tf mlptts
v1.0: CTC-based alignment distillation
MLP-MixerベースのTTSのTensorFlow実装。
Python 3.7.9 Ubuntu Conda Environment、Recomations.txtでテストしました
LJスピーチデータセットをダウンロードするには、スクリプトの下で実行します。
データセットは、tfrecord形式で「〜/tensorflow_datasets」でダウンロードされます。ダウンロードディレクトリを変更する場合は、 LJSpeech initializerのdata_dirパラメーターを指定します。
from speechset . datasets import LJSpeech
# lj = LJSpeech(data_dir=path, download=True)
lj = LJSpeech ( download = True ) モデルをトレーニングするには、train.pyを実行します。
チェックポイントは、 TrainConfig.ckpt 、 TrainConfig.logのテンソルボードの概要に記述されます。
python train.py
tensorboard --logdir . l og RAWオーディオからモデルをトレーニングする場合は、オーディオディレクトリを指定し、フラグをオンにします--from-raw 。
python . t rain.py --data-dir ./LJSpeech-1.1/wavs --from-raw以前のチェックポイントからトレーニングを開始するには、 --load-epochが利用可能です。
python . t rain.py --load-epoch 20 --config D: t f c kpt m lptts.json事前に保護されたチェックポイントは、リリースに関連しています。
前処理されたモデルを使用するには、ファイルをダウンロードして解凍します。フォローはサンプルスクリプトです。
from config import Config
from mlptts import MLPTextToSpeech
with open ( 'mlptts.json' ) as f :
config = Config . load ( json . load ( f ))
tts = MLPTextToSpeech ( config . model )
dummies = {
'text' : tf . zeros ([ 1 , 1 ], dtype = tf . int32 ),
'textlen' : tf . ones ([ 1 ], dtype = tf . int32 ),
'mel' : tf . zeros ([ 1 , 5 , config . model . mel ]),
'mellen' : tf . convert_to_tensor ([ 5 ], dtype = tf . int32 ),
}
# build
tts ( ** dummies )
# restore
tts . restore ( './mlptts_299.ckpt-1' ). expect_partial ()InfereneNeceコードサンプルは、Incerence.pyで利用できます
tf-diffwaveを備えたljspeech 300エポックをトレーニングします
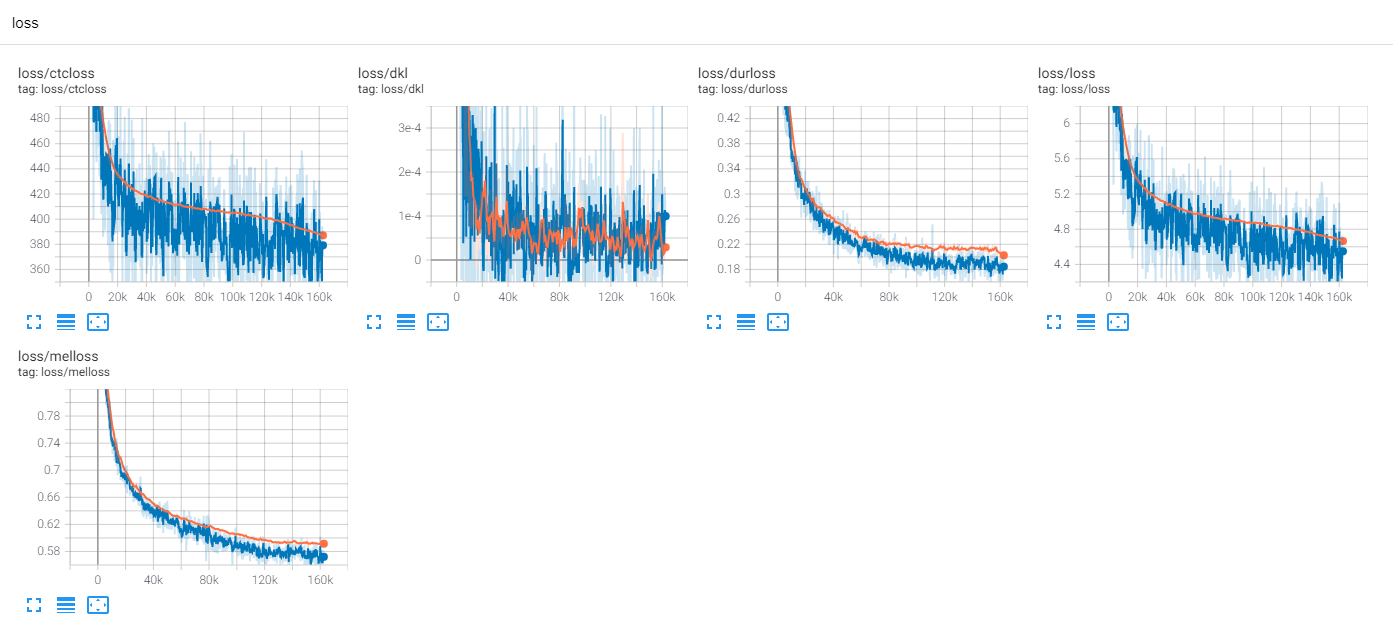
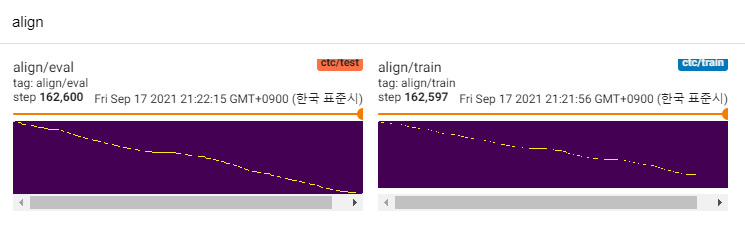

これまでのところ、多くのTTSの研究があります。特に、最近の並行フィードフォワードモデルはトレンドです。 MLP-TTSは、CTCベースの持続時間蒸留を持つそれらの1つであり、AlignTTS [6]によって導入されています。
一方、MLP-Mixer [1]およびRESMLP [2]は、NNバックボーンのMLPのみのアーキテクチャを導入します。
