tf mlptts
v1.0: CTC-based alignment distillation
基于MLP-MIXER的TTSORFLOW实现。
在python中测试3.7.9 Ubuntu Conda环境,需求.txt
要下载LJ-Speech数据集,请在脚本下运行。
数据集将以tfrecord格式以'〜/tensorflow_datasets下载。如果要更改下载目录,请指定LJSpeech初始化器的data_dir参数。
from speechset . datasets import LJSpeech
# lj = LJSpeech(data_dir=path, download=True)
lj = LJSpeech ( download = True ) 要训练型号,请运行train.py。
CheckPoint将写在TrainConfig.ckpt上,张量板摘要上的TrainConfig.log 。
python train.py
tensorboard --logdir . l og如果您想从RAW AUDIO训练模型,请指定音频目录并打开标志--from-raw 。
python . t rain.py --data-dir ./LJSpeech-1.1/wavs --from-raw为了开始从以前的检查点进行训练,可以使用--load-epoch 。
python . t rain.py --load-epoch 20 --config D: t f c kpt m lptts.json预处理的检查站将在版本上重新介绍。
要使用预估计的模型,请下载文件并解压缩。以下是示例脚本。
from config import Config
from mlptts import MLPTextToSpeech
with open ( 'mlptts.json' ) as f :
config = Config . load ( json . load ( f ))
tts = MLPTextToSpeech ( config . model )
dummies = {
'text' : tf . zeros ([ 1 , 1 ], dtype = tf . int32 ),
'textlen' : tf . ones ([ 1 ], dtype = tf . int32 ),
'mel' : tf . zeros ([ 1 , 5 , config . model . mel ]),
'mellen' : tf . convert_to_tensor ([ 5 ], dtype = tf . int32 ),
}
# build
tts ( ** dummies )
# restore
tts . restore ( './mlptts_299.ckpt-1' ). expect_partial ()地狱代码样本可在temprence.py上获得
火车ljspeech 300个时代与TF-Diffwave
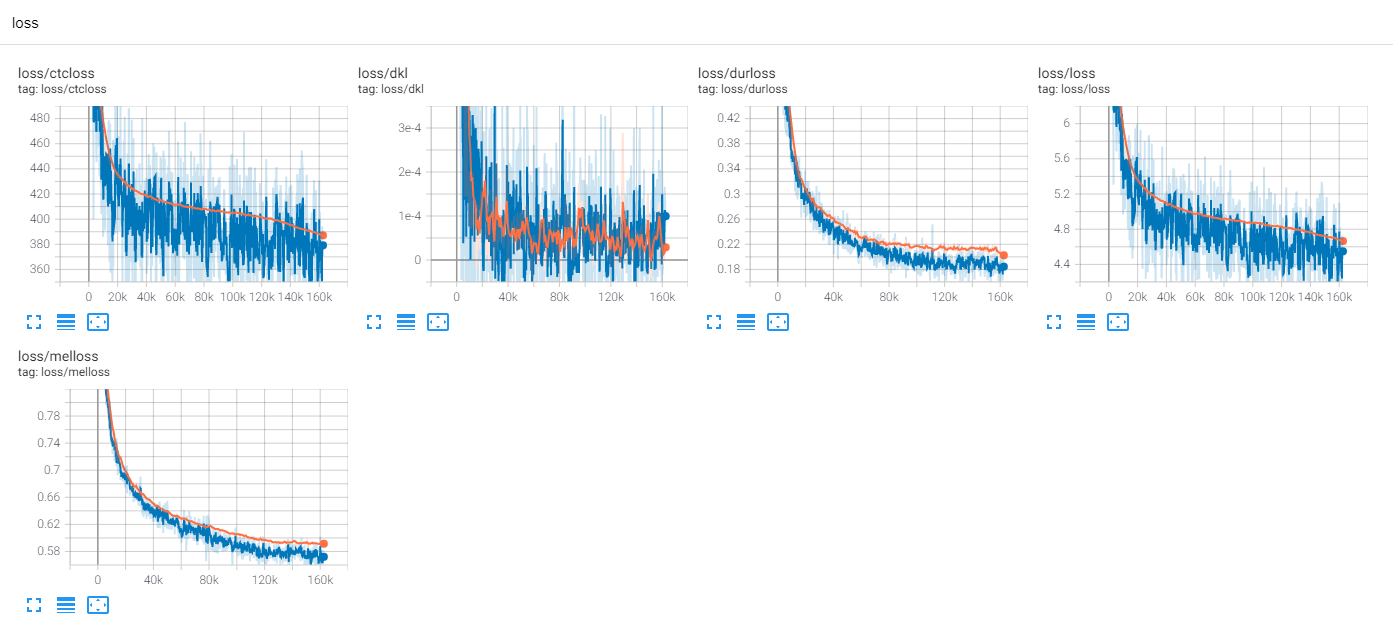
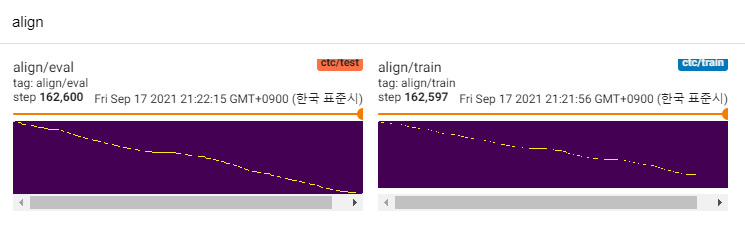

