tf mlptts
v1.0: CTC-based alignment distillation
การใช้ Tensorflow ของ TTS ที่ใช้ MLP-Inixer
ทดสอบใน Python 3.7.9 Ubuntu Conda Environment, required.txt
หากต้องการดาวน์โหลดชุดข้อมูล LJ-Speech ให้เรียกใช้ภายใต้สคริปต์
ชุดข้อมูลจะถูกดาวน์โหลดใน '~/tensorflow_datasets' ในรูปแบบ tfrecord หากคุณต้องการเปลี่ยนไดเรกทอรีดาวน์โหลดให้ระบุพารามิเตอร์ data_dir ของ LJSpeech initializer
from speechset . datasets import LJSpeech
# lj = LJSpeech(data_dir=path, download=True)
lj = LJSpeech ( download = True ) ในการฝึกอบรมนางแบบ Run Train.py
จุดตรวจสอบจะถูกเขียนบน TrainConfig.ckpt , Tensorboard สรุปเกี่ยวกับ TrainConfig.log
python train.py
tensorboard --logdir . l og หากคุณต้องการฝึกอบรมโมเดลจาก RAW Audio ให้ระบุไดเรกทอรีเสียงและเปิดการตั้งค่าสถานะ --from-raw
python . t rain.py --data-dir ./LJSpeech-1.1/wavs --from-raw ในการเริ่มฝึกอบรมจากจุดตรวจก่อนหน้านี้ --load-epoch พร้อมใช้งาน
python . t rain.py --load-epoch 20 --config D: t f c kpt m lptts.jsonจุดตรวจสอบที่ได้รับการฝึกฝนจะถูกเชื่อมต่อกันในรุ่น
หากต้องการใช้โมเดล pretrained ดาวน์โหลดไฟล์และคลายซิป ต่อไปนี้เป็นสคริปต์ตัวอย่าง
from config import Config
from mlptts import MLPTextToSpeech
with open ( 'mlptts.json' ) as f :
config = Config . load ( json . load ( f ))
tts = MLPTextToSpeech ( config . model )
dummies = {
'text' : tf . zeros ([ 1 , 1 ], dtype = tf . int32 ),
'textlen' : tf . ones ([ 1 ], dtype = tf . int32 ),
'mel' : tf . zeros ([ 1 , 5 , config . model . mel ]),
'mellen' : tf . convert_to_tensor ([ 5 ], dtype = tf . int32 ),
}
# build
tts ( ** dummies )
# restore
tts . restore ( './mlptts_299.ckpt-1' ). expect_partial ()ตัวอย่างรหัส Inferenece มีอยู่ในการอนุมาน.py
รถไฟ LJSpeech 300 Epochs พร้อม TF-Diffwave
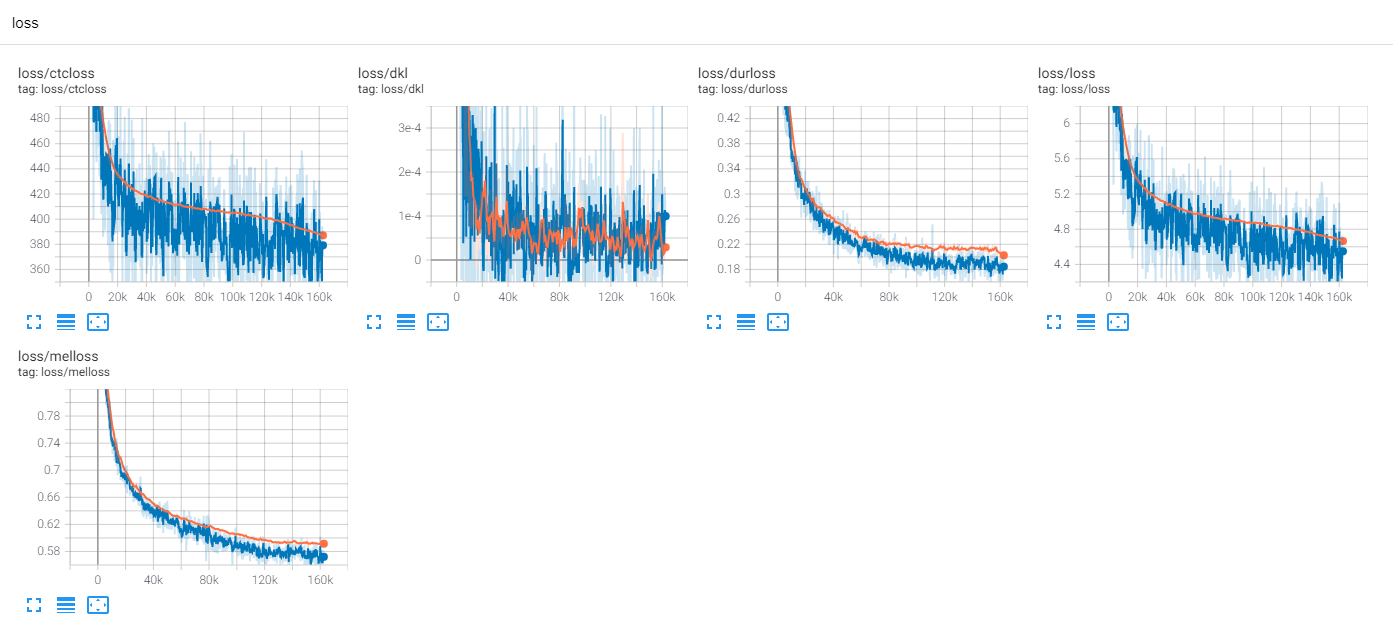
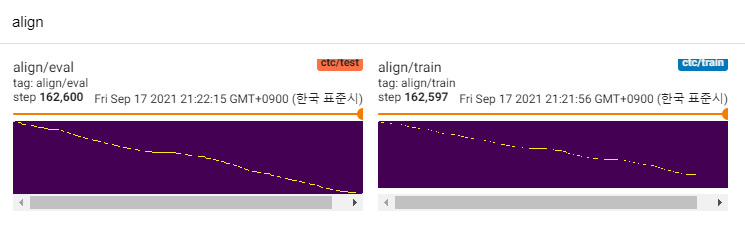

จนถึงตอนนี้มีงานวิจัย TTS จำนวนมากโดยเฉพาะอย่างยิ่งโมเดลฟีดไปข้างหน้าแบบขนานนั้นเป็นแนวโน้มในทุกวันนี้ MLP-TTS เป็นหนึ่งในนั้นที่มีการกลั่นระยะเวลาที่ใช้ CTC ซึ่งแนะนำโดย Aligntts [6]
ในอีกด้านหนึ่ง MLP-Mixer [1] และ ResMLP [2] แนะนำสถาปัตยกรรม MLP-only สำหรับแบ็คโบน NN
