tf mlptts
v1.0: CTC-based alignment distillation
Implementasi TensorFlow dari TTS berbasis MLP-Mixer.
Diuji di Python 3.7.9 Lingkungan Ubuntu Conda, Persyaratan.txt
Untuk mengunduh dataset LJ-Speech, jalankan di bawah skrip.
Dataset akan diunduh di '~/tensorflow_datasets' dalam format tfrecord. Jika Anda ingin mengubah direktori unduhan, tentukan parameter data_dir dari LJSpeech initializer.
from speechset . datasets import LJSpeech
# lj = LJSpeech(data_dir=path, download=True)
lj = LJSpeech ( download = True ) Untuk melatih model, jalankan train.py.
Pos pemeriksaan akan ditulis di TrainConfig.ckpt , ringkasan Tensorboard di TrainConfig.log .
python train.py
tensorboard --logdir . l og Jika Anda ingin melatih model dari Audio Raw, tentukan Audio Directory dan nyalakan bendera --from-raw .
python . t rain.py --data-dir ./LJSpeech-1.1/wavs --from-raw Untuk mulai berlatih dari pos pemeriksaan sebelumnya, --load-epoch tersedia.
python . t rain.py --load-epoch 20 --config D: t f c kpt m lptts.jsonPos pemeriksaan pretrain dirilis pada rilis.
Untuk menggunakan model pretrained, unduh file dan unzip. Berikut adalah skrip sampel.
from config import Config
from mlptts import MLPTextToSpeech
with open ( 'mlptts.json' ) as f :
config = Config . load ( json . load ( f ))
tts = MLPTextToSpeech ( config . model )
dummies = {
'text' : tf . zeros ([ 1 , 1 ], dtype = tf . int32 ),
'textlen' : tf . ones ([ 1 ], dtype = tf . int32 ),
'mel' : tf . zeros ([ 1 , 5 , config . model . mel ]),
'mellen' : tf . convert_to_tensor ([ 5 ], dtype = tf . int32 ),
}
# build
tts ( ** dummies )
# restore
tts . restore ( './mlptts_299.ckpt-1' ). expect_partial ()Sampel kode inferenece tersedia di inferensi.py
Latih LJSPEECH 300 zaman dengan TF-Diffwave
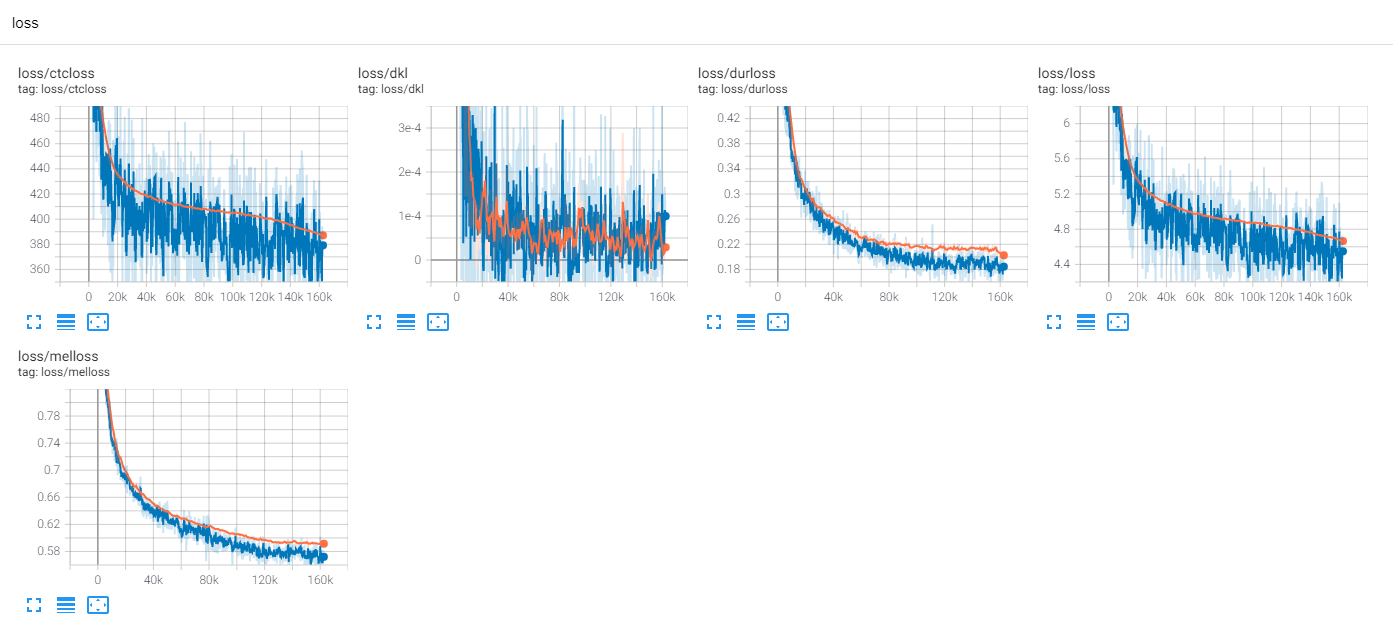
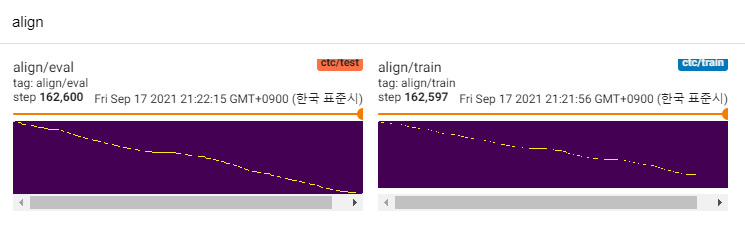

Sejauh ini, ada banyak penelitian TTS, terutama model umpan umpan paralel adalah tren hari ini. MLP-TTS adalah salah satunya dengan distilasi durasi berbasis CTC, diperkenalkan oleh AlignTTS [6].
