tf mlptts
v1.0: CTC-based alignment distillation
TensorFlow-Implementierung von MLP-Mixer-basierten TTs.
Getestet in Python 3.7.9 Ubuntu Conda Environment, Anforderungen.txt
Um das LJ-Speech-Datensatz herunterzuladen, laufen Sie unter Skript aus.
Der Datensatz wird in '~/TensorFlow_Datasets' im TFRECORD -Format heruntergeladen. Wenn Sie das Download -Verzeichnis ändern möchten, geben Sie den Parameter data_dir von LJSpeech Initializer an.
from speechset . datasets import LJSpeech
# lj = LJSpeech(data_dir=path, download=True)
lj = LJSpeech ( download = True ) Um das Modell zu trainieren, rennen Sie Train.py.
Der Checkpoint wird auf TrainConfig.ckpt , Tensorboard -Zusammenfassung auf TrainConfig.log geschrieben.
python train.py
tensorboard --logdir . l og Wenn Sie das Modell aus RAW Audio trainieren möchten, geben Sie das Audioverzeichnis an und schalten Sie das Flag ein --from-raw .
python . t rain.py --data-dir ./LJSpeech-1.1/wavs --from-raw Um aus dem vorherigen Kontrollpunkt aus zu trainieren, ist --load-epoch verfügbar.
python . t rain.py --load-epoch 20 --config D: t f c kpt m lptts.jsonVorbereitete Checkpoints werden an Veröffentlichungen bezogen.
Laden Sie Dateien herunter und entpacken Sie es, um vorgezogene Modell zu verwenden. Die folgenden Anhänger sind ein Beispielskript.
from config import Config
from mlptts import MLPTextToSpeech
with open ( 'mlptts.json' ) as f :
config = Config . load ( json . load ( f ))
tts = MLPTextToSpeech ( config . model )
dummies = {
'text' : tf . zeros ([ 1 , 1 ], dtype = tf . int32 ),
'textlen' : tf . ones ([ 1 ], dtype = tf . int32 ),
'mel' : tf . zeros ([ 1 , 5 , config . model . mel ]),
'mellen' : tf . convert_to_tensor ([ 5 ], dtype = tf . int32 ),
}
# build
tts ( ** dummies )
# restore
tts . restore ( './mlptts_299.ckpt-1' ). expect_partial ()Inferenece -Code -Probe ist auf Inferenz verfügbar.py
train ljspeech 300 epochs mit tf-diffwave
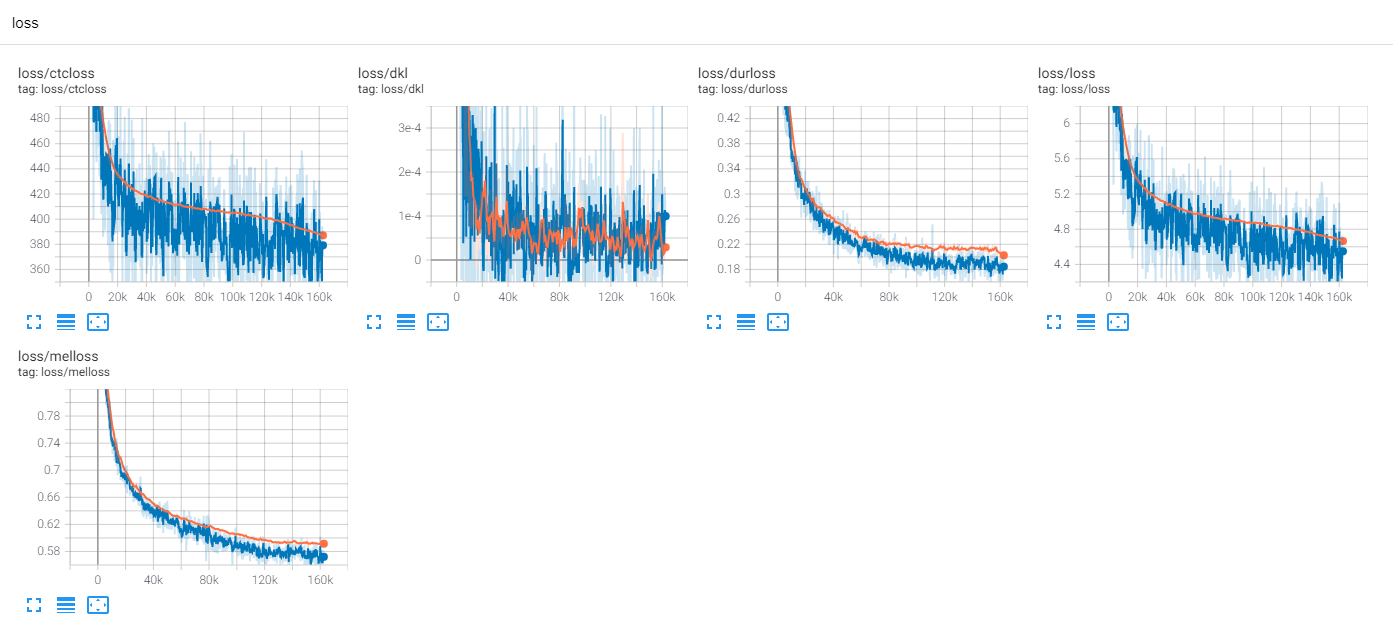

Bisher gibt es viele TTS-Forschungen, insbesondere parallele Feed-Forward-Modelle sind heutzutage Trends. MLP-TTS ist eine von ihnen mit CTC-basierter Dauerdestillation, die von Aligntts [6] eingeführt wird.
