tf mlptts
v1.0: CTC-based alignment distillation
Implémentation TensorFlow de TTS basés sur MLP-MIXER.
Testé dans Python 3.7.9 Ubuntu Conda Environment, exigences.txt
Pour télécharger le jeu de données LJ-Speech, exécutez sous Script.
L'ensemble de données sera téléchargé dans «~ / Tensorflow_datasets» au format tfrecord. Si vous souhaitez modifier le répertoire de téléchargement, spécifiez le paramètre data_dir de l'initialisateur LJSpeech .
from speechset . datasets import LJSpeech
# lj = LJSpeech(data_dir=path, download=True)
lj = LJSpeech ( download = True ) Pour entraîner le modèle, exécutez Train.py.
Le point de contrôle sera écrit sur TrainConfig.ckpt , Tensorboard Résumé sur TrainConfig.log .
python train.py
tensorboard --logdir . l og Si vous souhaitez former le modèle à partir de RAW Audio, spécifiez le répertoire audio et activez l'indicateur --from-raw .
python . t rain.py --data-dir ./LJSpeech-1.1/wavs --from-raw Pour commencer à s'entraîner à partir du point de contrôle précédent, --load-epoch est disponible.
python . t rain.py --load-epoch 20 --config D: t f c kpt m lptts.jsonLes points de contrôle pré-entraînés sont relancés sur les versions.
Pour utiliser le modèle pré-entraîné, téléchargez des fichiers et décompressez-le. Les suivants sont un exemple de script.
from config import Config
from mlptts import MLPTextToSpeech
with open ( 'mlptts.json' ) as f :
config = Config . load ( json . load ( f ))
tts = MLPTextToSpeech ( config . model )
dummies = {
'text' : tf . zeros ([ 1 , 1 ], dtype = tf . int32 ),
'textlen' : tf . ones ([ 1 ], dtype = tf . int32 ),
'mel' : tf . zeros ([ 1 , 5 , config . model . mel ]),
'mellen' : tf . convert_to_tensor ([ 5 ], dtype = tf . int32 ),
}
# build
tts ( ** dummies )
# restore
tts . restore ( './mlptts_299.ckpt-1' ). expect_partial ()L'échantillon de code inférentiel est disponible sur inférence.py
Train LJSpeech 300 époques avec TF-Diffwave
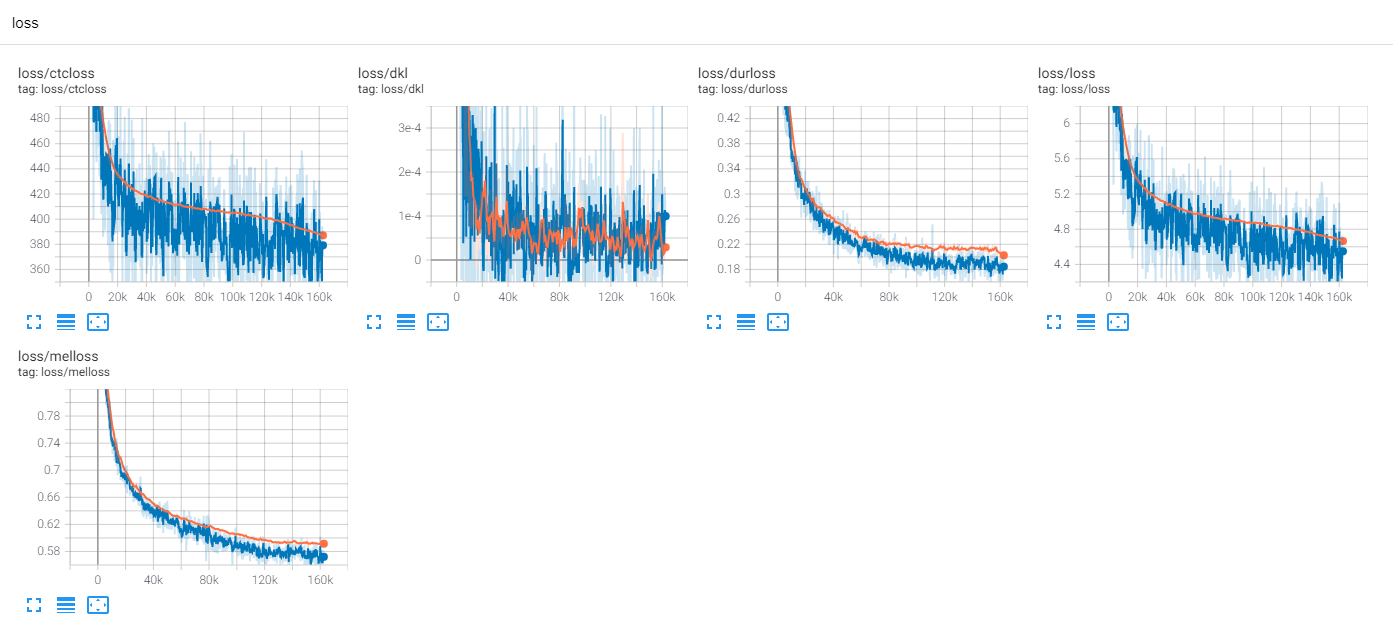
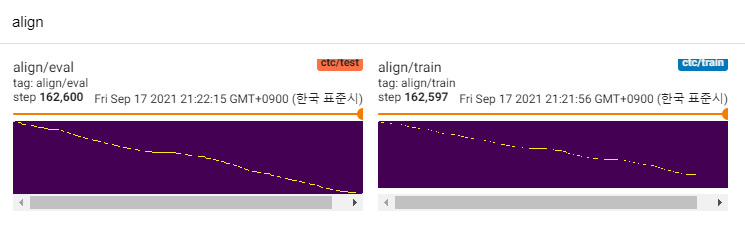

Jusqu'à présent, il y a beaucoup de recherches TTS, en particulier les modèles parallèles à la promenade de nourriture sont des tendances de nos jours. MLP-TTS en fait partie avec la distillation de la durée basée sur CTC, introduite par AlignTTS [6].
