tf mlptts
v1.0: CTC-based alignment distillation
MLP 혼합기 기반 TTS의 텐서 플로 구현.
Python 3.7.9 Ubuntu Conda 환경, 요구 사항 .txt
lj-speech 데이터 세트를 다운로드하려면 스크립트에서 실행하십시오.
데이터 세트는 '~/tensorflow_datasets'로 tfrecord 형식으로 다운로드됩니다. 다운로드 디렉토리를 변경하려면 LJSpeech 이니셜 라이저의 data_dir 매개 변수를 지정하십시오.
from speechset . datasets import LJSpeech
# lj = LJSpeech(data_dir=path, download=True)
lj = LJSpeech ( download = True ) 모델을 훈련 시키려면 Train.py를 실행하십시오.
Checkpoint는 TrainConfig.ckpt , Tensorboard TrainConfig.log 에 작성됩니다.
python train.py
tensorboard --logdir . l og Raw Audio에서 모델을 훈련 시키려면 오디오 디렉토리를 지정하고 --from-raw 을 켜십시오.
python . t rain.py --data-dir ./LJSpeech-1.1/wavs --from-raw 이전 체크 포인트에서 훈련을 시작하려면 --load-epoch 사용할 수 있습니다.
python . t rain.py --load-epoch 20 --config D: t f c kpt m lptts.json사전 조정 체크 포인트는 릴리스에 상관됩니다.
사전 치료 된 모델을 사용하려면 파일을 다운로드하고 압축을 풀습니다. 다음은 샘플 스크립트입니다.
from config import Config
from mlptts import MLPTextToSpeech
with open ( 'mlptts.json' ) as f :
config = Config . load ( json . load ( f ))
tts = MLPTextToSpeech ( config . model )
dummies = {
'text' : tf . zeros ([ 1 , 1 ], dtype = tf . int32 ),
'textlen' : tf . ones ([ 1 ], dtype = tf . int32 ),
'mel' : tf . zeros ([ 1 , 5 , config . model . mel ]),
'mellen' : tf . convert_to_tensor ([ 5 ], dtype = tf . int32 ),
}
# build
tts ( ** dummies )
# restore
tts . restore ( './mlptts_299.ckpt-1' ). expect_partial ()Inferenece 코드 샘플은 추론에서 사용할 수 있습니다
tf-diffwave로 ljspeech 300 에포크를 훈련시킵니다
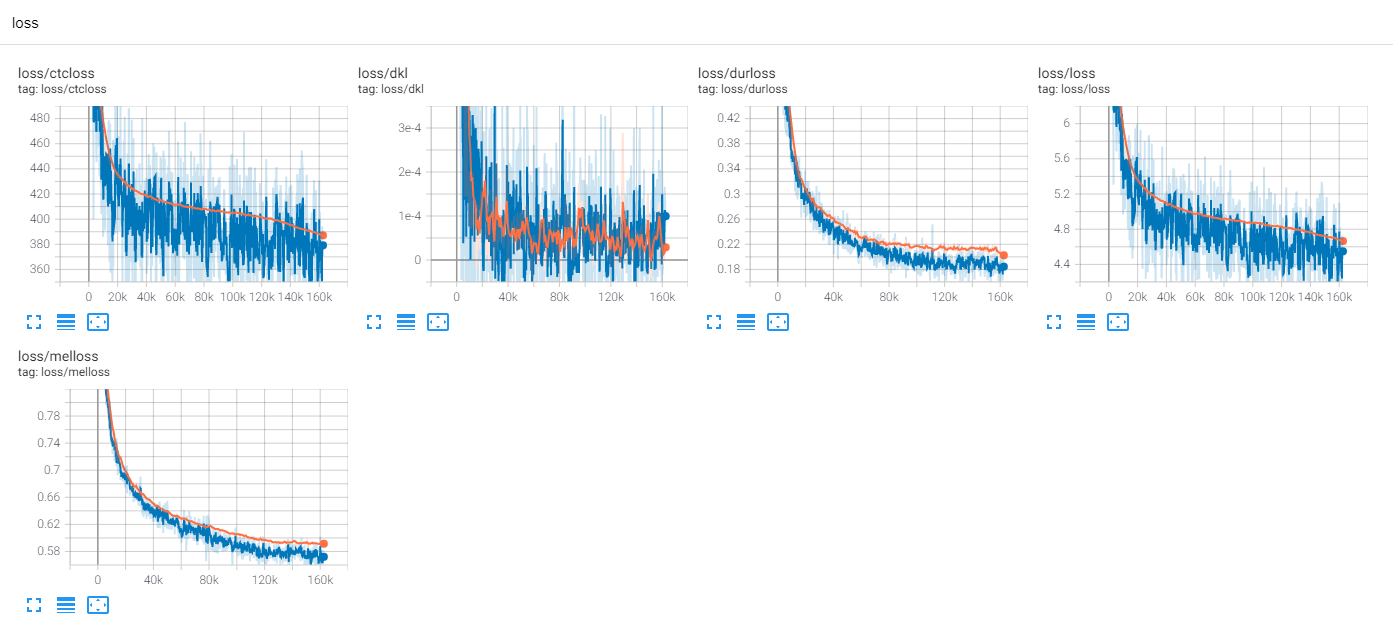

지금까지 많은 TTS 연구가 있으며, 특히 병렬 피드 포워드 모델이 요즘 트렌드입니다. MLP-TTS는 Aligntts [6]에 의해 도입 된 CTC 기반 지속 시간 증류를 가진 그 중 하나입니다.