เนื่องจากหม้อแปลงและ convolutions เป็นกระดูกสันหลังที่สำคัญในเขตข้อมูล TTS ปัจจุบันฉันจึงพยายามค้นคว้า backbones อื่น ๆ ซึ่งสามารถใช้งานร่วมกับ TTS ได้ และ MLP-TTS เป็นการทดลองสำหรับ TTS ด้วยสถาปัตยกรรมที่ใช้ MLP
ปัญหาแรกคือวิธีการจำลอง MLP สำหรับอินพุตความยาวแบบไดนามิก
MLP-MIXER [1] และ RESMLP [2] สันนิษฐานว่าจำนวนแพตช์คงที่และเป็นไปได้ที่จะใช้ MLP บนแกนชั่วคราว แต่ในกรณี TTS เนื่องจากยอมรับอินพุตขนาดไดนามิก MLP ที่มีน้ำหนักขนาดคงที่ไม่เข้ากันกับงานเหล่านี้
ฉันเสนอสถาปัตยกรรม MLP ที่มีความยาวแบบไดนามิกซึ่งสามารถพบได้ใน MLP.PY
A. convmlp
ConvMLP ใช้ MLP ความยาวกว้างบนแกนชั่วคราว ในการจัดการกับพลวัตทางโลกมันทำให้เฟรมความยาวคงที่กับภูมิภาคที่ซ้อนกันซึ่งสามารถพบได้ง่ายๆใน STFT (การแปลงฟูริเยร์ระยะสั้น) หลังจากเลเยอร์ MLP สองชั้นมันจะทำงานทับซ้อนและเพิ่มเพื่อสร้างลำดับเดียว
เพื่อประสิทธิภาพการคำนวณจำเป็นต้องเลือกการ convolution 2D และการแปลงสภาพที่เปลี่ยนไป แต่ไม่สามารถใช้งานได้จริงเนื่องจากจำเป็นต้องใช้หน่วยความจำขนาดใหญ่ (Batch X NUM_FRAMES X Frame_Size) และเนื่องจากเราเลือก transposed convolution สำหรับการเร่งความเร็วของ CUDA ของการทับซ้อนและ ADD ฟังก์ชั่นหน้าต่างไม่สามารถปรับได้ในลำดับการทำงาน (เช่นหน้าต่าง Hann)
B. TemporalAnv
มันเป็นเรื่องง่ายที่จะทำหน้าที่เฉพาะในแกนชั่วคราว เพื่อป้องกันการทำงานของแกนช่องสัญญาณ CONV2D ด้วย [s, 1] ก้าวย่างและ [k, 1] เคอร์เนลใช้กับคุณสมบัติการป้อนข้อมูลที่ขยายตัว [B, T, C, 1]
C. dyntemporalmlp
มันคำนวณน้ำหนัก MLP แบบไดนามิกจากคุณสมบัติอินพุต เพื่อความเรียบง่าย MLP ดำเนินการกับคุณสมบัติที่ถูกขนถ่ายและต่อกัน
[b, 1, t, c] x [b, t, 1, c] = [b, t, t, cx2] -> [b, t, t, t, 1]
มันมีความแตกต่างทางปรัชญาสองประการระหว่าง MLP-Inixer
อันดับแรกมิกเซอร์จะแยกโมดูลออกเป็นสองการดำเนินการพิเศษ MLP ระดับช่องทางและ MLP ระดับโลก แต่ DynTemporalMLP ทำหน้าที่บนแกนช่องสำหรับการคำนวณน้ำหนักแบบไดนามิก
ประการที่สองเนื่องจาก MLP เรียนรู้น้ำหนักจากแต่ละตำแหน่งข้อมูลตำแหน่งเพิ่มเติมจึงไม่จำเป็น แต่ DynTemporalMLP ต้องการการฝังตำแหน่งเนื่องจากเพียงแค่คำนวณน้ำหนักจากสองคุณสมบัติของตำแหน่งที่แตกต่างกันการเปลี่ยนแปลงค่าคงที่
ในพื้นฐาน MLP-TTS ใช้ TemporalConv ขนาดใหญ่สำหรับการแปลงชั่วคราว
