Cross Speaker Emotion Transfer
v0.2.0
基于扬声器条件层归一化和文本到语音中的半监督培训,BOCTEDANCE的跨语言情绪转移的实施。
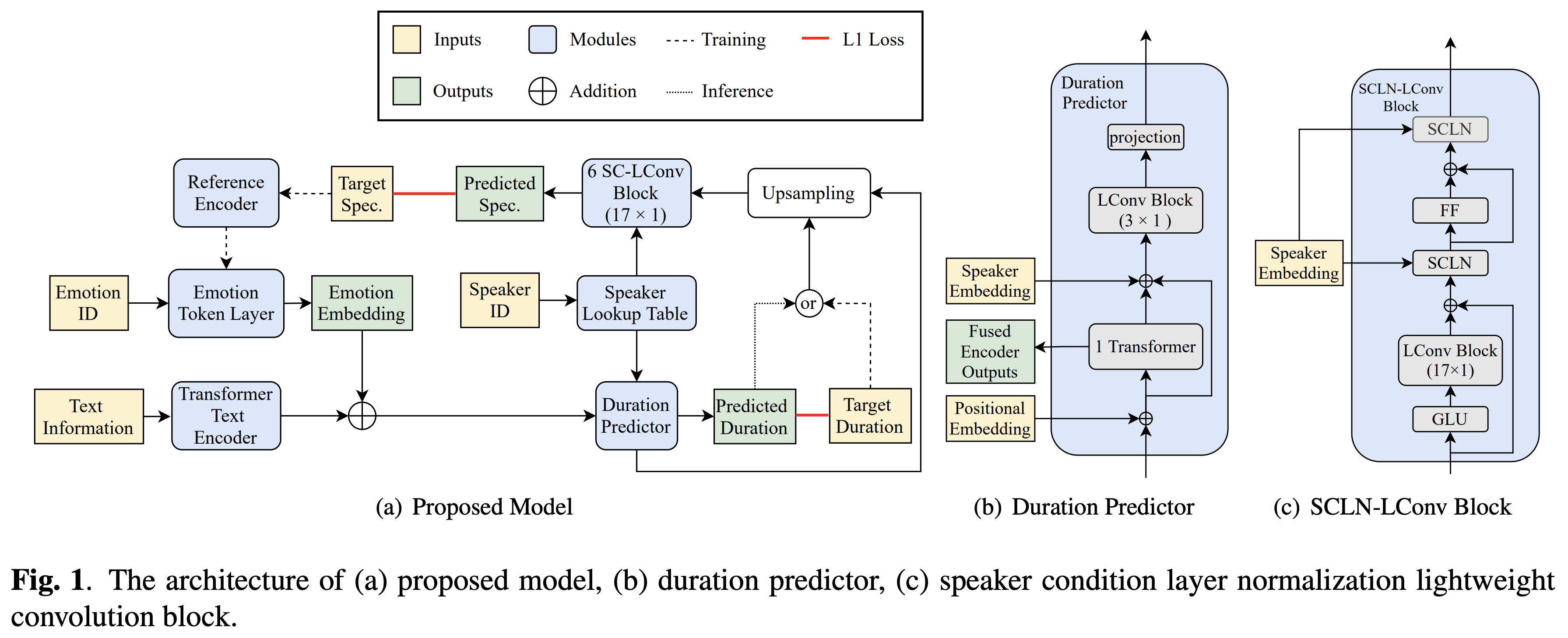
音频样本可在 /演示中找到。
数据集指的是以下文档中的数据集的名称,例如RAVDESS 。
您可以使用
pip3 install -r requirements.txt
另外,安装FairSeq(官方文档,GitHub)以利用LConvBlock 。请在此处检查以解决安装它的任何问题。请注意, Dockerfile是为Docker用户提供的,但是您必须手动安装Fairseq。
您必须下载验证的型号,并将它们放入output/ckpt/DATASET/ 。
要从参考音频中提取软性令牌,请运行