다른 한편으로, MLP-Mixer [1] 및 RESMLP [2]는 NN 백본 용 MLP 전용 아키텍처를 소개합니다.
변압기와 컨볼 루션은 현재 TTS 필드의 주요 백본이므로 TTS와 호환 될 수있는 다른 백본을 연구하려고합니다. MLP-TTS는 MLP 기반 아키텍처를 갖는 TTS에 대한 실험이다.
첫 번째 문제는 동적 길이 입력을 위해 MLP를 모델링하는 방법이었습니다.
MLP-Mixer [1] 및 RESMLP [2]는 고정 된 수의 패치를 가정하고 시간 축에서 MLP를 사용할 수 있습니다. 그러나 TTS의 경우 동적 크기 입력을 허용하므로 고정 크기 가중치가있는 MLP는 이러한 작업과 호환되지 않습니다.
MLP.Py에서 찾을 수있는 동적 길이의 MLP 유사 아키텍처를 제안합니다.
A. convmlp
ConvMLP 시간 축에서 다양한 길이 MLP를 사용합니다. 시간적 동적을 다루기 위해, 그것은 겹친 영역이있는 고정 길이 프레임을 만들어 STFT에서 간단히 찾을 수 있습니다 (단기 푸리에 변환). 2 개의 MLP 층 후, 단일 시퀀스를 만들기 위해 오버랩 및 add를 작동시킵니다.
계산 효율을 위해, 2D 컨볼 루션 및 변환 컨볼 루션이 선택되지만, 큰 크기의 메모리가 필요하기 때문에 실용적이지 않습니다 (Batch x num_frames x frame_size). 그리고 우리는 오버랩 및 add의 Cuda-Accelaration을위한 전치 컨볼 루션을 선택하기 때문에, 작업 순서 (예 : Hann Window)에서는 창 함수가 적응할 수 없다.
B. TempalConv
단순한 컨볼 루션은 시간 축에만 작용합니다. 채널 축에서의 작동을 방지하기 위해 [s, 1] 보폭으로 concl2d 및 [k, 1] 커널은 확장 된 입력 특징 [b, t, c, 1]에 사용됩니다.
C. Dyntemporalmlp
입력 기능에서 동적 MLP 가중치를 계산합니다. 단순화하기 위해 MLP는 전치 및 연결 기능에서 작동합니다.
[b, 1, t, c] x [b, t, 1, c] = [b, t, t, cx2] -> [b, t, t, 1]
그것은 MLP 믹서 사이에 두 가지 철학적 차이가 있습니다.
먼저 믹서는 모듈을 2 개의 독점 작업, 채널 레벨 MLP 및 시간적 수준 MLP로 분리합니다. 그러나 DynTemporalMLP 동적 무게를 계산하기 위해 채널 축에 작용합니다.
둘째, MLP는 개별 위치에서 가중치를 배우기 때문에 추가 위치 정보는 불필요합니다. 그러나 DynTemporalMLP 위치 적 내장이 필요합니다. 다른 위치의 두 가지 특징 인 순열 불변의 두 가지 특징에서 가중치를 계산하기 때문입니다.
기준선에서 MLP-TTS는 시간 변형을 위해 대형 TemporalConv 사용합니다.
베타 -V0.1을 출시 한 후 동적 길이 MLP에 대한 일부 연구가 도입됩니다. MLP로 동적 길이 기능을 인코딩하는 것이 하나의 선택 일 수 있습니다.
실험에서는 너무 많은 조밀 한 작업이 있으며 훈련 절차가 불가능했습니다. 나는 기차에서 많은 Nans를 만났다.
나는 훈련 절차를 안정화시킬 가능성을 확인합니다.
A. 층 정규화, MLP 믹서
변압기 (Vaswani et al., 2017)와 마찬가지로 MLP-Mixer [1]은 각 잔류 블록에서 층 정규화를 사용합니다. MLPTTS에서는 훈련을 안정화시킬 수 없습니다.
B. Affine-Transform, Resmlp
Cait의 종이 (Touvron et al., 2021)에서, 척도 값의 작은 값으로 아핀 변환을 사용하는 Layerscale을 소개합니다. RESMLP [2]는 LayersCale을 사용하고 MLPTTS는이 방법으로 안정화 될 수 있습니다.
