Cross Speaker Emotion Transfer
v0.2.0
Implementasi Pytorch dari transfer emosi lintas-speaker Bytedance berdasarkan kondisi normalisasi lapisan speaker dan pelatihan semi-diawasi dalam teks-ke-speech.
Sampel audio tersedia di /demo.
Dataset mengacu pada nama dataset seperti RAVDESS dalam dokumen berikut.
Anda dapat menginstal dependensi Python dengan
pip3 install -r requirements.txt
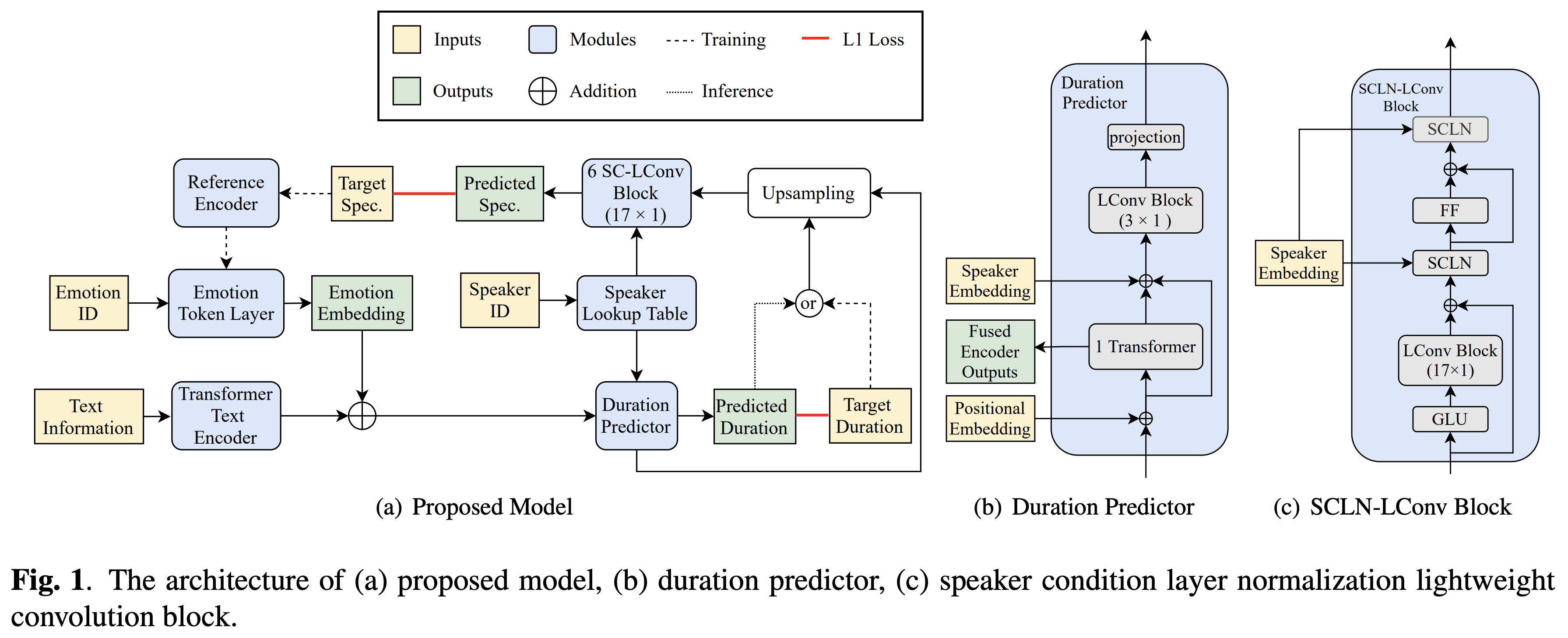
Juga, instal fairseq (dokumen resmi, github) untuk memanfaatkan LConvBlock . Silakan periksa di sini untuk menyelesaikan masalah apa pun saat menginstalnya. Perhatikan bahwa Dockerfile disediakan untuk pengguna Docker , tetapi Anda harus menginstal Fairseq secara manual.
Anda harus mengunduh model pretrained dan memasukkannya ke dalam output/ckpt/DATASET/ .