Di sisi lain, MLP-mixer [1] dan resmlp [2] memperkenalkan arsitektur khusus MLP untuk tulang punggung NN.
Karena transformator dan konvolusi adalah tulang punggung utama di bidang TTS saat ini, saya mencoba meneliti tulang punggung lain yang dapat kompatibel dengan TTS. Dan MLP-TTS adalah percobaan untuk TTS dengan arsitektur berbasis MLP.
Masalah pertama adalah cara memodelkan MLP untuk input panjang dinamis.
MLP-Mixer [1] dan resmlp [2] mengasumsikan sejumlah tambalan dan dimungkinkan untuk menggunakan MLP pada sumbu temporal. Tetapi dalam kasus TTS, karena menerima input ukuran dinamis, MLP dengan bobot ukuran tetap tidak sesuai dengan tugas -tugas ini.
Saya mengusulkan beberapa arsitektur seperti MLP yang dinamis, yang dapat ditemukan di MLP.Py.
A. convmlp
ConvMLP menggunakan MLP panjang lebar pada sumbu temporal. Untuk menangani dinamisitas temporal, itu membuat bingkai panjang tetap dengan daerah yang tumpang tindih, yang dapat dengan mudah ditemukan pada STFT (transformasi Fourier jangka pendek). Setelah dua lapisan MLP, ia beroperasi tumpang tindih untuk membuat urutan tunggal.
Untuk efisiensi komputasi, konvolusi 2D dan konvolusi yang ditransposkan dipilih, tetapi tidak praktis karena ukuran memori yang besar diperlukan (Batch X NUM_FRAMES X FRAME_SIZE). Dan karena kami memilih konvolusi yang ditransposkan untuk CUDA-acelaration dari tumpang tindih dan tambah, fungsi jendela tidak dapat disesuaikan dalam urutan operasi (Kel. Hann Window).
B. Temporalconv
Ini adalah konvolusi sederhana hanya bertindak pada sumbu temporal. Untuk mencegah operasi pada sumbu saluran, conv2d dengan langkah [S, 1] dan [K, 1] kernel digunakan pada fitur input yang diperluas [B, T, C, 1].
C. dyntemporalmlp
Ini menghitung bobot MLP dinamis dari fitur input. Untuk kesederhanaan, MLP beroperasi pada fitur yang ditransfer dan gabungan.
[B, 1, t, c] x [b, t, 1, c] = [b, t, t, cx2] -> [b, t, t, 1]
Ini memiliki dua perbedaan filosofis antara MLP-Mixer.
Pertama, mixer memisahkan modul menjadi dua operasi eksklusif, MLP tingkat saluran dan MLP tingkat temporal. Tetapi DynTemporalMLP bertindak pada sumbu saluran untuk menghitung bobot dinamis.
Kedua, karena MLP mempelajari bobot dari posisi individu, informasi posisi tambahan tidak perlu. Tetapi DynTemporalMLP membutuhkan embeddings posisi karena hanya menghitung bobot dari dua fitur dari posisi yang berbeda, invarian permutasi.
Pada awal, MLP-TTS menggunakan TemporalConv ukuran besar untuk transformasi temporal.
Setelah saya melepaskan beta-v0.1, beberapa penelitian tentang MLP panjang dinamis diperkenalkan. Ini bisa menjadi satu-satunya pilihan untuk mengkodekan fitur panjang dinamis dengan MLP.
Dalam eksperimen, ada terlalu banyak operasi padat dan prosedur pelatihan tidak dapat diselesaikan. Saya bertemu banyak nans di kereta.
Saya memeriksa beberapa kemungkinan untuk menstabilkan prosedur pelatihan.
A. Normalisasi Lapisan, MLP-Mixer
Seperti Transformer (Vaswani et al., 2017), MLP-Mixer [1] menggunakan normalisasi lapisan pada setiap blok residual. Dalam MLPTTS, itu tidak dapat menstabilkan pelatihan.