หลังจากที่ฉันเปิดตัว Beta-V0.1 มีการวิจัยบางอย่างเกี่ยวกับ MLP ที่มีความยาวแบบไดนามิก มันสามารถเป็นตัวเลือกเดียวในการเข้ารหัสคุณสมบัติความยาวไดนามิกด้วย MLP
ในการทดลองมีการดำเนินการหนาแน่นและขั้นตอนการฝึกอบรมมากเกินไป ฉันได้พบกับอีกหลายคนบนรถไฟ
ฉันตรวจสอบความเป็นไปได้บางอย่างเพื่อทำให้ขั้นตอนการฝึกอบรมมีเสถียรภาพ
A. การทำให้เป็นมาตรฐานของเลเยอร์, MLP-Inixer
เช่น Transformer (Vaswani et al., 2017), MLP-Mixer [1] ใช้การทำให้เป็นมาตรฐานเลเยอร์ในแต่ละบล็อกที่เหลือ ใน mlptts มันไม่สามารถทำให้การฝึกอบรมมีเสถียรภาพ
B. การเปลี่ยนรูปแบบ, resmlp
ใน Paper of Cait (Touvron et al., 2021), แนะนำ Layerscale ซึ่งใช้การแปลงเลียนแบบพร้อมกับค่าสเกลขนาดเล็ก Resmlp [2] ใช้ Layerscale และ Mlptts สามารถทำให้เสถียรด้วยวิธีนี้
C. ddi-actnorm, rescalenet
Rescalenet [5] แนะนำ DDI (การเริ่มต้นขึ้นอยู่กับข้อมูล) การ debiasing สำหรับการแก้ปัญหาของ Dead Relu ได้รับแรงบันดาลใจจาก Rescalenet ฉันพยายามเปลี่ยนการแปลงเลียนแบบด้วยการกระตุ้นการเปิดใช้งาน DDI (Glow, Kingma et al., 2018) แต่เอฟเฟกต์น้อยที่สุดและกุญแจสำคัญคือค่าเล็กน้อยของปัจจัยการปรับขนาด
ในพื้นฐาน MLP-TTS ใช้การแปลงเลียนแบบพร้อมกับค่าขนาดเล็กของปัจจัยการปรับขนาด
จาก FastSpeech (Ren et al., 2019) ผู้สร้างแบบจำลองระยะเวลาที่ชัดเจนเป็นเรื่องธรรมดาใน TTS ในปัจจุบัน MLP-TTS ยังพยายามสร้างแบบจำลองระยะเวลาที่ชัดเจนและ end-to-end ด้วย upsampler Gaussian
ตัวควบคุมจาก Tacotron 2 [4] เป็นส่วนร่วมล่าสุด แต่มันไม่เสถียรใน MLP-TTS ฉันเดาว่าเหตุผลที่ว่าทำไมผู้ควบคุมจึงเป็นไปได้ใน Tacotron 2 แบบขนานมันถือว่าเป็นสถานที่ที่มีการเปลี่ยนแปลงแบบไดนามิกน้ำหนักเบาเพื่อให้สามารถสรุปการจัดตำแหน่งได้จากคุณสมบัติที่เข้ารหัส อย่างไรก็ตาม MLP-TTS ใช้ MLP และการควบคุมชั่วคราวขนาดใหญ่เพื่อให้สมมติฐานในท้องที่สามารถเป็นอิสระและไม่สามารถสรุปได้จากคุณสมบัติ
ดังนั้นฉันจึงคิดอย่างชัดเจนว่า monotonicity กับกลไกการสุ่มตัวอย่างแบบเกาส์เซียน (Tacotron คู่ขนาน [3]) และสามารถทำให้การฝึกอบรม MLP-TTS มีเสถียรภาพ
หลังจากที่ฉันปล่อย Beta-V0.1 ฉันคิดว่ารถไฟแบบ end-to-end ยังคงไม่เสถียรและการกลั่นอาจเป็นวิธีแก้ปัญหาการจัดตำแหน่ง
