Cross Speaker Emotion Transfer
v0.2.0
تنفيذ Pytorch لنقل العاطفة المتقاطع من Bytedance استنادًا إلى تطبيع طبقة حالة السماعة والتدريب شبه الخاضع للإشراف في نص إلى كلام.
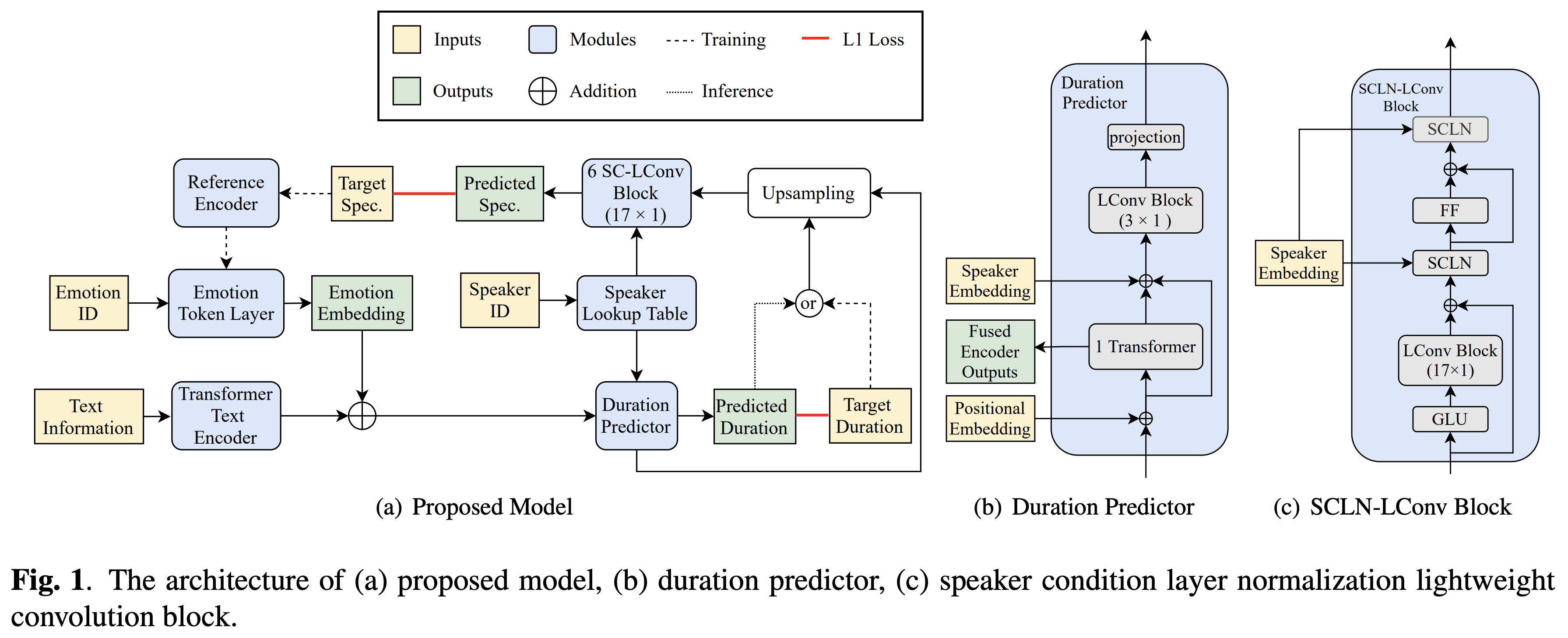
عينات الصوت متوفرة في /العرض التوضيحي.
تشير مجموعة البيانات إلى أسماء مجموعات البيانات مثل RAVDESS في المستندات التالية.
يمكنك تثبيت تبعيات Python مع
pip3 install -r requirements.txt
أيضًا ، قم بتثبيت FairSeq (المستند الرسمي ، Github) لاستخدام LConvBlock . يرجى التحقق هنا لحل أي مشكلة عند تثبيتها. لاحظ أنه يتم توفير Dockerfile لمستخدمي Docker ، ولكن يجب عليك تثبيت FairSeq يدويًا.
يجب عليك تنزيل النماذج المسبقة ووضعها في output/ckpt/DATASET/ .