B. Affine-Transform, resmlp
Dalam kertas CAIT (Touvron et al., 2021), ia memperkenalkan Layerscale, yang menggunakan affine transform dengan nilai kecil faktor skala. Resmlp [2] menggunakan Layerscale dan MLPTTS dapat distabilkan dengan metode ini.
C. DDI-Actnorm, Rescalenet
Rescalenet [5] memperkenalkan debiasing berbasis DDI (inisialisasi yang bergantung pada data) untuk solusi Relu Mati. Terinspirasi oleh Rescalenet, saya mencoba mengubah transformasi affine dengan normalisasi aktivasi berbasis DDI (Glow, Kingma et al., 2018). Tetapi efeknya minimal dan kuncinya adalah nilai kecil dari faktor penskalaan.
Pada awal, MLP-TTS menggunakan affine transform dengan nilai kecil faktor penskalaan.
Dari FastSpeech (Ren et al., 2019), pemodel durasi eksplisit adalah umum di TTS di saat ini. MLP-TTS juga mencoba pemodel durasi eksplisit dan ujung ke ujung dengan Gaussian Upsampler.
Regulator dari paralel Tacotron 2 [4] adalah kontribusi yang lebih baru, tetapi tidak stabil pada MLP-TTS. Dugaan saya tentang alasan mengapa regulator dimungkinkan pada Tacotron 2 paralel adalah mengasumsikan lokalitas dengan konvolusi dinamis ringan, sehingga monotonisitas penyelarasan dapat disimpulkan dari fitur yang dikodekan. Namun, MLP-TTS menggunakan MLP dan konvolusi temporal ukuran besar, sehingga asumsi lokalitas dapat dibebaskan dan monotonisitas tidak dapat disimpulkan dari fitur.
Jadi saya secara eksplisit menganggap monotonisitas dengan mekanisme upampling Gaussian (paralel tacotron [3]), dan dapat menstabilkan pelatihan MLP-TTS.
Setelah saya merilis beta-v0.1, saya pikir kereta ujung ke ujung masih tidak stabil dan distilasi bisa menjadi solusi untuk masalah penyelarasan.
Ada banyak modul distilasi, seperti dekoder autoregresif (mis. JDI-T [7]), decoder berbasis aliran dan pencarian penyelarasan monotonik (= MAS, Kel. Glow-TTS [8]), dan menyempurnakan dari pengkodean posisi (Kel. Paranet [9]).
Kecuali untuk mereka, saya tertarik pada Aligntts [6]. Ini menggunakan jaringan kepadatan campuran dan tujuan seperti CTC untuk memodelkan hubungan antara Mel-spectrogram dan teks, maka ia menemukan keselarasan dengan viterbi-algoritma.
MLP-TTS juga menggunakan MDN dan CTC untuk memodelkan informasi timbal balik antara teks dan Mel-spectrogram, dan menemukan penyelarasan dengan pencarian monotonik-penyelarasan dari matriks kemungkinan alih-alih algoritma viterbi. Kemudian dikurangi menjadi durasi dan disuling ke modul durator.
CTC+MAS lebih baik daripada Gaussian Upsampler, mengenai restorasi spektrogram. Ini dapat menghasilkan pidato dan sampel yang terdengar manusia dapat ditemukan di sini. Saya memperkirakan alasan kegagalan adalah bahwa gradien durator tidak mundur ke encoder teks, dan encoder teks hanya dapat menghasilkan fitur konteks.
Karena ini hanya model POC, sampel berisik dan pengucapan tidak jelas. Ada banyak faktor yang dapat disetel dan ditingkatkan, seperti modul MLP panjang dinamis atau parameter panjang kernel, dll. Akan sulit bagi saya untuk melakukan perbaikan lebih lanjut (itu hanya proyek istilah), tetapi saya akan menghargai jika seseorang memposting PR. Terima kasih atas perhatiannya.
[1] MLP-Mixer: Arsitektur All-MLP untuk Visi, Tolstikhin et al., 2021.
[2] ResMLP: Jaringan FeedForward untuk klasifikasi gambar dengan pelatihan efisien data, Touvron et al., 2021.
[3] TACOTRON Paralel: TTS Non-Autoregresif dan Terkendali, Elias et al., 2020.
[4] Paralel Tacotron 2: Model TTS neural non-autoregresif dengan pemodelan durasi yang dapat dibedakan, Elias et al., 2021.
[5] adalah normalisasi yang sangat diperlukan untuk melatih jaringan saraf yang dalam, Shao et al., 2020.
[6] AlignTTS: Sistem teks-ke-speech feed-forward yang efisien tanpa penyelarasan eksplisit, Zheng et al., 2020.
[7] JDI-T: Durasi yang terlatih secara bersama-sama memberi informasi untuk teks-ke-ucapan tanpa penyelarasan eksplisit, Lim et al., 2020. [8] Glow-TTS: Aliran generatif untuk teks-ke-speech melalui pencarian penyelarasan monotonik, Kim et al., 2020. [9] non-autoregressive saraf saraf saraf non-aural-ke-ungkapan, Pel., 2019.


