tf mlptts
v1.0: CTC-based alignment distillation
Implementação do TensorFlow de TTS baseado em MLP-mixer.
Testado no Python 3.7.9 Ubuntu conda ambiente, requisitos.txt
Para baixar o conjunto de dados de LJ-Speech, execute no script.
O conjunto de dados será baixado em '~/tensorflow_datasets' no formato tfrecord. Se você deseja alterar o diretório de download, especifique o parâmetro data_dir do Initializador LJSpeech .
from speechset . datasets import LJSpeech
# lj = LJSpeech(data_dir=path, download=True)
lj = LJSpeech ( download = True ) Para treinar o modelo, execute o trem.py.
O ponto de verificação será escrito em TrainConfig.ckpt , resumo do Tensorboard no TrainConfig.log .
python train.py
tensorboard --logdir . l og Se você deseja treinar o modelo a partir do áudio bruto, especifique o diretório de áudio e ligue a bandeira --from-raw .
python . t rain.py --data-dir ./LJSpeech-1.1/wavs --from-raw Para começar a treinar do ponto de verificação anterior, --load-epoch está disponível.
python . t rain.py --load-epoch 20 --config D: t f c kpt m lptts.jsonOs pontos de verificação pré -rastreados são relatados nos lançamentos.
Para usar o modelo pré -terenciado, faça o download de arquivos e descompacte -o. Os seguintes são o script de amostra.
from config import Config
from mlptts import MLPTextToSpeech
with open ( 'mlptts.json' ) as f :
config = Config . load ( json . load ( f ))
tts = MLPTextToSpeech ( config . model )
dummies = {
'text' : tf . zeros ([ 1 , 1 ], dtype = tf . int32 ),
'textlen' : tf . ones ([ 1 ], dtype = tf . int32 ),
'mel' : tf . zeros ([ 1 , 5 , config . model . mel ]),
'mellen' : tf . convert_to_tensor ([ 5 ], dtype = tf . int32 ),
}
# build
tts ( ** dummies )
# restore
tts . restore ( './mlptts_299.ckpt-1' ). expect_partial ()A amostra do código inferenece está disponível no inference.py
Treine LJSpeech 300 Epochs com TF-Diffwave
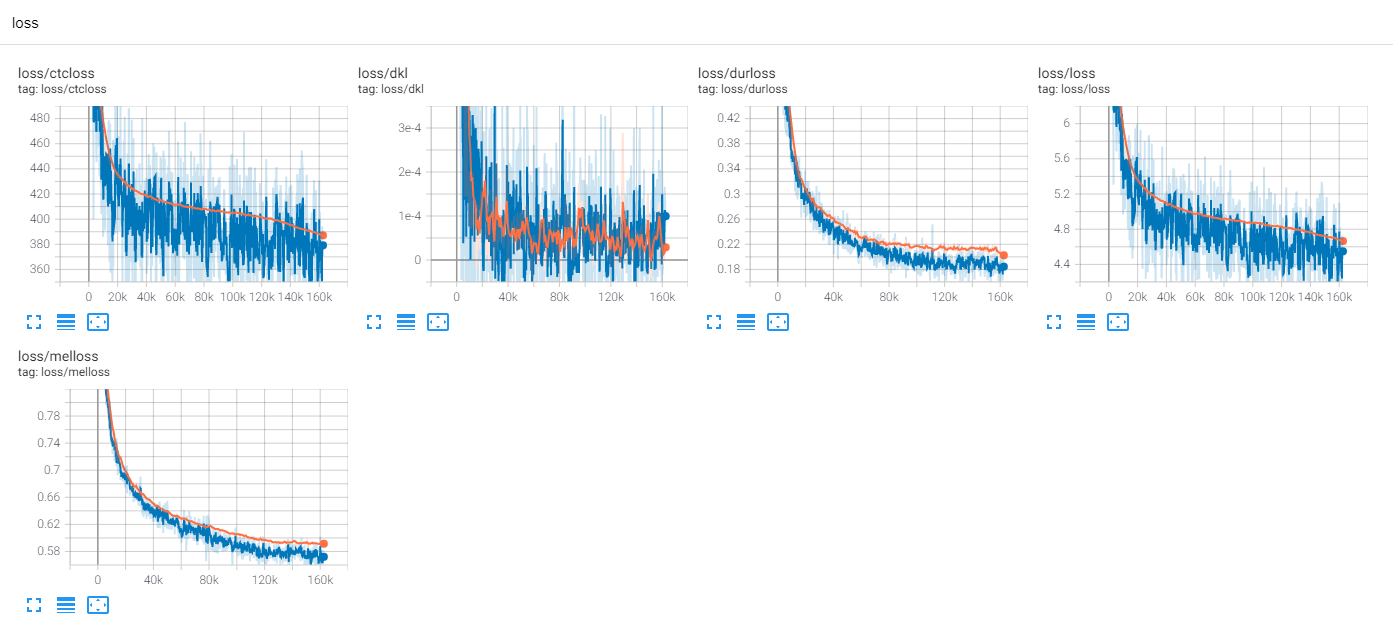

Até agora, há muitas pesquisas TTS, especialmente os modelos paralelos de feed-forward são tendências hoje em dia. O MLP-TTS é um deles com destilação de duração baseada em CTC, introduzida por alinhas [6].
