tf mlptts
v1.0: CTC-based alignment distillation
تنفيذ TensorFlow من TTS القائم على MLP-mixer.
تم اختباره في بيثون 3.7.9 بيئة أوبونتو كوندا ، المتطلبات.
لتنزيل مجموعة بيانات LJ-Speech ، قم بتشغيله تحت البرنامج النصي.
سيتم تنزيل مجموعة البيانات في "~/TensorFlow_Datasets" بتنسيق tfrecord. إذا كنت ترغب في تغيير دليل التنزيل ، فحدد معلمة data_dir من LJSpeech Enthomizer.
from speechset . datasets import LJSpeech
# lj = LJSpeech(data_dir=path, download=True)
lj = LJSpeech ( download = True ) لتدريب الطراز ، تشغيل Train.py.
سيتم كتابة نقطة التفتيش على TrainConfig.ckpt ، ملخص Tensorboard على TrainConfig.log .
python train.py
tensorboard --logdir . l og إذا كنت ترغب في تدريب النموذج من Raw Audio ، حدد دليل الصوت وقم بتشغيل العلم --from-raw .
python . t rain.py --data-dir ./LJSpeech-1.1/wavs --from-raw للبدء في التدريب من نقطة تفتيش سابقة ، --load-epoch المتاح.
python . t rain.py --load-epoch 20 --config D: t f c kpt m lptts.jsonيتم ربط نقاط التفتيش المسبقة على الإصدارات.
لاستخدام النموذج المسبق ، قم بتنزيل الملفات وفك ضغطه. فيما يلي عينة نص.
from config import Config
from mlptts import MLPTextToSpeech
with open ( 'mlptts.json' ) as f :
config = Config . load ( json . load ( f ))
tts = MLPTextToSpeech ( config . model )
dummies = {
'text' : tf . zeros ([ 1 , 1 ], dtype = tf . int32 ),
'textlen' : tf . ones ([ 1 ], dtype = tf . int32 ),
'mel' : tf . zeros ([ 1 , 5 , config . model . mel ]),
'mellen' : tf . convert_to_tensor ([ 5 ], dtype = tf . int32 ),
}
# build
tts ( ** dummies )
# restore
tts . restore ( './mlptts_299.ckpt-1' ). expect_partial ()نموذج رمز البنت متوفرة على الاستدلال.
تدريب LJSPEEDE 300 مع TF-DIFFWAVE
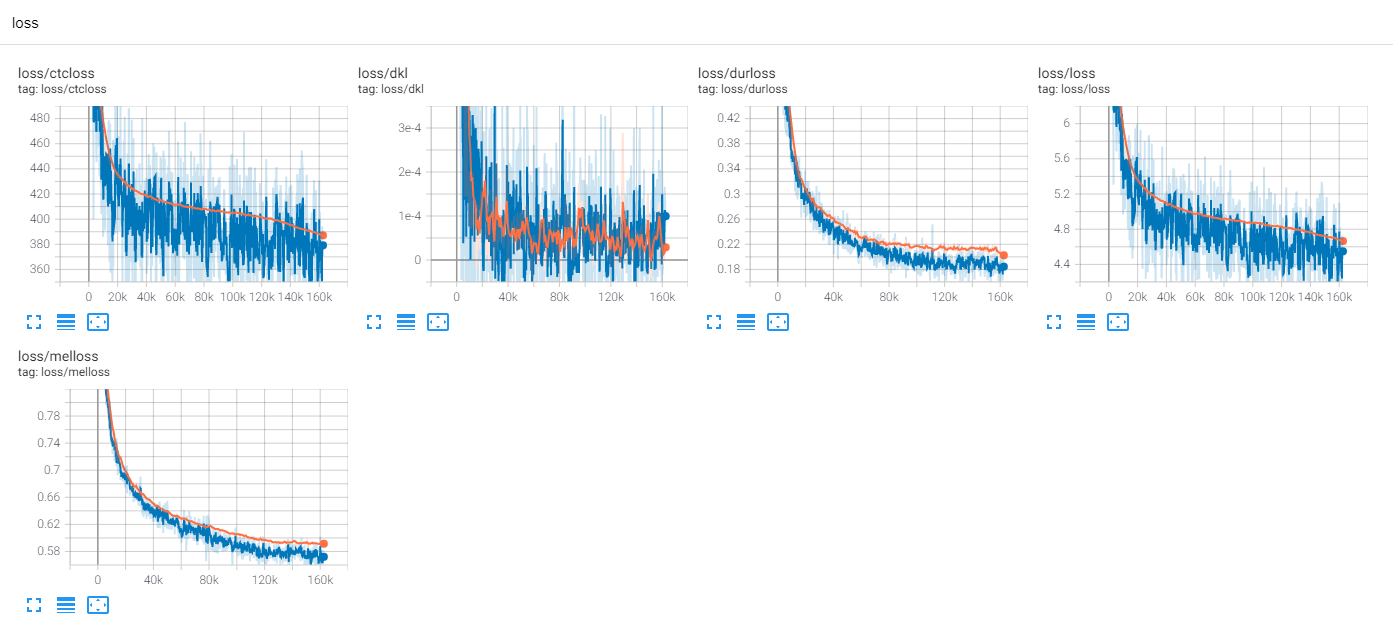

حتى الآن ، هناك الكثير من أبحاث TTS ، وخاصة نماذج التغذية المتوازية هي اتجاهات هذه الأيام. MLP-TTS هو واحد منهم مع التقطير المدة القائمة على CTC ، والتي قدمها Aligntts [6].
