tf mlptts
v1.0: CTC-based alignment distillation
Implementación de TensorFlow de TTS basado en MLP-Mixer.
Probado en Python 3.7.9 Ubuntu Conda Environment, requisitos.txt
Para descargar el conjunto de datos LJ-speech, ejecute en script.
El conjunto de datos se descargará en '~/tensorflow_datasets' en formato TFRecord. Si desea cambiar el directorio de descarga, especifique el parámetro data_dir del inicializador LJSpeech .
from speechset . datasets import LJSpeech
# lj = LJSpeech(data_dir=path, download=True)
lj = LJSpeech ( download = True ) Para entrenar modelo, ejecute Train.py.
Checkpoint se escribirá en TrainConfig.ckpt , resumen de Tensorboard en TrainConfig.log .
python train.py
tensorboard --logdir . l og Si desea entrenar el modelo desde RAW Audio, especifique el directorio de audio y encienda el indicador --from-raw .
python . t rain.py --data-dir ./LJSpeech-1.1/wavs --from-raw Para comenzar a entrenar desde el punto de control anterior, --load-epoch está disponible.
python . t rain.py --load-epoch 20 --config D: t f c kpt m lptts.jsonLos puntos de control previos al detenido se frenan en las versiones.
Para usar el modelo de petróleo, descargar archivos y descomponerlo. Los siguientes son script de muestra.
from config import Config
from mlptts import MLPTextToSpeech
with open ( 'mlptts.json' ) as f :
config = Config . load ( json . load ( f ))
tts = MLPTextToSpeech ( config . model )
dummies = {
'text' : tf . zeros ([ 1 , 1 ], dtype = tf . int32 ),
'textlen' : tf . ones ([ 1 ], dtype = tf . int32 ),
'mel' : tf . zeros ([ 1 , 5 , config . model . mel ]),
'mellen' : tf . convert_to_tensor ([ 5 ], dtype = tf . int32 ),
}
# build
tts ( ** dummies )
# restore
tts . restore ( './mlptts_299.ckpt-1' ). expect_partial ()La muestra de código de inferenece está disponible en inferir.py
Train ljspeech 300 épocas con tf-diffwave
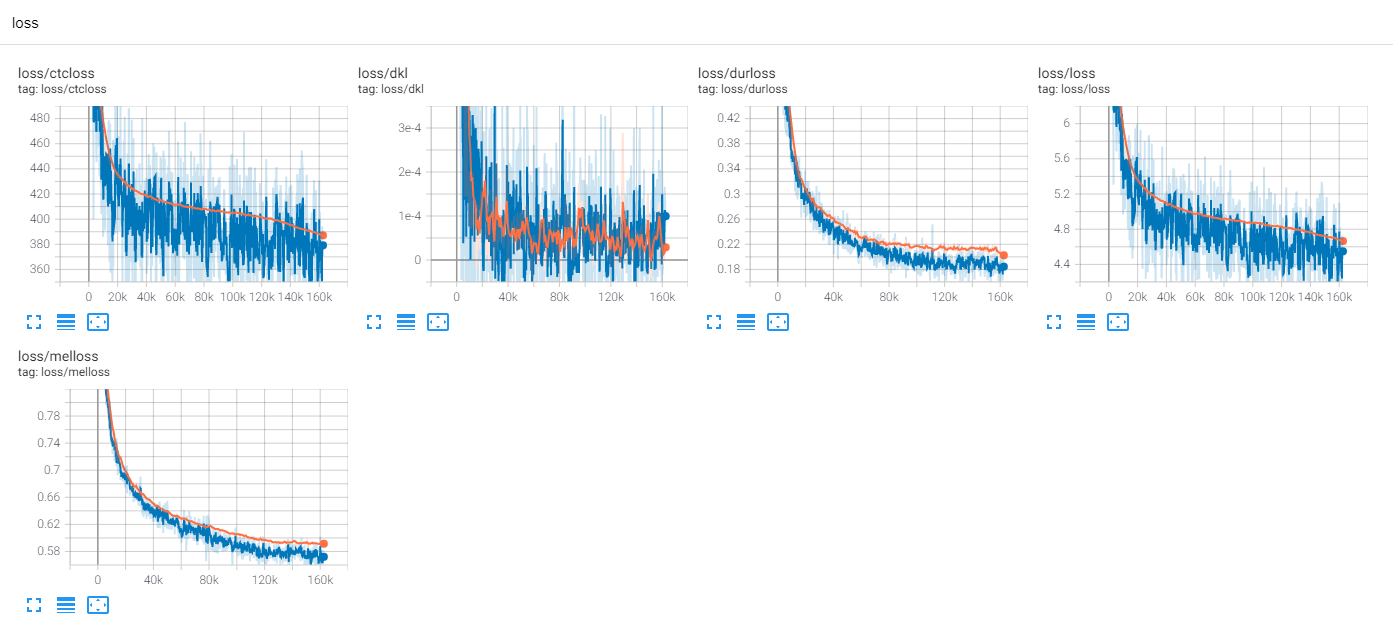
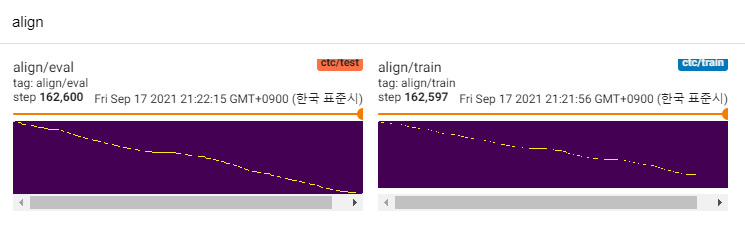

Hasta ahora, hay muchas investigaciones de TTS, especialmente los modelos de alimentación paralelos son tendencias en estos días. MLP-TTS es uno de ellos con destilación de duración basada en CTC, introducida por aligntts [6].