C. ddi-actnorm, rescalenet
Rescalenet [5]는 Dead Relu의 솔루션에 대한 DDI (데이터 의존적 초기화) 기반 토론을 소개합니다. Rescalenet에서 영감을 얻은 나는 DDI 기반 활성화 정규화로 아핀 변환을 변경하려고 노력합니다 (Glow, Kingma et al., 2018). 그러나 효과는 최소화되었고 열쇠는 스케일링 계수의 작은 값이었습니다.
기준선에서 MLP-TTS는 스케일링 계수의 작은 값으로 Affine 변환을 사용합니다.
FastSpeech (Ren et al., 2019)에서 명시적인 기간 모델러는 오늘날 TT에서 일반적입니다. MLP-TTS는 또한 가우스 업 샘플러와 함께 명시적인 지속 시간 모델러 및 엔드 투 엔드를 시도합니다.
병렬 타코트론 2 [4]의 조절제는보다 최근의 기여이지만 MLP-TTS에서는 불안정합니다. 평행 타코트론 2에서 조절기가 가능한 이유에 대한 내 추측은 광량 동적 컨볼 루션을 갖는 지역성을 가정하여 인코딩 된 특징으로부터 정렬의 단조성을 추론 할 수 있기 때문입니다. 그러나 MLP-TTS는 MLP와 대형 시간적 컨볼 루션을 사용하여 지역 가정이 풀릴 수 있고 특징으로부터 단일성을 추론 할 수 없도록합니다.
그래서 나는 가우시안의 상향 샘플링 메커니즘 (평행 타코트론 [3])과의 단조성을 명시 적으로 가정하고 MLP-TTS 훈련을 안정화시킬 수 있습니다.
베타 -V0.1을 릴리스 한 후, 엔드 투 엔드 트레인이 여전히 불안정하고 증류가 정렬 문제에 대한 해결책이 될 수 있다고 생각합니다.
자동 회귀 디코더 (예 : JDI-T [7]), 흐름 기반 디코더 및 단조 적 정렬 검색 (= MAS, ex. glow-tts [8]) 및 위치 인코딩 (Ex. Paranet [9])과 같은 많은 증류 모듈이 있습니다.
그들 중 사람들을 제외하고, 나는 aligntts [6]에 관심이있다. Mel-Spectrogram과 텍스트 간의 관계를 모델링하기 위해 Mixtenity Network와 CTC와 같은 목표를 사용하여 Viterbi algorithm과의 정렬을 찾습니다.
MLP-TTS는 또한 텍스트와 멜 스피어 그램 사이의 상호 정보를 모델링하기 위해 MDN 및 CTC를 사용하고 Viterbi 알고리즘 대신 가능성 매트릭스에서 단조 적 정렬 검색과 정렬을 찾습니다. 그런 다음 기간으로 축소되고 방향 모듈로 증류됩니다.
CTC+MAS는 스펙트로 그램 복원과 관련하여 가우스 업 샘플러보다 낫습니다. 인간의 가청 연설을 생성 할 수 있으며 여기에서 찾을 수 있습니다. 실패의 이유는 내구체의 구배가 텍스트 인코더로 뒤로 물러나지 않았고 텍스트 인코더는 컨텍스트 기능 만 생성 할 수 있기 때문입니다.
그것은 단지 POC 모델이기 때문에 샘플은 시끄럽고 발음은 불분명합니다. 동적 길이 MLP 모듈 또는 커널 길이 매개 변수 등과 같이 조정 및 개선 할 수있는 많은 요소가 있습니다. 추가 개선을 수행하기가 어렵지만 (단지 용어 프로젝트 일뿐) 누군가가 PR을 게시하더라도 감사하겠습니다. 관심을 가져 주셔서 감사합니다.
[1] MLP-MIXER : Vision 용 All-MLP 아키텍처, Tolstikhin et al., 2021.
[2] RESMLP : 데이터 효율적인 교육을 통한 이미지 분류를위한 피드 포워드 네트워크, Touvron et al., 2021.
[3] 병렬 타코트론 : 비 유사성 및 제어 가능한 TTS, Elias et al., 2020.
[4] 병렬 타코트론 2 : 차별화 가능한 지속 시간 모델링을 갖는 비 유사성 신경 TTS 모델, Elias et al., 2021.
[5]는 심층 신경망을 훈련시키는 데 필수화 할 수 없다, Shao et al., 2020.
[6] Aligntts : 명시 적 정렬없이 효율적인 피드 포워드 텍스트 음성 음성 시스템, Zheng et al., 2020.
[7] JDI-T : 명시 적 정렬없이 텍스트 음성 연설에 대한 공동으로 훈련 된 기간 정보 변압기, Lim et al., 2020.