มีโมดูลการกลั่นหลายอย่างเช่นตัวถอดรหัส autoregressive (เช่น JDI-T [7]), ตัวถอดรหัสแบบไหลและการค้นหาการจัดตำแหน่งแบบโมโนโทนิก (= MAS, Ex. Glow-TTS [8]) และการกลั่นจากการเข้ารหัสตำแหน่ง (เช่น Paranet [9])
ยกเว้นพวกเขาฉันสนใจที่จะจัดเรียง [6] มันใช้เครือข่ายความหนาแน่นผสมและวัตถุประสงค์คล้าย CTC สำหรับการสร้างแบบจำลองความสัมพันธ์ระหว่าง mel-spectrogram และข้อความจากนั้นจะพบการจัดตำแหน่งกับ viterbi-algorithm
MLP-TTS ยังใช้ MDN และ CTC สำหรับการสร้างแบบจำลองข้อมูลร่วมกันระหว่างข้อความและ mel-spectrogram และค้นหาการจัดตำแหน่งด้วยการค้นหาการจัดตำแหน่งแบบโมโนโทนิกจากเมทริกซ์ความน่าจะเป็นแทนอัลกอริทึม Viterbi จากนั้นจะลดลงเป็นระยะเวลาและกลั่นเป็นโมดูล Durator
CTC+MAS ดีกว่า Gaussian Upsampler เกี่ยวกับการฟื้นฟู Spectrogram มันสามารถสร้างสุนทรพจน์และตัวอย่างเสียงของมนุษย์สามารถพบได้ที่นี่ ฉันประเมินเหตุผลของความล้มเหลวคือการไล่ระดับสีของ Durator ไม่ได้ย้อนกลับไปที่ตัวเข้ารหัสข้อความและตัวเข้ารหัสข้อความสามารถสร้างคุณสมบัติบริบทเท่านั้น
เนื่องจากเป็นเพียงรุ่น POC ตัวอย่างมีเสียงดังและการออกเสียงจึงไม่ชัดเจน มีหลายปัจจัยที่สามารถปรับและปรับปรุงได้เช่นโมดูล MLP ความยาวแบบไดนามิกหรือพารามิเตอร์ความยาวเคอร์เนล ฯลฯ มันจะยากสำหรับฉันที่จะทำการปรับปรุงเพิ่มเติม (เป็นเพียงโครงการระยะเวลา) แต่ฉันจะขอบคุณถ้ามีคนโพสต์ประชาสัมพันธ์ ขอบคุณสำหรับความสนใจของคุณ
[1] MLP-Mixer: สถาปัตยกรรม All-MLP สำหรับการมองเห็น, Tolstikhin et al., 2021
[2] RESMLP: เครือข่าย Feedforward สำหรับการจำแนกรูปภาพด้วยการฝึกอบรมที่มีประสิทธิภาพข้อมูล Touvron et al., 2021
[3] Tacotron แบบขนาน: TTS ที่ไม่ใช่นอกและควบคุมได้, Elias et al., 2020
[4] Tacotron คู่ขนาน 2: โมเดล TTS ที่ไม่ใช่ระบบประสาทแบบอัตโนมัติที่มีการสร้างแบบจำลองระยะเวลาที่แตกต่างกัน Elias et al., 2021
[5] เป็นมาตรฐานที่ขาดไม่ได้สำหรับการฝึกอบรมเครือข่ายประสาทลึก, Shao et al., 2020
[6] Aligntts: ระบบส่งข้อความไปข้างหน้าอย่างมีประสิทธิภาพโดยไม่มีการจัดตำแหน่งที่ชัดเจน, Zheng et al., 2020
[7] JDI-T: Transformer ที่ได้รับการฝึกฝนร่วมกันสำหรับการพูดแบบข้อความเป็นคำพูดโดยไม่มีการจัดตำแหน่งที่ชัดเจน, Lim et al., 2020. [8] Glow-TTS: กระแสการกำเนิดสำหรับการพูดแบบข้อความผ่านการค้นหาแบบ monotonic, Kim et al., 2020. [9]