Por otro lado, MLP-Mixer [1] y ResmLP [2] introducen arquitecturas solo MLP para columnas nn.
Dado que el transformador y las convoluciones son troncales principales en los campos TTS actuales, trato de investigar las otras troncos que pueden ser compatibles con TTS. Y MLP-TTS es experimentos para TTS con arquitecturas basadas en MLP.
El primer problema fue cómo modelar MLP para entradas de longitud dinámica.
MLP-MIXER [1] y RESMLP [2] asumen un número fijo de parches y es posible usar MLP en el eje temporal. Pero en el caso TTS, ya que acepta entradas de tamaño dinámico, MLP con pesos de tamaño fijo es incompatible con estas tareas.
Propongo algunas arquitecturas similares a MLP de longitud dinámica, que se pueden encontrar en mlp.py.
A. Convmlp
ConvMLP utiliza MLP de longitud amplia en el eje temporal. Para lidiar con la dinamicidad temporal, fabrica marcos de longitud fija con regiones superpuestas, que simplemente se pueden encontrar en STFT (transformación de Fourier a corto plazo). Después de dos capas MLP, opera superposición y agregada para hacer la secuencia única.
Para la eficiencia computacional, se elige la convolución 2D y la convolución transponida, pero no es práctico ya que se requiere un gran tamaño de memoria (lote x num_frames x frame_size). Y dado que elegimos la convolución transpositada para la aceleración CUDA de superposición y agregada, la función de la ventana no puede ser adaptable en la secuencia de operación (por ejemplo, la ventana Hann).
B. TemporalConv
Es una convolución simple solo actúa sobre el eje temporal. Para evitar la operación en el eje del canal, conv2d con [S, 1] Stride y [K, 1] se usa el núcleo en las características de entrada expandidas [B, T, C, 1].
C. Dyntemporalmlp
Calcula los pesos MLP dinámicos de las características de entrada. Para simplificar, MLP opera en características transpositadas y concatenadas.
[B, 1, t, c] x [b, t, 1, c] = [b, t, t, cx2] -> [b, t, t, 1]
Tiene dos diferencias filosóficas entre MLP-Mixer.
Primero, el mezclador separa el módulo en dos operaciones exclusivas, MLP a nivel de canal y MLP de nivel temporal. Pero DynTemporalMLP actúa en el eje del canal para calcular los pesos dinámicos.
En segundo lugar, dado que MLP aprende los pesos de posiciones individuales, la información posicional adicional es innecesaria. Pero DynTemporalMLP requiere incrustaciones posicionales, ya que simplemente calcula los pesos de dos características de diferentes posiciones, la permutación invariante.
En la línea de base, MLP-TTS utiliza TemporalConv de gran tamaño para la transformación temporal.
Después de lanzar Beta-V0.1, se introducen algunas investigaciones sobre MLP de longitud dinámica. Puede ser la única opción para codificar características de longitud dinámica con MLP.
En los experimentos, hay demasiadas operaciones densas y procedimientos de capacitación fue inestable. Conocí a muchos nans en tren.
Verifique algunas posibilidades para estabilizar el procedimiento de capacitación.
A. Normalización de la capa, MLP-Mixer
Al igual que Transformer (Vaswani et al., 2017), MLP-Mixer [1] utiliza la normalización de la capa en cada bloques residuales. En MLPTTS, no puede estabilizar el entrenamiento.