到目前为止,有很多TTS研究,尤其是如今的趋势。 MLP-TTS是Aligntts [6]引入的基于CTC的持续时间蒸馏之一。
另一方面,MLP-MIXER [1]和RESMLP [2]引入了NN骨干的仅MLP架构。
由于变压器和卷积是当前TTS场上的主要骨干,因此我尝试研究可以与TT兼容的其他骨干。 MLP-TTS是具有基于MLP架构的TTS的实验。
第一个问题是如何为动态长度输入建模MLP。
MLP-MIXER [1]和RESMLP [2]假定固定数量的补丁,并且可以在时间轴上使用MLP。但是在TTS情况下,由于接受动态大小输入,具有固定尺寸权重的MLP与这些任务不相容。
我提出了一些动态长度的类似MLP的架构,可以在MLP.Py上找到。
A. Convmlp
ConvMLP在时间轴上使用宽长度MLP。为了处理时间动态性,它可以使用重叠区域制作固定的长度帧,可以简单地在STFT(短期傅立叶变换)上找到。在两层MLP层之后,它将其重叠和添加以制成单个序列。
为了计算效率,选择了2D卷积和转置卷积,但是由于需要大尺寸的内存(批次x num_frames x frame_size),因此不实用。而且,由于我们选择了重叠和添加的cuda-accelaration的转置卷积,因此窗口函数在操作序列中无法适应(例如Hann窗口)。
B. tuermalconv
这是简单的卷积仅作用于颞轴。为了防止在通道轴上的操作,使用[S,1]步幅和[K,1]内核的Conv2D用于扩展的输入特征[B,T,C,1]。
C. dyntemporalmlp
它从输入功能计算动态MLP权重。为简单起见,MLP以转置和串联特征运行。
[b,1,t,c] x [b,t,1,c] = [b,t,t,t,cx2] - > [b,t,t,t,1]
它在MLP混合物之间存在两个哲学上的差异。
首先,混合器将模块分为两个独家操作,即通道级MLP和时间级MLP。但是DynTemporalMLP作用于通道轴,用于计算动态权重。
其次,由于MLP从各个职位中学习权重,因此不需要其他位置信息。但是DynTemporalMLP需要位置嵌入,因为它仅计算出不同位置的两个特征的权重,即置换不变的。
在基线中,MLP-TTS使用大尺寸的TemporalConv转换。
释放Beta-V0.1后,引入了一些有关动态长度MLP的研究。它可以是用MLP编码动态长度特征的一种选择。
在实验中,密集的操作太多,训练程序很少。我在火车上遇到了许多南斯。
我检查了一些稳定培训程序的可能性。
A.层归一化,MLP混合器
像变压器(Vaswani等,2017)一样,MLP-Mixer [1]在每个残留块上使用层归一化。在MLPTT中,它无法稳定培训。
B.仿射转变,resmlp
在Cait(Touvron等,2021)的纸张中,它引入了层表,该层面尺度使用具有较小价值的仿射变换。 RESMLP [2]使用层表,使用该方法可以稳定MLPTT。
C. ddi-Actnorm,Rescalenet
Rescalenet [5]引入了基于DDI(数据依赖性初始化)以解决死亡relu的解决方案。受到Rescalenet的启发,我尝试通过基于DDI的激活归一化来改变仿射变换(Glow,Kingma等,2018)。但是效果很小,关键是缩放系数的小值。