トランスと畳み込みは現在のTTSフィールドの主要なバックボーンであるため、TTSと互換性のある他のバックボーンを調査しようとします。 MLP-TTSは、MLPベースのアーキテクチャを使用したTTSの実験です。
最初の問題は、動的長さの入力のためにMLPをモデル化する方法でした。
MLP-Mixer [1]およびRESMLP [2]は固定数のパッチを想定しており、時間軸でMLPを使用することが可能です。しかし、TTSの場合、動的サイズの入力を受け入れるため、固定サイズの重みを持つMLPはこれらのタスクと互換性がありません。
mlp.pyで見つけることができる動的長さのMLPのようなアーキテクチャを提案します。
A. convmlp
ConvMLP 、時間軸に広い長さMLPを使用します。一時的なダイナミティに対処するために、オーバーラップ領域の固定長フレームを作成します。これは、STFT(短期フーリエ変換)で簡単に見つけることができます。 2つのMLP層の後、オーバーラップアンドアドドを動作させて単一のシーケンスを作成します。
計算効率のために、2D畳み込みと転置された畳み込みが選択されますが、大きなサイズのメモリが必要なため、実用的ではありません(バッチx num_frames x frame_size)。また、オーバーラップアンドアドレスのCUDAアクセロレーションのために転置された畳み込みを選択するため、窓関数は動作シーケンスで適応できません(例:Hann Window)。
B. TumealConv
それは単純な畳み込みであり、時間軸にのみ作用します。チャネル軸上の動作を防ぐために、[S、1]ストライドと[k、1]カーネルを使用したConv2dは、拡張された入力機能[B、T、C、1]で使用されます。
C. dyntemporalmlp
入力機能から動的なMLP重みを計算します。簡単にするために、MLPは転置された連結機能と連結機能を操作します。
[b、1、t、c] x [b、t、1、c] = [b、t、t、cx2] - > [b、t、t、1]
MLP-Mixerの間に2つの哲学的な違いがあります。
まず、ミキサーはモジュールを2つの排他的操作、チャネルレベルMLPと時間レベルのMLPに分離します。しかし、 DynTemporalMLP 、動的な重みを計算するためにチャネル軸に作用します。
第二に、MLPは個々の位置からの重みを学習するため、追加の位置情報は不要です。しかし、 DynTemporalMLP 、異なる位置の2つの特徴、順列不変の重みを計算するだけなので、位置埋め込みを必要とします。
ベースラインでは、MLP-TTSは、時間変換のために大きなサイズのTemporalConvを使用します。
Beta-V0.1をリリースした後、動的長のMLPに関するいくつかの研究が導入されています。 MLPで動的長さの機能をエンコードすることができます。
実験では、密な操作が多すぎてトレーニング手順が不安定でした。電車で多くのナンに会いました。
トレーニング手順を安定させるためにいくつかの可能性をチェックします。
A.レイヤー正規化、MLP-Mixer
トランス(Vaswani et al。、2017)と同様に、MLP-Mixer [1]は、各残差ブロックで層正規化を使用します。 MLPTTSでは、トレーニングを安定させることはできません。
B. Affine-Transform、resmlp
Caitの紙(Touvron et al。、2021)では、スケール係数の小さな値でアフィン変換を使用するレイヤースケールを導入します。 resmlp [2]はレイヤースケールを使用し、MLPTTはこの方法で安定化できます。
C. ddi-actnorm、Recalenet
Recalenet [5]は、DDI(データ依存性初期化)に基づいたDeebiasingを導入し、死んだReluの解決策を導入します。 Recalenetに触発されて、私はDDIベースの活性化正規化によるアフィン変換を変更しようとしています(Glow、Kingma et al。、2018)。しかし、効果は最小限であり、キーはスケーリング係数のわずかな値でした。