على الجانب الآخر ، يقدم MLP-mixer [1] و RESMLP [2] هياكل MLP فقط للعمود الفقري NN.
نظرًا لأن المحولات والتلوينات هي العمود الفقري الرئيسي في حقول TTS الحالية ، أحاول البحث في العمود الفقري الآخر الذي يمكن أن يكون متوافقًا مع TTS. و MLP-TTS هي تجارب ل TTS مع البنى المستندة إلى MLP.
كانت المشكلة الأولى هي كيفية تصميم MLP لمدخلات الطول الديناميكي.
تفترض MLP-mixer [1] و RESMLP [2] عددًا ثابتًا من البقع ومن الممكن استخدام MLP على المحور الزمني. ولكن في حالة TTS ، حيث تقبل مدخلات الحجم الديناميكي ، فإن MLP مع أوزان الحجم الثابت لا تتوافق مع هذه المهام.
أقترح بعض الهياكل الديناميكية التي تشبه MLP ، والتي يمكن العثور عليها على mlp.py.
A. Convmlp
يستخدم ConvMLP MLP طوله على المحور الزمني. للتعامل مع الديناميكية الزمنية ، فإنه يجعل إطارات ذات طول ثابتة مع مناطق متداخلة ، والتي يمكن العثور عليها ببساطة على STFT (تحويل فورييه على المدى القصير). بعد طبقتين من MLP ، تعمل على تداخل وضاف لإجراء التسلسل الفردي.
من أجل الكفاءة الحسابية ، يتم اختيار الالتفاف ثنائي الأبعاد والالتفاف المنقول ، ولكنه ليس عمليًا نظرًا لأن الحجم الكبير للذاكرة مطلوب (الدفعة x num_frames x frame_size). ونظرًا لأننا نختار الالتفاف المنقول للتسجيل CUDA من التداخل والإضافة ، لا يمكن أن تكون وظيفة النافذة قابلة للتكيف في تسلسل التشغيل (نافذة هان).
B. TemporalConv
إنه إيلاء بسيط يعمل فقط على المحور الزمني. لمنع التشغيل على محور القناة ، يتم استخدام inv2d مع خطوة [S ، 1] و [K ، 1] kernel على ميزات الإدخال الموسعة [B ، T ، C ، 1].
C. dyntmatmentormmlp
يحسب أوزان MLP الديناميكية من ميزات الإدخال. للبساطة ، تعمل MLP على الميزات المنقولة والمتسلسلة.
[B ، 1 ، T ، C] X [B ، T ، 1 ، C] = [B ، T ، T ، CX2] -> [B ، T ، T ، 1]
لديها اختلافان فلسفيان بين MLP-mixer.
أولاً ، يقوم الخلاط بفصل الوحدة النمطية إلى عمليتين حصريتين ، MLP على مستوى القناة و MLP على مستوى القناة. لكن DynTemporalMLP يعمل على محور القناة لحساب الأوزان الديناميكية.
ثانياً ، نظرًا لأن MLP يتعلم الأوزان من المواقف الفردية ، فإن المعلومات الموضعية الإضافية غير ضرورية. لكن DynTemporalMLP يتطلب التضمينات الموضعية لأنه يحسب فقط الأوزان من ميزتين لمواقع مختلفة ، ثابتة التقليب.
في الأساس ، يستخدم MLP-TTS حجمًا كبيرًا في الحجم TemporalConv للتحول الزمني.
بعد إطلاق BETA-V0.1 ، يتم تقديم بعض الأبحاث حول MLP ذات الطول الديناميكي. يمكن أن يكون الخيار الوحيد لترميز ميزات الطول الديناميكي مع MLP.
في التجارب ، كان هناك الكثير من العمليات الكثيفة وإجراءات التدريب على الفور. قابلت العديد من NANS في القطار.
أتحقق من بعض الاحتمالات لتحقيق الاستقرار في إجراء التدريب.
A. تطبيع الطبقة ، MLP-mixer
مثل Transformer (Vaswani et al. ، 2017) ، يستخدم MLP-Mixer [1] تطبيع الطبقة على كل كتل متبقية. في MLPTTS ، لا يمكن أن تستقر على التدريب.
ب
في ورقة Cait (Touvron et al. ، 2021) ، فإنه يقدم طبقات ، والتي تستخدم تحويل Affine مع قيمة صغيرة من عامل المقياس. Resmlp [2] يستخدم الطبقات ويمكن تثبيت Mltts مع هذه الطريقة.