Auf der anderen Seite führen MLP-Mixer [1] und RESMLP [2] nur MLP-Architekturen für NN-Rückgrat-Rücken ein.
Da Transformator und Konvolutionen auf aktuellen TTS -Feldern wichtige Rückgrat aufnehmen, versuche ich, die anderen Rückgrat zu erforschen, die mit TTS kompatibel sein können. Und MLP-TTs sind Experimente für TTs mit MLP-basierten Architekturen.
Das erste Problem war, wie MLP für dynamische Längeneingänge modelliert werden.
MLP-Mixer [1] und RESMLP [2] nehmen eine feste Anzahl von Patches an, und es ist möglich, MLP auf der zeitlichen Achse zu verwenden. In dem TTS -Fall, da es dynamische Größeneingänge akzeptiert, ist MLP mit festen Größengewichten mit diesen Aufgaben nicht kompatibel.
Ich schlage einige dynamische MLP-ähnliche Architekturen vor, die auf mlp.py gefunden werden können.
A. concmlp
ConvMLP verwendet eine breite Länge MLP auf der temporalen Achse. Um mit der zeitlichen Dynamizität umzugehen, erzeugt es feste Längenrahmen mit überlappenden Regionen, die einfach auf STFT (kurzfristige Fourier-Transformation) zu finden sind. Nach zwei MLP-Schichten arbeitet es überlappend und add, um die einzelne Sequenz zu erstellen.
Für die Recheneffizienz werden 2D -Faltung und transponierte Faltung gewählt, aber es ist nicht praktisch, da eine große Speichergröße erforderlich ist (Batch x num_frames x Frame_Size). Und da wir eine transponierte Faltung für die Cuda-Akkelaration von Überlappung und ADD wählen, kann die Fensterfunktion in der Betriebssequenz nicht anpassbar sein (z. B. Hann-Fenster).
B. temporalconv
Es ist eine einfache Faltung nur auf die zeitliche Achse. Um den Betrieb auf der Kanalachse zu verhindern, wird Conv2d mit [s, 1] Schritt und [k, 1] Kernel für erweiterte Eingangsmerkmale [B, T, C, 1] verwendet.
C. DyntemporalMlp
Es berechnet dynamische MLP -Gewichte aus Eingangsfunktionen. Der Einfachheit halber arbeitet MLP mit transponierten und verketteten Merkmalen.
[B, 1, t, c] x [b, t, 1, c] = [b, t, t, cx2] -> [b, t, t, 1]
Es hat zwei philosophische Unterschiede zwischen MLP-Mixer.
Zunächst unterscheidet der Mixer das Modul in zwei exklusive Operationen: MLP auf Kanalebene und MLP auf Temporalebene. DynTemporalMLP wirkt jedoch auf die Kanalachse, um dynamische Gewichte zu berechnen.
Zweitens, da MLP die Gewichte aus einzelnen Positionen lernt, sind zusätzliche Positionsinformationen nicht erforderlich. DynTemporalMLP erfordert jedoch Positionseinbettungen, da es nur die Gewichte aus zwei Merkmalen verschiedener Positionen berechnet, Permutation invariant.
In Studienbeginn verwendet MLP-TTs eine große TemporalConv für die zeitliche Transformation.
Nachdem ich Beta-V0.1 veröffentlicht habe, werden einige Forschungen zu MLP mit dynamischer Länge eingeführt. Es kann die eine Wahl sein, um dynamische Länge mit MLP zu codieren.
In Experimenten gibt es zu viele dichte Operationen und Schulungsverfahren waren instabil. Ich habe viele Nans im Zug getroffen.
Ich überprüfe einige Möglichkeiten, um das Schulungsverfahren zu stabilisieren.
A. Schichtnormalisierung, MLP-Mixer
Wie Transformator (Vaswani et al., 2017) verwendet MLP-Mixer [1] die Normalisierung der Schicht für alle Restblöcke. In MLPTTs kann es das Training nicht stabilisieren.
B. affine-transform, resmlp
In Papier von Cait (Touvron et al., 2021) führt es Layerscale ein, die affine Transformation mit geringem Wert des Skalierungsfaktors verwenden. RESMLP [2] verwendet LayerScale und MLPTTs können mit dieser Methode stabilisiert werden.