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --speaker_id SPEAKER_ID --ref_audio REF_AUDIO_PATH --restore_step RESTORE_STEP --mode single --dataset DATASET
或者,要从情感ID中使用硬情绪令牌,请运行
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --speaker_id SPEAKER_ID --emotion_id EMOTION_ID --restore_step RESTORE_STEP --mode single --dataset DATASET
可以在preprocessed_data/DATASET/speakers.json上找到学习的扬声器的字典,并且生成的话语将放在output/result/ 。
也支持批次推理,尝试
python3 synthesize.py --source preprocessed_data/DATASET/val.txt --restore_step RESTORE_STEP --mode batch --dataset DATASET
综合preprocessed_data/DATASET/val.txt中的所有话语。请注意,在此模式下仅支持来自给定情绪ID的硬情绪令牌。
支持的数据集是
您自己的语言和数据集可以在此处进行调整。
对于带有外部扬声器嵌入式的多扬声器TT ,下载cacknn softmax+三胞胎预算的Philipperemy DeepSpeaker的扬声器嵌入模型,并将其定位在./deepspeaker/pretrained_models/中。
跑步
python3 prepare_align.py --dataset DATASET
用于一些准备工作。
对于强制对准,蒙特利尔强制对准器(MFA)用于获得发音和音素序列之间的比对。此处提供了数据集的预提取对齐。您必须在preprocessed_data/DATASET/TextGrid/中解压缩文件。或者,您可以自己运行对准器。