C. DDI-Actnorm ، Rescalenet
يقدم Rescalenet [5] DDI (التهيئة المعتمدة على البيانات) القائم على DEBIASS لحل RELU الميت. مستوحاة من Rescalenet ، أحاول تغيير تحويل Affine بتطبيع التنشيط المستند إلى DDI (Glow ، Kingma et al. ، 2018). ولكن كان التأثير ضئيلًا وكان المفتاح هو القيمة الصغيرة لعامل التحجيم.
في الأساس ، يستخدم MLP-TTS تحويل أفيني مع القيمة الصغيرة لعامل التحجيم.
من Fastspeech (Ren et al. ، 2019) ، يعد مصمم المدة الصريح شائعًا في TTS في الوقت الحاضر. يحاول MLP-TTS أيضًا مصمم مدة صريحة ونهاية إلى طرف مع غوسي.
منظم من Tacotron 2 [4] هو مساهمة أكثر حداثة ، لكنها غير مستقرة على MLP-TTS. تخميني للسبب في أنه كان منظمًا ممكنًا على Tacotron 2 المتوازي هو أنه يفترض أن المنطقة ذات الالتفاف الديناميكي الخفيف ، بحيث يمكن استنتاج رتابة المحاذاة من الميزات المشفرة. ومع ذلك ، يستخدم MLP-TTS MLP والالتفاف الزمني كبير الحجم ، بحيث يمكن تحرير افتراض المحلية ولا يمكن استنتاج رتابة من الميزات.
لذلك ، أفترض صراحة الرتابة مع آلية Gaussian upsampling (تاكوترون متوازي [3]) ، ويمكنه تثبيت تدريب MLP-TTS.
بعد إطلاق سراح Beta-V0.1 ، أعتقد أن القطار الشامل لا يزال غير مستقر وقد يكون التقطير هو الحل لمشكلة المحاذاة.
هناك العديد من وحدات التقطير ، مثل فك ترميز الانحدار التلقائي (ex. jdi-t [7]) ، و decoder المستندة إلى التدفق والبحث عن محاذاة رتابة (= mas ، ex. glow-tts [8]) ، والتكرير من الترميزات الموضعية (على سبيل المثال. paranet [9]).
باستثناء أولئك منهم ، أنا مهتم بالمحاذاة [6]. يستخدم شبكة كثافة الخليط والهدف الذي يشبه CTC لنمذجة العلاقة بين طيف الميل والنص ، ثم يجد محاذاة مع Viterbi-algorithm.
يستخدم MLP-TTS أيضًا MDN و CTC لنمذجة المعلومات المتبادلة بين النص و MEL-SPECTROGRAM ، وابحث عن التوافق مع البحث عن محاذاة رتابة من مصفوفة الاحتمالية بدلاً من خوارزمية Viterbi. ثم يتم تقليله إلى فترات وتقطير إلى وحدات Durator.
CTC+MAS أفضل من Gaussian Upsampler ، فيما يتعلق باستعادة الطيف. يمكن أن تولد خطب الإنسان المسموعة ويمكن العثور على عينات هنا. أقدر سبب الفشل هو أن التدرج من Durator لم يتخلف عن ترميزات النص ، وأن ترميزات النصوص يمكن أن تنشئ ميزات السياق فقط.
نظرًا لأنها مجرد نماذج POC ، فإن العينات صاخبة والنطق غير واضح. هناك العديد من العوامل التي يمكن ضبطها وتحسينها ، مثل الوحدات النمطية MLP ذات الطول الديناميكي أو معلمات طول النواة ، وما إلى ذلك. سيكون من الصعب بالنسبة لي إجراء مزيد من التحسينات (كان مجرد مشروع مصطلح) ، لكنني أقدر ذلك إذا نشر شخص ما العلاقات العامة. شكرا لانتباهك.
[1] MLP-mixer: بنية All-MLP للرؤية ، Tolstikhin et al. ، 2021.
[2] RESMLP: شبكات FEEDForward لتصنيف الصور مع تدريب فعال البيانات ، Touvron et al. ، 2021.
[3] TACOTRON المتوازي: TTS غير التوت والتحكم في TTS ، Elias et al. ، 2020.
[4] Tacotron 2 الموازي: نموذج TTS العصبي غير التابع للانحدار مع نمذجة مدة قابلة للتمييز ، Elias et al. ، 2021.
[5] هو التطبيع لا غنى عنه لتدريب الشبكات العصبية العميقة ، Shao et al. ، 2020.
[6] Aligntts: نظام نصي إلى خط الكلام فعال للتغذية دون محاذاة صريحة ، Zheng et al. ، 2020.
[7] JDI-T: محول مستنير مدرب بشكل مشترك للنص إلى الكلام دون محاذاة صريحة ، Lim et al. ، 2020. [8] توهج tts: تدفق توليدي للنص إلى النص إلى خطوة من خلال البحث عن المحاذاة الرتابة ، Kim et al. ، 2020. [9]