De l'autre côté, MLP-MIXER [1] et RESMLP [2] introduisent des architectures MLP uniquement pour les squelette NN.
Étant donné que le transformateur et les convolutions sont des épine dorsales majeures sur les champs TTS actuels, j'essaie de rechercher les autres épine dorsales qui peuvent être compatibles avec TTS. Et MLP-TTS est des expériences pour TTS avec des architectures basées sur MLP.
Le premier problème a été de savoir comment modéliser MLP pour les entrées de longueur dynamique.
MLP-MIXER [1] et RESMLP [2] Supposent un nombre fixe de correctifs et il est possible d'utiliser MLP sur l'axe temporel. Mais dans le cas TTS, car il accepte les entrées de taille dynamique, MLP avec des poids de taille fixe est incompatible avec ces tâches.
Je propose des architectures de type MLP de longueur dynamique, qui peuvent être trouvées sur mlp.py.
A. Convmlp
ConvMLP utilise une grande longueur MLP sur l'axe temporel. Pour faire face à la dynamicité temporelle, il fabrique des cadres de longueur fixe avec des régions superposées, qui peuvent être simplement trouvées sur STFT (Transform de Fourier à court terme). Après deux couches de MLP, il fonctionne sur le chevauchement et à ajouter pour faire la séquence unique.
Pour l'efficacité de calcul, la convolution 2D et la convolution transposée sont choisies, mais elle n'est pas pratique car une grande taille de mémoire est requise (lot x num_frames x frame_size). Et puisque nous choisissons la convolution transposée pour l'accélaration de Cuda de chevauchement et d'ajouté, la fonction de fenêtre ne peut pas être adaptable dans la séquence de fonctionnement (Ex. Hann Window).
B. TemporalConv
Il s'agit d'une convolution simple n'agit que sur l'axe temporel. Pour empêcher l'opération sur l'axe du canal, ConV2D avec [S, 1] Stride et [K, 1] le noyau est utilisé sur les caractéristiques d'entrée élargies [B, T, C, 1].
C. dytremporalmlp
Il calcule les poids dynamiques MLP à partir des fonctionnalités d'entrée. Pour plus de simplicité, MLP opère sur des fonctionnalités transposées et concaténées.
[B, 1, t, c] x [b, t, 1, c] = [b, t, t, cx2] -> [b, t, t, 1]
Il a deux différences philosophiques entre MLP-Mixer.
Tout d'abord, le mélangeur sépare le module en deux opérations exclusives, MLP au niveau du canal et MLP de niveau temporel. Mais DynTemporalMLP agit sur l'axe du canal pour calculer les poids dynamiques.
Deuxièmement, puisque MLP apprend les poids des positions individuelles, des informations de position supplémentaires sont inutiles. Mais DynTemporalMLP nécessite des incorporations de position car elle calcule simplement les poids à partir de deux caractéristiques de positions différentes, invariante de permutation.
Dans la ligne de base, MLP-TTS utilise une grande taille TemporalConv pour la transformation temporelle.
Après avoir libéré Beta-V0.1, certaines recherches sur le MLP de longueur dynamique sont introduites. Il peut être le seul choix de coder des fonctionnalités de longueur dynamique avec MLP.
Dans les expériences, il y a trop d'opérations denses et la procédure de formation était instable. J'ai rencontré de nombreux Nans en train.
Je vérifie certaines possibilités de stabiliser la procédure de formation.