之后,通过
python3 preprocess.py --dataset DATASET
培训您的模型
python3 train.py --dataset DATASET
有用的选项:
--use_amp参数附加到上述命令中。CUDA_VISIBLE_DEVICES=<GPU_IDs> 。使用
tensorboard --logdir output/log
在您的本地主机上提供张板。显示了损耗曲线,合成的MEL光谱图和音频。
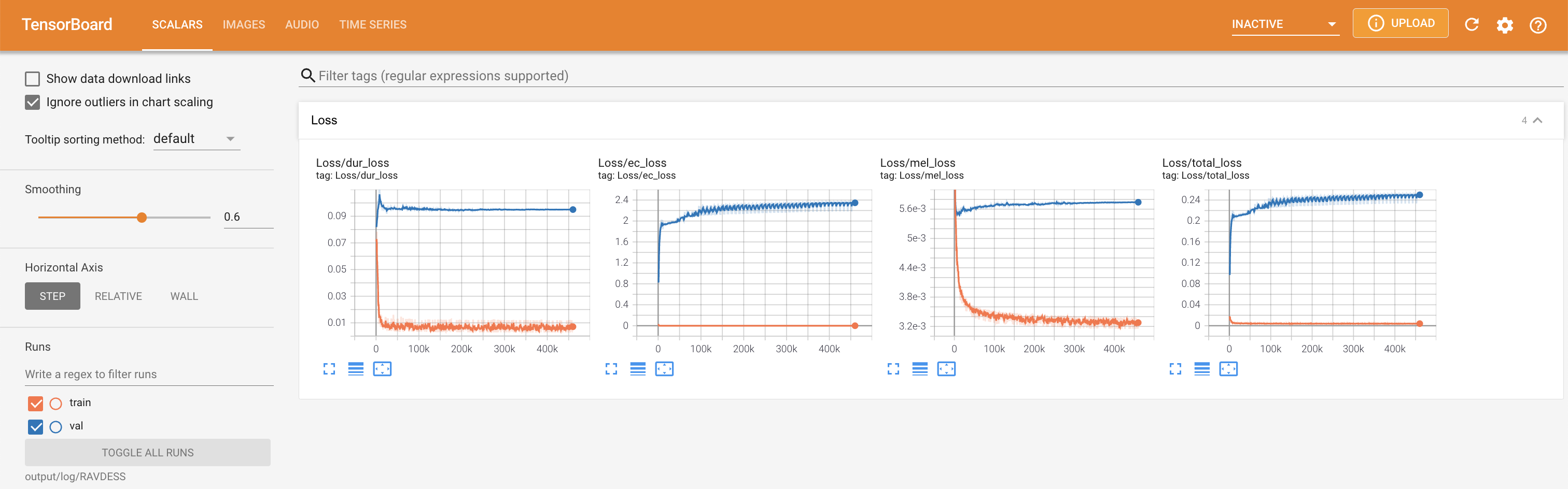
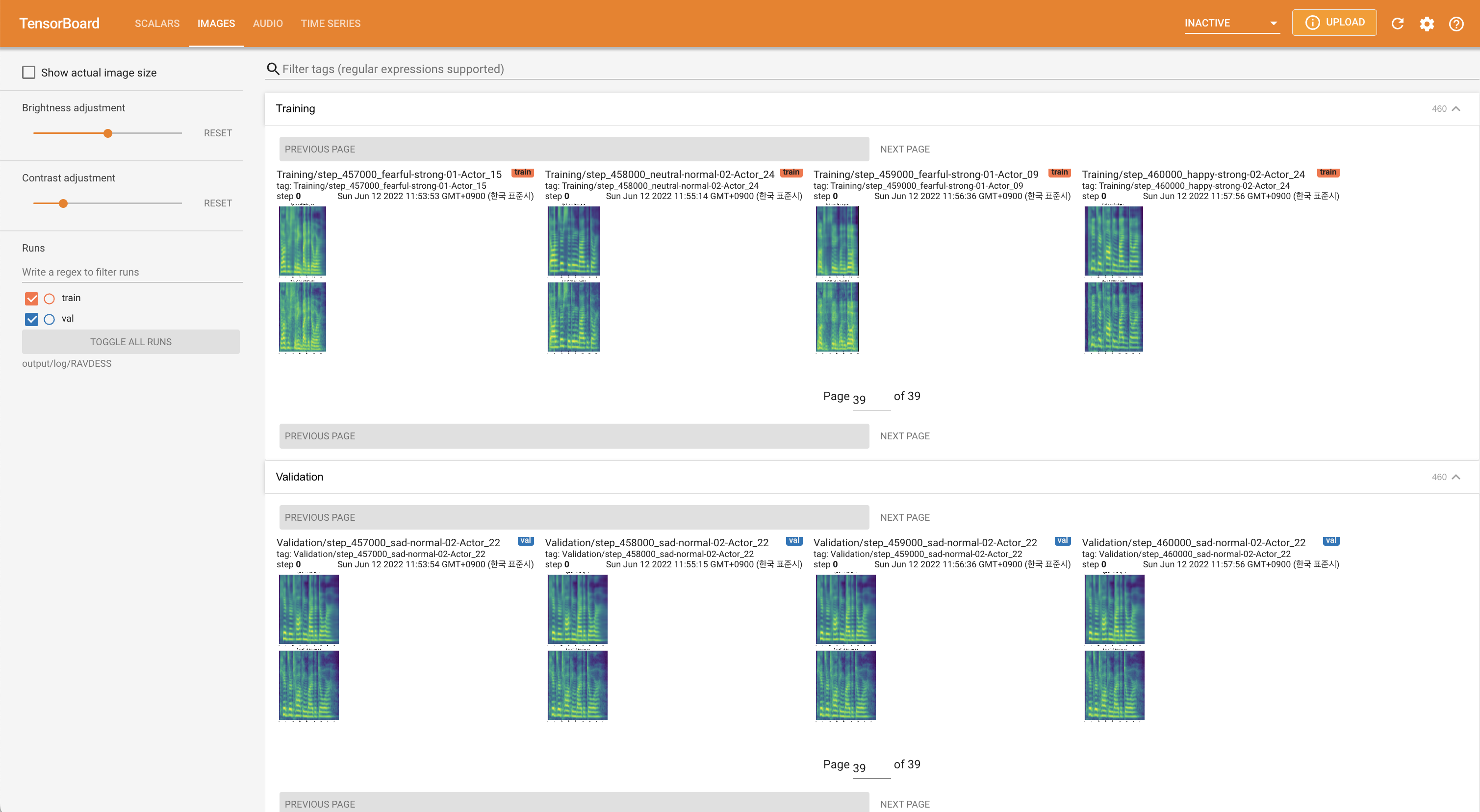
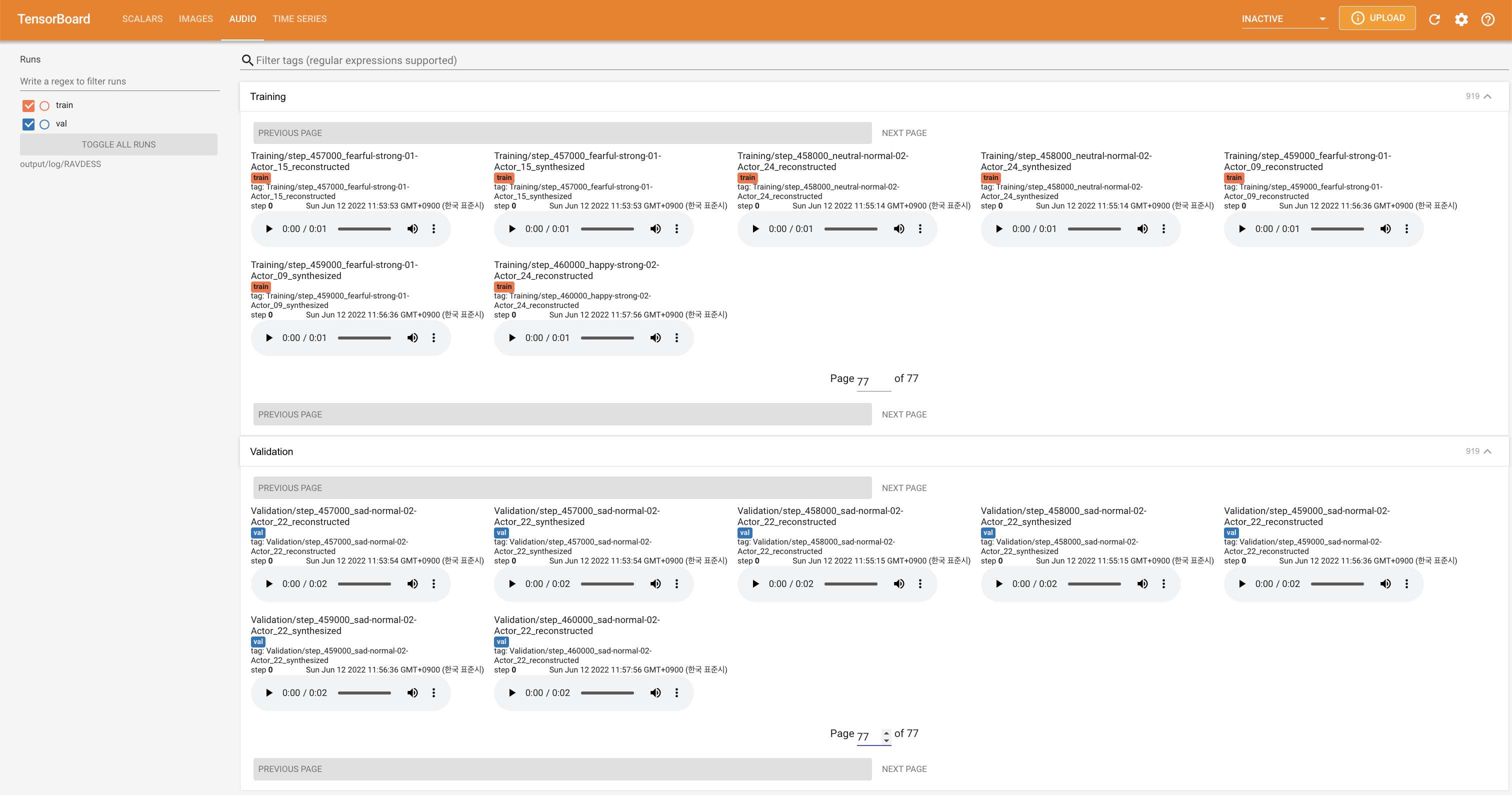
'none'和'DeepSpeaker'之间)进行切换。
请用“引用此存储库”的“关于部分”(主页的右上角)引用此存储库。