ベースラインでは、MLP-TTSはスケーリング係数の小さな値とアフィン変換を使用します。
FastSpeech(Ren et al。、2019)から、明示的な持続時間モデラーは、最近のTTSで一般的です。 MLP-TTSは、ガウスアップサンプラーで明示的な持続時間モデラーとエンドツーエンドを試みます。
パラレルタコトロン2 [4]からのレギュレーターは、より最近の貢献ですが、MLP-TTSでは不安定です。平行タコトロン2でレギュレーターが可能であった理由の私の推測では、軽量の動的畳み込みを備えた局所性を想定しているため、アラインメントの単調性をエンコードされた特徴から推測できます。ただし、MLP-TTSはMLPと大規模な時間的畳み込みを使用するため、局所性の仮定を解放し、単調性を特徴から推測することはできません。
したがって、ガウスアップサンプリングメカニズム(Parallel Tacotron [3])との単調性を明示的に仮定し、MLP-TTSトレーニングを安定させることができます。
Beta-V0.1をリリースした後、エンドツーエンドの列車はまだ不安定であり、蒸留がアライメント問題の解決策になる可能性があると思います。
自己回帰デコーダー(Ex。JDI-T [7])、フローベースのデコーダーおよび単調アライメント検索(= MAS、Ex。Glow-TTS [8])、および位置エンコーディングからの改良(Ex。Paranet[9])など、多くの蒸留モジュールがあります。
それらのものを除いて、私はAlignttsに興味があります[6]。メルスペクトルとテキストの関係をモデル化するために、混合密度ネットワークとCTC様の目的を使用し、Viterbi-Algorithmとのアライメントを見つけます。
MLP-TTSは、MDNとCTCを使用して、テキストとMELスペクトログラムの間の相互情報をモデル化し、ViterBiアルゴリズムの代わりに尤度マトリックスからの単調整列検索とのアライメントを見つけます。その後、期間に縮小され、デュレーターモジュールに蒸留されます。
CTC+MASは、スペクトログラムの復元に関して、ガウスアップサンプラーよりも優れています。ここで人間の可聴スピーチを生成し、サンプルを見つけることができます。障害の理由は、デュレーターの勾配がテキストエンコーダーに後ろ向きにならず、テキストエンコーダーがコンテキスト機能のみを生成できることです。
POCモデルであるため、サンプルは騒々しく、発音は不明です。動的長さのMLPモジュールやカーネルの長さパラメーターなど、調整して改善できる多くの要因があります。さらに改善するのは難しいでしょう(単なる期間プロジェクトでした)が、誰かがPRを投稿した場合は感謝します。ご協力いただきありがとうございます。
[1] MLP-Mixer:VisionのためのAll-MLPアーキテクチャ、Tolstikhin et al。、2021。
[2] RESMLP:データ効率の高いトレーニングを使用した画像分類のためのFeedForwardネットワーク、Touvron et al。、2021。
[3]パラレルタコトロン:非自動性および制御可能なTTS、Elias et al。、2020。
[4]並列タコトロン2:微分持続時間モデリングを備えた非自動性神経TTSモデル、Elias et al。、2021。
[5]は、深いニューラルネットワークのトレーニングに不可欠な正規化、Shao et al。、2020。
[6] Aligntts:明示的なアライメントなしの効率的なフィードフォワードテキストからスピーチへのシステム、Zheng et al。、2020。
[7] JDI-T:明示的なアライメントなしでテキストからスピーチへの共同訓練期間に通知された変圧器、Lim et al。、2020。


