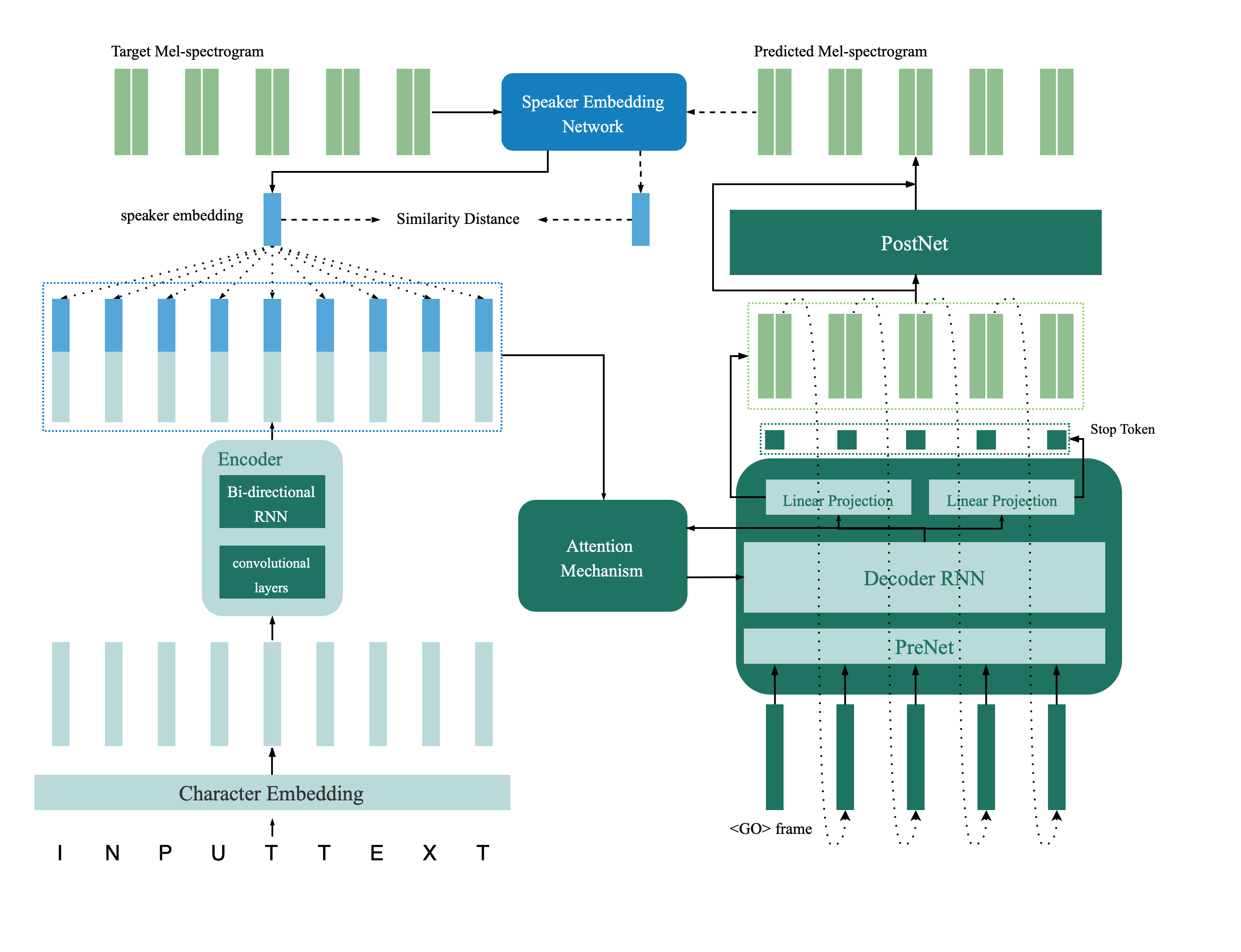
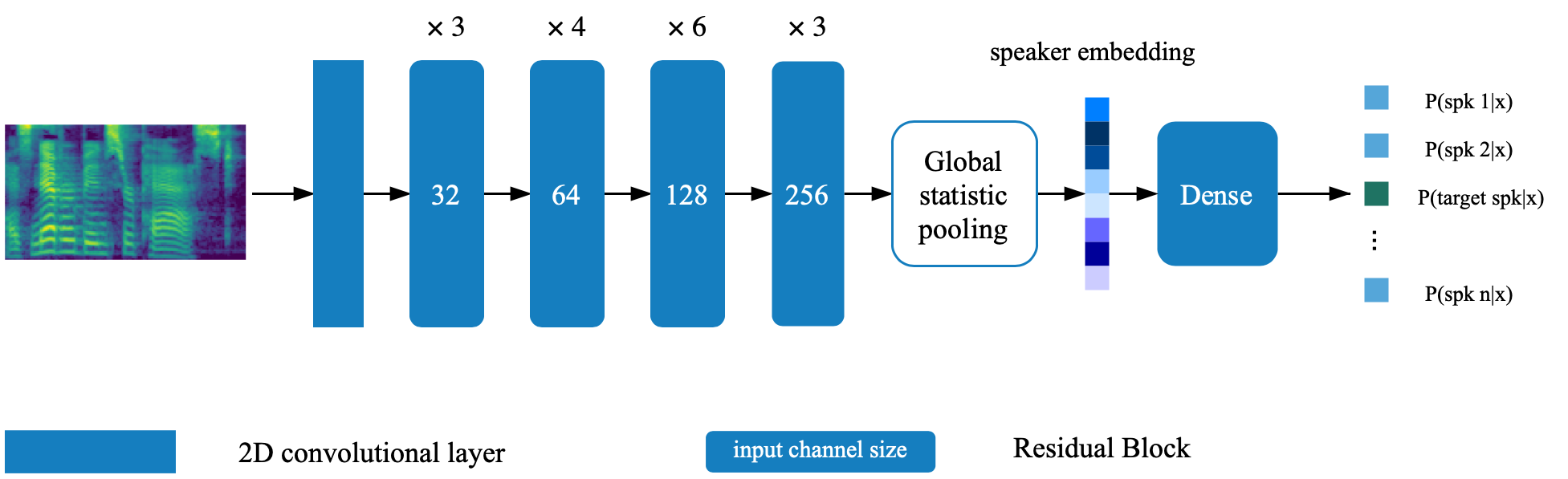
スピーカー検証モデルは、ディレクトリdeep_speakerにあります。デフォルトでは、スピーカー検証モデルはデータVoxceleB 1およびVoxceleB 2でトレーニングされています。ディレクトリにファイルリストを見つけることができます。ハイパーパラメーターはvox12_hparams.pyで設定されています。
スピーカーVerificAitonモデルをゼロからトレーニングするには、ファイルリストに記載されているデータを準備して実行します。
CUDA_VISIBLE_DEVICES=0 python train.pyデフォルトでは、シンセサイザーはデータセットVCTKを使用してトレーニングされます。
process_audio.ipynbを使用してオーディオ機能を抽出します
IPythonノートブックを使用してスピーカーの埋め込みを抽出しますdeep_speaker/get_gvector.ipynb
ベースラインマルチスピーカーTTSシステムをトレーニングします
CUDA_VISIBLE_DEVICES=0 python synthesizer_train.py vctk datasets/vctk/synthesizerトレーニング中にsyn.ipynbを使用してサンプルを評価して合成してください
デフォルトでは、ボコーダーはデータセットVCTKを使用してトレーニングされます。前のセクション( TTSシンセサイザー)から音響機能を抽出した後は簡単です。パフォーマンスを向上させるには、シンセサイザーのトレーニングが終了した後、VoCoder_Preprocess.pyによって取得されたGTA Mel-SpectRogramを使用してください。
CUDA_VISIBLE_DEVICES=0 python vocoder_train.py -g --syn_dir datasets/vctk/synthesizer vctk datasets/vctkHparams.pyの対応するキーを変更することにより、2つの前提条件モデル(スピーカー検証モデルとマルチスピーカーシンセサイザー)へのパスを設定します。
モデルをトレーニングし、feedback_syn.ipynbでいつでも評価します
CUDA_VISIBLE_DEVICES=0 python fc_synthesizer_train.py