لاستخراج الرموز العاطفية الناعمة من صوت مرجعي ، قم بتشغيل
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --speaker_id SPEAKER_ID --ref_audio REF_AUDIO_PATH --restore_step RESTORE_STEP --mode single --dataset DATASET
أو ، لاستخدام الرموز العاطفية الصعبة من معرف العاطفة ، قم بالتشغيل
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --speaker_id SPEAKER_ID --emotion_id EMOTION_ID --restore_step RESTORE_STEP --mode single --dataset DATASET
يمكن العثور على قاموس مكبرات الصوت المستفادة في preprocessed_data/DATASET/speakers.json output/result/
يتم دعم استنتاج الدُفعات أيضًا ، حاول
python3 synthesize.py --source preprocessed_data/DATASET/val.txt --restore_step RESTORE_STEP --mode batch --dataset DATASET
لتوليف جميع الكلمات في preprocessed_data/DATASET/val.txt . يرجى ملاحظة أنه يتم دعم الرموز العاطفية القاسية فقط من معرف العاطفة المعطى في هذا الوضع.
مجموعات البيانات المدعومة
يمكن تكييف لغتك ومجموعة البيانات الخاصة بك هنا.
للحصول على TTS متعددة الكلام مع مكبر صوت خارجي ، قم بتنزيل نموذج RAVERMAX+TREPLET PRESTERED من Deepspeaker من Philipperemy لدمجه ويحدد موقعه ./deepspeaker/pretrained_models/
يجري
python3 prepare_align.py --dataset DATASET
لبعض الاستعدادات.
بالنسبة للمحاذاة القسرية ، يتم استخدام Montreal القسري Aligner (MFA) للحصول على المحاذاة بين الكلمات وتسلسلات الصوت. يتم توفير محاذاة مسبقًا لمجموعات البيانات هنا. يجب عليك إلغاء ضغط الملفات في preprocessed_data/DATASET/TextGrid/ . بالتناوب ، يمكنك تشغيل جهاز Aligner بنفسك.