在基线中,MLP-TTS使用仿射变换具有缩放系数的较小值。
从FastSpeech(Ren等,2019)中,明确的持续时间建模者在当今的TTS上很常见。 MLP-TT还尝试使用高斯UPSAPLER的显式持续时间建模器和端到端。
平行TACOTRON 2 [4]的调节剂是最新的贡献,但在MLP-TTS上是不稳定的。我猜测在平行的Tacotron 2上进行调节器的原因是,它假定具有轻量级动态卷积的位置,因此可以从编码的特征中推断出对齐的单调性。但是,MLP-TTS使用MLP和大尺寸的时间卷积,因此可以释放局部性假设,并且无法从特征中推断出单调性。
因此,我明确地假设具有高斯上采样机制(平行Tacotron [3])的单调性,并且可以稳定MLP-TTS训练。
发布Beta-V0.1后,我认为端到端火车仍然不稳定,蒸馏可能是解决对齐问题的方法。
有许多蒸馏模块,例如自回归解码器(EX。JDI-T [7]),基于流量的解码器和单调对准搜索(= MAS,Ex。Glow-TTS [8]),以及从位置编码(例如Paranet [9])。
除了那些,我对Aligntts感兴趣[6]。它使用混合密度网络和类似CTC的目标来建模MEL光谱图和文本之间的关系,然后发现与Viterbi-Algorithm的对齐。
MLP-TT还使用MDN和CTC在文本和MEL光谱图之间建模相互信息,并通过可能矩阵而不是Viterbi算法找到单调对准搜索的对齐。然后将其简化为持续时间,并蒸馏到durator模块。
CTC+MAS比频谱恢复更好的是高斯UPSAMPLER。它可以产生人类的听觉演讲,并且可以在这里找到样本。我估计失败的原因是,durator的梯度并未向后返回文本编码器,并且文本编码器只能生成上下文特征。
由于它只是POC模型,因此样品是嘈杂的,发音尚不清楚。可以调整和改进的许多因素,例如动态长度MLP模块或内核长度参数等。我很难进一步改进(这只是任期项目),但是如果有人发布PR,我将不胜感激。感谢您的注意。
[1] MLP混合物:视觉的全MLP体系结构,Tolstikhin等,2021。
[2] RESMLP:用于图像分类的FeedForward网络,通过数据有效培训,Touvron等,2021。
[3]平行塔科克斯:非自动回旋和可控的TTS,Elias等,2020。
[4]平行塔科特朗2:具有可区分持续时间建模的非自动回归神经TTS模型,Elias等,2021。
[5]对于训练深层神经网络是必不可少的,Shao等,2020。
[6] Aligntts:Zheng等人,2020年,有效的没有明确对准的有效馈送文本到语音系统。
[7] JDI-T:训练有素的持续时间通知的变压器,用于文本到语音,无明确的对准,2020年,2020年。[8] Glow-TTS:通过单调对准搜索的文本到语音的生成流程,Kim等,Kim等,2020年。[9]非自动文本到文本的文本文本 - 文本对文本,pextect ex-Speech,pengech,Peng,Peng,PENG,PENG,PENG,2019年。