Por outro lado, o MLP-Mixer [1] e o RESMLP [2] introduzem arquiteturas somente para MLP para os backbones da NN.
Como o transformador e as convoluções são os principais backbones nos campos TTS atuais, tento pesquisar os outros backbones que podem ser compatíveis com o TTS. E MLP-TTS são experimentos para TTS com arquiteturas baseadas em MLP.
A primeira edição foi como modelar o MLP para obter entradas dinâmicas de comprimento.
MLP-mixer [1] e RESMLP [2] assumem um número fixo de patches e é possível usar MLP no eixo temporal. Mas no caso TTS, pois aceita entradas de tamanho dinâmico, o MLP com pesos de tamanho fixo é incompatível com essas tarefas.
Proponho algumas arquiteturas do tipo MLP de comprimento dinâmico, que podem ser encontradas no mlp.py.
A. Convmlp
ConvMLP usa MLP de comprimento amplo no eixo temporal. Para lidar com a dinamicidade temporal, produz quadros de comprimento fixo com regiões sobrepostas, que podem ser simplesmente encontradas no STFT (transformação de Fourier de curto prazo). Após duas camadas de MLP, ele opera sobreposição e adição para fazer a única sequência.
Para eficiência computacional, a convolução 2D e a convolução transposta são escolhidas, mas não é prático, pois é necessário grande tamanho de memória (lote x num_frames x quadro_size). E como escolhemos a convolução transposta para a aceleração de cuda de sobreposição e adição, a função de janela não pode ser adaptável na sequência de operação (por exemplo, janela Hann).
B. temporalConv
É simples que a convolução atua apenas no eixo temporal. Para impedir a operação no eixo do canal, o Conv2d com o ritmo [s, 1] e [k, 1] é usado nos recursos de entrada expandidos [b, t, c, 1].
C. Dyntemporalmlp
Ele calcula pesos dinâmicos de MLP dos recursos de entrada. Por simplicidade, a MLP opera em recursos transpostos e concatenados.
[B, 1, t, c] x [b, t, 1, c] = [b, t, t, cx2] -> [b, t, t, 1]
Tem duas diferenças filosóficas entre o MLP-Mixer.
Primeiro, o mixer separa o módulo em duas operações exclusivas, MLP em nível de canal e MLP no nível temporal. Mas DynTemporalMLP atua no eixo do canal para calcular pesos dinâmicos.
Segundo, como a MLP aprende os pesos das posições individuais, informações posicionais adicionais são desnecessárias. Mas DynTemporalMLP requer incorporações posicionais, uma vez que apenas calcula os pesos de duas características de diferentes posições, invariantes de permutação.
Na linha de base, o MLP-TTS usa tamanho grande de tamanho TemporalConv para transformação temporal.
Depois de lançar beta-v0.1, algumas pesquisas sobre MLP de comprimento dinâmico são introduzidas. Pode ser a opção de codificar recursos dinâmicos com MLP.
Em experimentos, há muitas operações densas e procedimento de treinamento foi instável. Eu conheci muitos Nans no trem.
Verifico algumas possibilidades para estabilizar o procedimento de treinamento.
A. Normalização da camada, mlp-mixer
Como o transformador (Vaswani et al., 2017), o MLP-mixer [1] usa a normalização da camada em cada bloco residual. Em MLPTTs, ele não pode estabilizar o treinamento.
B. Affine-Transform, Resmlp
No papel de Cait (Touvron et al., 2021), introduz a escala de camadas, que usa a transformação afim com pequeno valor de fator de escala. O RESMLP [2] usa a escala de camadas e os MLPTTs podem ser estabilizados com esse método.
C. DDI-ACTNORM, RECOBLENENHO
O rescalenet [5] apresenta debiasing baseado em DDI (Inicialização dependente de dados) para a solução de relu morto. Inspirado no Rescalnet, tento alterar a transformação afim com a normalização da ativação baseada em DDI (Glow, Kingma et al., 2018). Mas o efeito foi mínimo e a chave foi o pequeno valor do fator de escala.