A. Normalisation de la couche, MLP-Mixer
Comme Transformer (Vaswani et al., 2017), MLP-MIXER [1] utilise la normalisation de la couche sur chaque bloc résiduel. Dans MLPTTS, il ne peut pas stabiliser la formation.
B. Transform affine, RESMLP
Dans le papier de CAIT (Touvron et al., 2021), il introduit l'échelle des couches, qui utilise une transformée affine avec une petite valeur de facteur d'échelle. RESMLP [2] utilise l'échelle de couches et les MLPTT peuvent être stabilisés avec cette méthode.
C. DDI-ACTNORM, RESCALENNET
ResCalenenet [5] introduit la débiasing basée sur DDI (initialisation dépendante des données) pour la solution de relu mort. Inspiré par Rescalenenet, j'essaie de modifier la transformation affine avec la normalisation d'activation basée sur DDI (Glow, Kingma et al., 2018). Mais l'effet était minime et la clé était la petite valeur du facteur d'échelle.
Dans la ligne de base, MLP-TTS utilise une transformée affine avec la petite valeur du facteur d'échelle.
De FastSpeech (Ren et al., 2019), le modéleur de durée explicite est courant sur TTS dans le jour. MLP-TTS essaie également un modélisateur de durée explicite et de bout en bout avec un échantillonneur gaussien.
Le régulateur du tacotron parallèle 2 [4] est une contribution plus récente, mais elle est instable sur MLP-TTS. Je suppose que la raison pour laquelle le régulateur était possible sur le tacotron parallèle 2 était qu'elle suppose la localité avec une convolution dynamique de poids légère, de sorte que la monotonie de l'alignement peut être déduite des caractéristiques codées. Cependant, le MLP-TTS utilise la MLP et la convolution temporelle de grande taille, afin que l'hypothèse de localité puisse être libérée et que la monotonie ne peut pas être déduite des caractéristiques.
Je suppose donc explicitement la monotonie avec le mécanisme de lavage gaussien (Tacotron parallèle [3]), et il peut stabiliser la formation MLP-TTS.
Après avoir libéré Beta-V0.1, je pense que le train de bout en bout est toujours instable et que la distillation pourrait être la solution au problème d'alignement.
Il existe de nombreux modules de distillation, tels que le décodeur autorégressif (ex. JDI-T [7]), le décodeur basé sur le flux et la recherche d'alignement monotonique (= MAS, ex. Glow-TT [8]) et raffinage à partir d'encodages positionnels (Ex. Paranet [9]).
À l'exception de ceux d'entre eux, je suis intéressé à Aligntts [6]. Il utilise le réseau de densité de mélange et l'objectif de type CTC pour modéliser la relation entre le spectrogramme MEL et le texte, puis il trouve l'alignement avec le viterbi-algorithme.
MLP-TTS utilise également MDN et CTC pour modéliser les informations mutuelles entre le texte et le spectrogramme de MEL, et trouver l'alignement avec la recherche d'alignement monotone à partir de la matrice de vraisemblance au lieu de l'algorithme Viterbi. Ensuite, il est réduit à des durées et distillé aux modules de durateurs.
CTC + MAS est meilleur que l'UPSampleur gaussien, concernant la restauration du spectrogramme. Il peut générer des discours audibles humains et des échantillons peuvent être trouvés ici. J'estime que la raison de l'échec est que le gradient du durateur n'a pas reculé aux encodeurs de texte et que les encodeurs de texte ne pouvaient générer que des fonctionnalités de contexte.
Comme il ne s'agit que de modèles POC, les échantillons sont bruyants et la prononciation n'est pas claire. Il existe de nombreux facteurs qui peuvent être réglés et améliorés, tels que les modules MLP de longueur dynamique ou les paramètres de longueur du noyau, etc. Il sera difficile pour moi d'apporter d'autres améliorations (ce n'était que un projet de projet), mais j'apprécierais que quelqu'un publie PR. Merci pour votre attention.
[1] MLP-MIXER: une architecture All-MLP pour la vision, Tolstikhin et al., 2021.
[2] RESMLP: réseaux de restauration pour la classification d'image avec une formation économe en données, Touvron et al., 2021.
[3] Tacotron parallèle: TTS non autorégressif et contrôlable, Elias et al., 2020.
[4] Tacotron parallèle 2: un modèle TTS neuronal non autorégressif avec modélisation de durée différenable, Elias et al., 2021.
[5] est une normalisation indispensable pour la formation de réseaux de neurones profonds, Shao et al., 2020.
[6] Alignntts: Système de texte à dispection efficace efficace sans alignement explicite, Zheng et al., 2020.
[7] JDI-T: Transformateur informé de durée conjointe pour le texte à la dissection sans alignement explicite, Lim et al., 2020. [8] GLOW-TTS: A Generative Flow for Text-to-Speech via une recherche neurale monotonique, Kim et al., 2019.