C. ddi-actnorm, scalenet
Rescalenet [5] führt DDI-basierte Debiasing für die Lösung der toten Relu ein. Inspiriert von scalenet, versuche ich, die affine Transformation mit der DDI-basierten Aktivierungsnormalisierung zu verändern (Glow, Kingma et al., 2018). Der Effekt war jedoch minimal und der Schlüssel war der kleine Wert des Skalierungsfaktors.
Zu Studienbeginn verwendet MLP-TTs eine affine Transformation mit dem geringen Wert des Skalierungsfaktors.
Aus Fastspeech (Ren et al., 2019) ist explizite Dauermodellierer heutzutage bei TTs häufig. MLP-TTs probiert auch einen expliziten Modeler und End-to-End mit einem Gaußschen Upsampler aus.
Der Regler von Parallel Tacotron 2 [4] ist ein neuerer Beitrag, ist jedoch bei MLP-TTs instabil. Ich vermute den Grund, warum Regulator auf dem parallelen Tacotron 2 möglich war, war, dass der Ort mit einer leichten dynamischen Faltung angenommen wird, sodass die Monotonität der Ausrichtung aus kodierten Merkmalen abgeleitet werden kann. MLP-TTS verwendet jedoch MLP und große zeitliche Faltung, sodass die Annahme der Lokalität befreit werden kann und die Monotonizität nicht aus Merkmalen abgeleitet werden kann.
Daher nehme ich ausdrücklich die Monotonizität mit dem Gaußschen Upsampling-Mechanismus (paralleler Tacotron [3]) an und kann das MLP-TTS-Training stabilisieren.
Nachdem ich Beta-V0.1 veröffentlicht habe, denke ich, dass der End-to-End-Zug immer noch instabil ist und die Destillation die Lösung für das Ausrichtungsproblem sein könnte.
Es gibt viele Destillationsmodule, wie den autoregressiven Decoder (z.
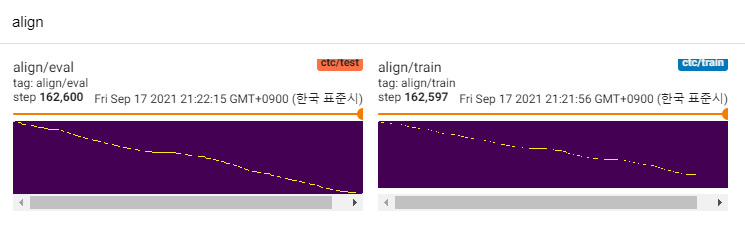
Mit Ausnahme derjenigen von ihnen interessiere ich mich für Ausstellungen [6]. Es verwendet das Mischdichte-Netzwerk und das CTC-ähnliche Ziel für die Modellierung der Beziehung zwischen Melspektogramm und Text und findet dann eine Ausrichtung mit Viterbi-Algorithmus.
MLP-TTs verwendet auch MDN und CTC zum Modellieren von gegenseitigen Informationen zwischen Text und Melspektogramm und finden die Ausrichtung mit der monotonischen Ausrichtung der Wahrscheinlichkeitsmatrix anstelle des Viterbi-Algorithmus. Dann wird es auf Dauer reduziert und auf Duratormodule destilliert.
CTC+MAS ist besser als Gaußscher Upsampler, was die Wiederherstellung der Spektrogramme betrifft. Es kann menschliche hörbare Reden erzeugen und hier finden Sie Proben. Ich schätze, dass der Grund für den Fehler ist, dass der Gradient des Durators nicht rückwärts zu den Textcodierern war und Text -Encoder nur Kontextfunktionen erzeugen konnten.
Da es sich nur um POC -Modelle handelt, sind die Proben laut und die Aussprache ist unklar. Es gibt viele Faktoren, die abgestimmt und verbessert werden können, z. B. MLP -Module der dynamischen Länge oder Kernellängenparameter usw. Es wird schwierig für mich sein, weitere Verbesserungen vorzunehmen (es war nur ein Term -Project), aber ich würde es schätzen, wenn jemand popt postet. Dank für Ihre Aufmerksamkeit.
[1] MLP-Mixer: Eine All-MLP-Architektur für Vision, Tolstikhin et al., 2021.
[2] RESMLP: Feedforward-Netzwerke für die Bildklassifizierung mit dateneffizientem Training, Touvron et al., 2021.
[3] Parallele Tacotron: Nicht-Autoregressive und kontrollierbare TTS, Elias et al., 2020.
[4] Parallele Tacotron 2: Ein nicht autoregressives TTS-Modell mit differenzierbarer Dauermodellierung, Elias et al., 2021.
[5] ist eine Normalisierung für die Ausbildung von tiefen neuronalen Netzwerken, Shao et al., 2020.
[6] Aligntts: Effizientes Feed-Forward-Text-zu-Speech-System ohne explizite Ausrichtung, Zheng et al., 2020.
[7] JDI-T: Die gemeinsam geschulte Dauer informierter Transformator für Text-zu-Sprache ohne explizite Ausrichtung, Lim et al., 2020. [8] Glow-TTs: Ein generativer Fluss für Text-to-Sprache über monotonische Ausrichtungssuche, Kim et al., 2020.