Na linha de base, o MLP-TTS usa transformação afim com o pequeno valor do fator de escala.
De FastSpeech (Ren et al., 2019), o Modeler de Duração Explícita é comum no TTS hoje em dia. O MLP-TTS também tenta um modelador de duração explícito e de ponta a ponta com um amostrador gaussiano.
O regulador do tacotron paralelo 2 [4] é uma contribuição mais recente, mas é instável no MLP-TTS. Meu palpite da razão pela qual o regulador era possível no tacotron paralelo 2 foi assumir a localidade com convolução dinâmica leve, de modo que a monotonicidade do alinhamento pode ser inferida a partir de características codificadas. No entanto, o MLP-TTS usa a MLP e a convolução temporal de grande porte, para que a suposição da localidade possa ser libertada e a monotonicidade não pode ser inferida a partir das características.
Por isso, assumi explicitamente a monotonicidade com o mecanismo de amostragem gaussiano (tacotron paralelo [3]) e pode estabilizar o treinamento MLP-TTS.
Depois de lançar o beta-v0.1, acho que o trem de ponta a ponta ainda é instável e a destilação pode ser a solução para o problema de alinhamento.
Existem muitos módulos de destilação, como o decodificador autoregressivo (Ex. JDI-T [7]), decodificador baseado em fluxo e pesquisa de alinhamento monotônico (= MAS, Ex. Glow-TTS [8]) e refinando das codificações posicionais (Ex. Parannet [9]).
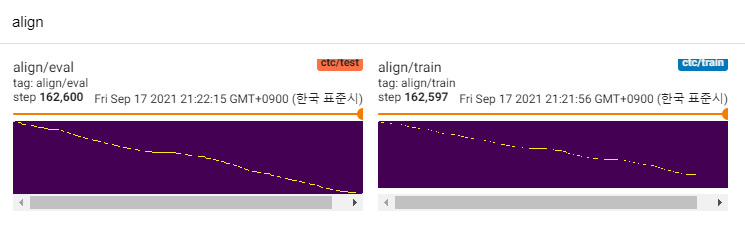
Exceto para os deles, estou interessado em alinhamentos [6]. Ele usa a rede de densidade de mistura e o objetivo do tipo CTC para modelar a relação entre espectrograma MEL e texto, então encontra o alinhamento com o algoritmo Viterbi-i.
O MLP-TTS também usa MDN e CTC para modelar informações mútuas entre texto e espectrograma de MEL e encontre o alinhamento com a pesquisa de alinhamento monotônico da matriz de verossimilhança em vez do algoritmo Viterbi. Em seguida, é reduzido a durações e destilado aos módulos de durador.
O CTC+MAS é melhor que o upsampler gaussiano, referente à restauração do espectrograma. Pode gerar discursos e amostras audíveis humanas podem ser encontrados aqui. Estimo o motivo da falha é que o gradiente do durador não voltou aos codificadores de texto, e os codificadores de texto poderiam gerar apenas recursos de contexto.
Como são apenas modelos POC, as amostras são barulhentas e a pronúncia não é clara. Existem muitos fatores que podem ser ajustados e aprimorados, como módulos de MLP de comprimento dinâmico ou parâmetros de comprimento do kernel, etc. Será difícil para mim fazer mais melhorias (foi apenas um projeto de termo), mas eu o apreciaria se alguém publicar relações públicas. Obrigado pela sua atenção.
[1] MLP-Mixer: Uma arquitetura ALL-MLP para visão, Tolstikhin et al., 2021.
[2] Resmlp: Redes de feedforward para classificação de imagem com treinamento com eficiência de dados, Touvron et al., 2021.
[3] TACOTRON paralelo: TTS não autorregressivo e controlável, Elias et al., 2020.
[4] Tacotron paralelo 2: Um modelo TTS neural não autorregressivo com modelagem de duração diferenciável, Elias et al., 2021.
[5] é normalização indispensável para o treinamento de redes neurais profundas, Shao et al., 2020.
[6] alinham: sistema de texto em fala eficiente e eficientes sem alinhamento explícito, Zheng et al., 2020.
[7] JDI-T: Transformador informado de duração treinada em conjunto para o texto em fala sem alinhamento explícito, Lim et al., 2020. [8] GLOW-TTS: Um fluxo generativo para a fala em fala por meio de pesquisa neural-neural monotônica, Peng et al., 2020.