B. Affine-Transform, RESMLP
En el documento de Cait (Touvron et al., 2021), introduce la escala de capas, que usan transformación afina con un pequeño valor de factor de escala. RESMLP [2] utiliza capascala y los MLPTT se pueden estabilizar con este método.
C. ddi-actnorm, rescalenet
Rescalenet [5] introduce DDI (inicialización dependiente de datos) basado en debias para la solución de RELU muerto. Inspirado en Rescalenet, trato de alterar la transformación afina con la normalización de activación basada en DDI (Glow, Kingma et al., 2018). Pero el efecto fue mínimo y la clave fue el pequeño valor del factor de escala.
En la línea de base, MLP-TTS utiliza transformación afina con el pequeño valor del factor de escala.
Desde FastSpeech (Ren et al., 2019), el modelador de duración explícita es común en TTS en hoy en día. MLP-TTS también intenta un modelador de duración explícita y de extremo a extremo con un muestreador gaussiano.
El regulador del tacotrón 2 paralelo [4] es una contribución más reciente, pero es inestable en MLP-TTS. Supongo que la razón por la cual el regulador fue posible en el tacotrón 2 paralelo fue que supone la localidad con una convolución dinámica de peso ligero, de modo que la monotonicidad de la alineación se puede inferenciar de las características codificadas. Sin embargo, MLP-TTS utiliza MLP y convolución temporal de gran tamaño, de modo que la suposición de la localidad puede liberarse y la monotonicidad no puede inferirse a partir de las características.
Así que supongo explícitamente la monotonicidad con el mecanismo de muestreo gaussiano (tacotrón paralelo [3]), y puede estabilizar el entrenamiento MLP-TTS.
Después de lanzar Beta-V0.1, creo que el tren de extremo a extremo sigue siendo inestable y la destilación podría ser la solución al problema de alineación.
Hay muchos módulos de destilación, como el decodificador autorregresivo (ex. JDI-T [7]), la búsqueda de alineación monotónica basada en el flujo y la búsqueda de alineación monotónica (= MAS, Ej. Glow-TTS [8]), y refinación de codificaciones posicionales (Ej. Paranet [9]).
Excepto por los de ellos, estoy interesado en Aligntts [6]. Utiliza la red de densidad de mezcla y el objetivo similar a CTC para modelar la relación entre el espectrograma MEL y el texto, luego encuentra alineación con el algoritmo Viterbi.
MLP-TTS también utiliza MDN y CTC para modelar información mutua entre el texto y el espectrograma MEL, y encontrar la alineación con la búsqueda de alineación monotónica de la matriz de probabilidad en lugar del algoritmo Viterbi. Luego se reduce a duraciones y se destila a los módulos de durador.
CTC+MAS es mejor que el muestreador gaussiano, con respecto a la restauración del espectrograma. Puede generar discursos audibles humanos y se pueden encontrar muestras aquí. Calculo que la razón de la falla es que el gradiente del durador no retrocedió a los codificadores de texto, y los codificadores de texto solo podrían generar características de contexto.
Dado que son solo modelos POC, las muestras son ruidosas y la pronunciación no está clara. Hay muchos factores que se pueden ajustar y mejorar, como los módulos MLP de longitud dinámica o los parámetros de longitud del núcleo, etc. Será difícil para mí hacer mejoras adicionales (era solo un proyecto a término), pero agradecería que alguien publique relaciones públicas. Gracias por tu atención.
[1] MLP-Mixer: una arquitectura All-MLP para Vision, Tolstikhin et al., 2021.
[2] RESMLP: redes FeedForward para la clasificación de imágenes con capacitación en eficiencia de datos, Touvron et al., 2021.
[3] Tacotrón paralelo: TTS no autorregresivo y controlable, Elias et al., 2020.
[4] Tacotrón paralelo 2: un modelo TTS neural no autorgresivo con modelado de duración diferenciable, Elias et al., 2021.
[5] es la normalización indispensable para entrenar redes neuronales profundas, Shao et al., 2020.
[6] Aligntts: sistema eficiente de texto a voz de texto a voz sin alineación explícita, Zheng et al., 2020.
[7] JDI-T: Transformador informado de duración de entrenamiento conjunta para texto a voz sin alineación explícita, Lim et al., 2020. [8] Glow-TTS: un flujo generativo para texto a voz a través de la búsqueda de alineación monotónica, Kim et al., 2020. [9] Texto neural no autorregresivo, Peng et al., 2019.