بعد ذلك ، قم بتشغيل البرنامج النصي المسبق
python3 preprocess.py --dataset DATASET
تدريب النموذج الخاص بك مع
python3 train.py --dataset DATASET
خيارات مفيدة:
--use_amp إلى الأمر أعلاه.CUDA_VISIBLE_DEVICES=<GPU_IDs> في بداية الأمر أعلاه.يستخدم
tensorboard --logdir output/log
لخدمة Tensorboard على مضيفك المحلي. يتم عرض منحنيات الخسارة ، وتوليف الطيف الطيف ، والسمعات.
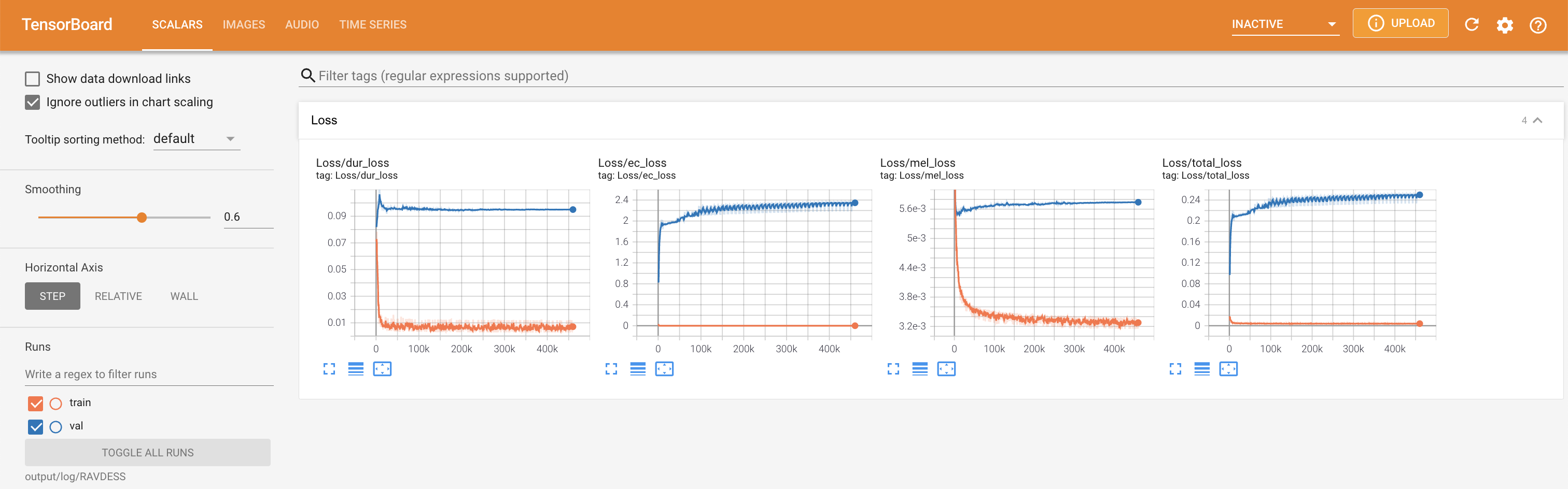
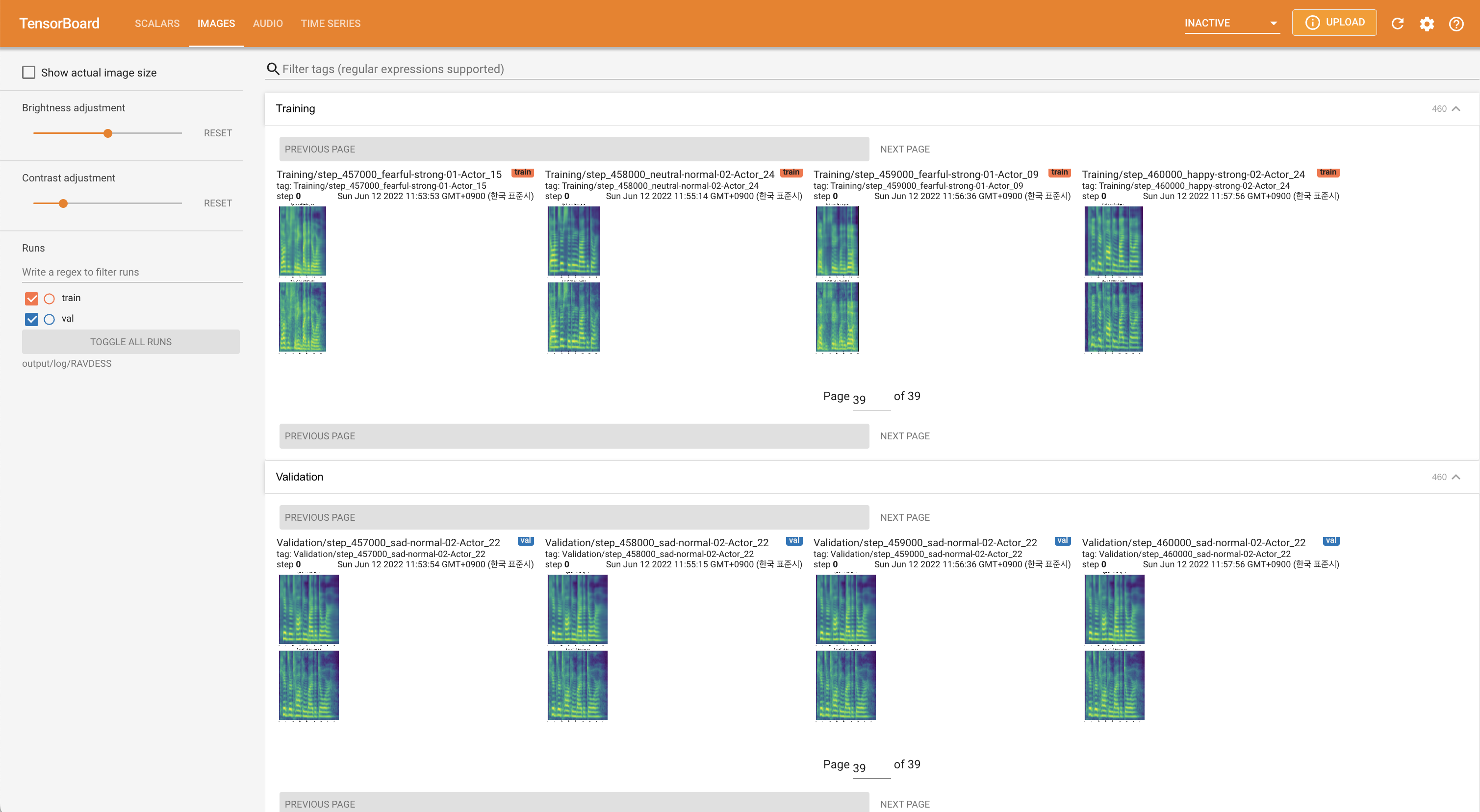
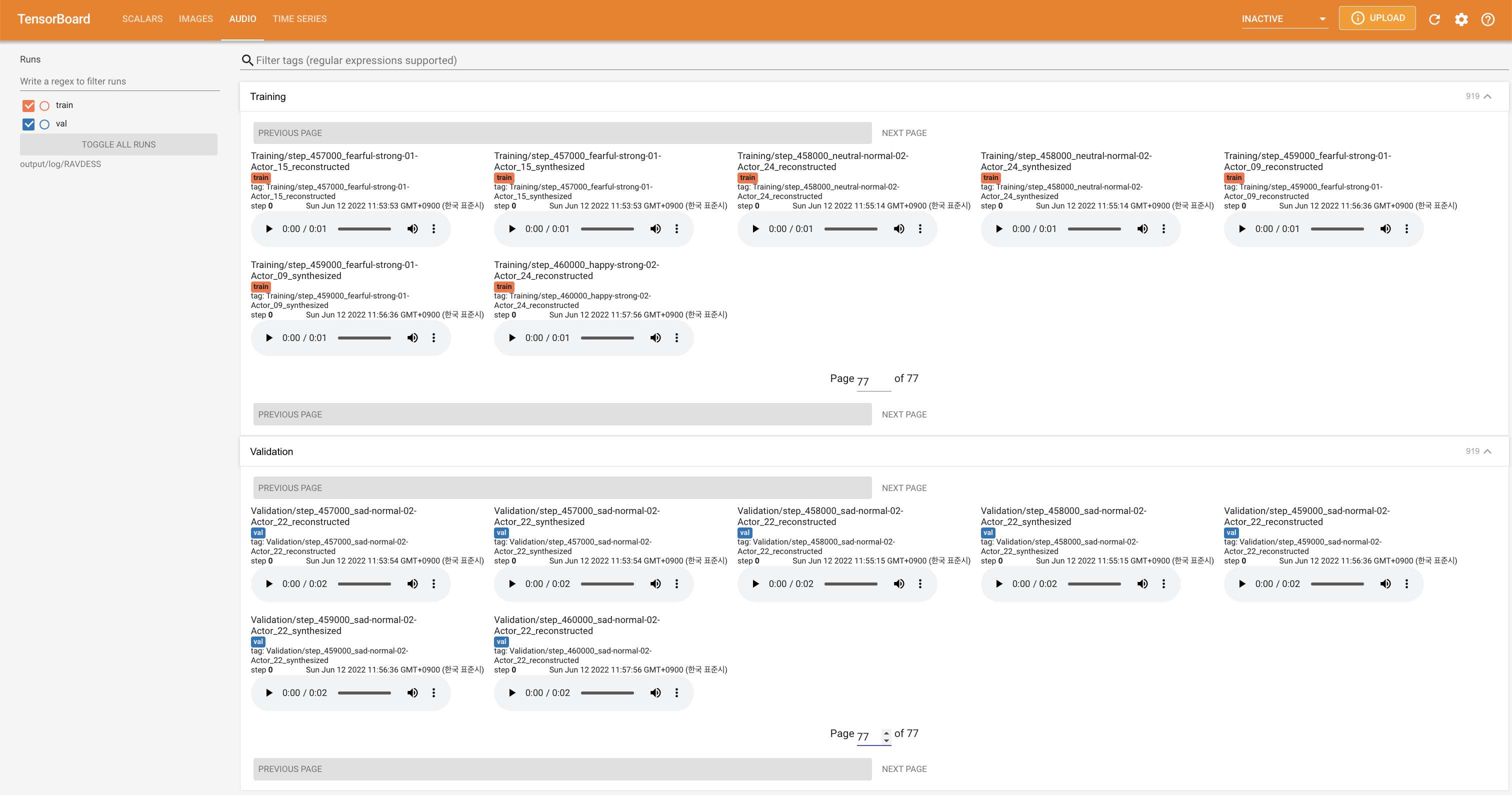
'none' و 'DeepSpeaker' ).
يرجى الاستشهاد بهذا المستودع من خلال "استشهد بهذا المستودع" من القسم (أعلى يمين الصفحة الرئيسية).