Untuk mengekstraksi token emosi yang lembut dari audio referensi, jalankan
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --speaker_id SPEAKER_ID --ref_audio REF_AUDIO_PATH --restore_step RESTORE_STEP --mode single --dataset DATASET
Atau, untuk menggunakan token emosi keras dari ID emosi, lari
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --speaker_id SPEAKER_ID --emotion_id EMOTION_ID --restore_step RESTORE_STEP --mode single --dataset DATASET
Kamus speaker yang dipelajari dapat ditemukan di preprocessed_data/DATASET/speakers.json , dan ucapan yang dihasilkan akan dimasukkan ke dalam output/result/ .
Inferensi batch juga didukung, coba
python3 synthesize.py --source preprocessed_data/DATASET/val.txt --restore_step RESTORE_STEP --mode batch --dataset DATASET
Untuk mensintesis semua ucapan di preprocessed_data/DATASET/val.txt . Harap dicatat bahwa hanya token emosi keras dari ID emosi yang diberikan yang didukung dalam mode ini.
Dataset yang didukung adalah
Bahasa dan dataset Anda sendiri dapat diadaptasi di sini.
Untuk TTS multi-speaker dengan embedder speaker eksternal, unduh rescnn softmax+triplet pretrained model Deepspeaker Philipperemy untuk penyematan speaker dan temukan di ./deepspeaker/pretrained_models/ .
Berlari
python3 prepare_align.py --dataset DATASET
untuk beberapa persiapan.
Untuk penyelarasan paksa, Montreal memaksa Aligner (MFA) digunakan untuk mendapatkan keberpihakan antara ucapan dan urutan fonem. Penyelarasan yang telah diekstraksi untuk set data disediakan di sini. Anda harus membuka ritsleting file di preprocessed_data/DATASET/TextGrid/ . Bergantian, Anda dapat menjalankan pelurus sendiri.
Setelah itu, jalankan skrip preprocessing dengan
python3 preprocess.py --dataset DATASET
Latih model Anda dengan
python3 train.py --dataset DATASET
Opsi yang berguna:
--use_amp ke perintah di atas.CUDA_VISIBLE_DEVICES=<GPU_IDs> di awal perintah di atas.Menggunakan
tensorboard --logdir output/log
untuk melayani Tensorboard di Localhost Anda. Kurva kehilangan, sintesis mel-spectrograms, dan audio ditampilkan.
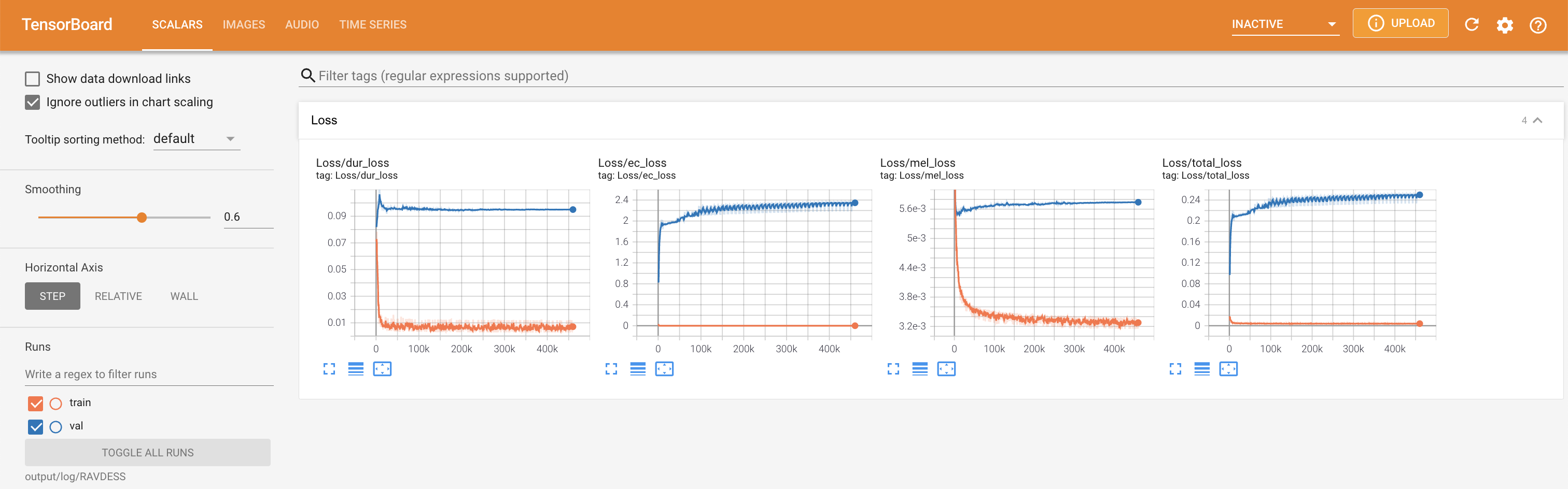
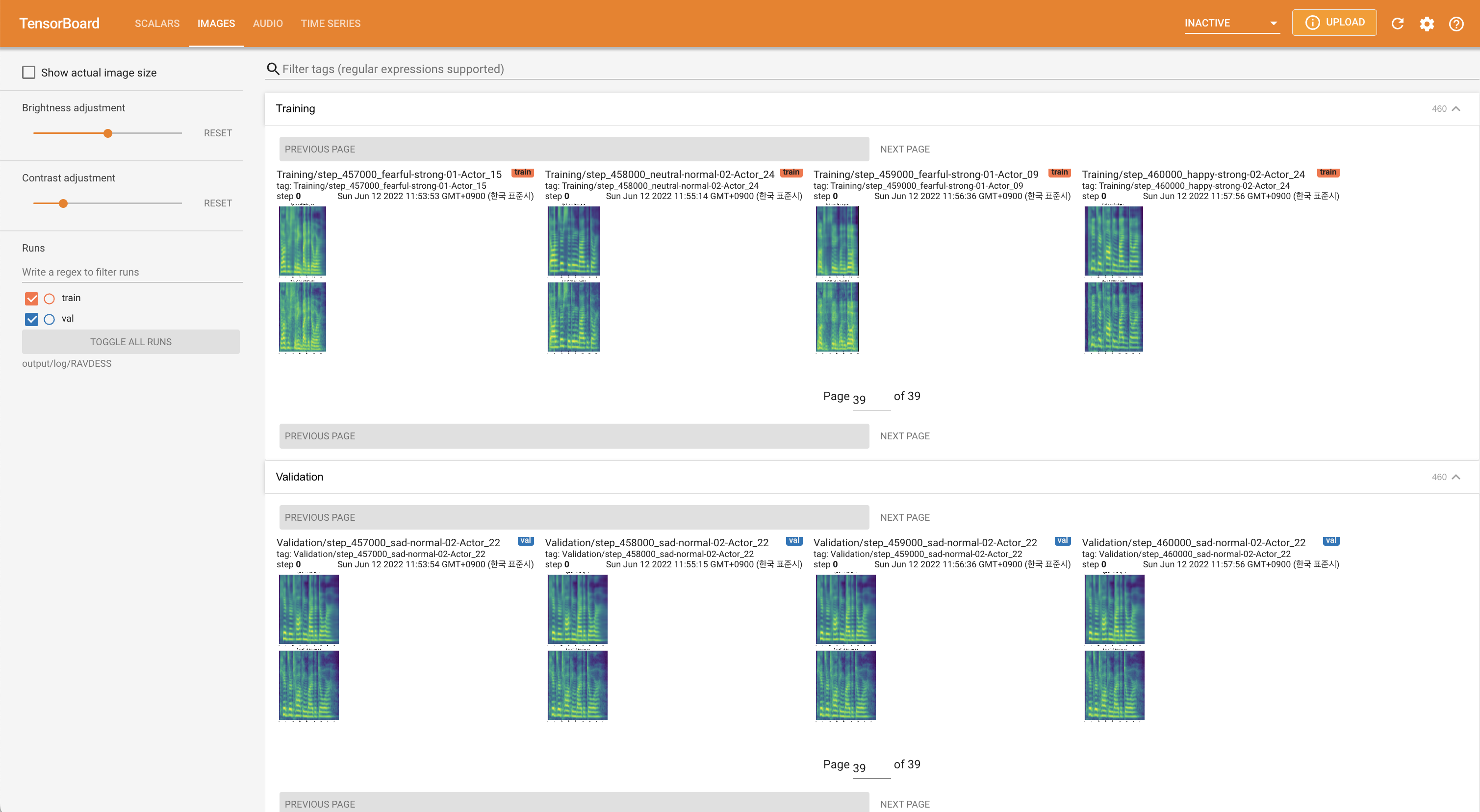
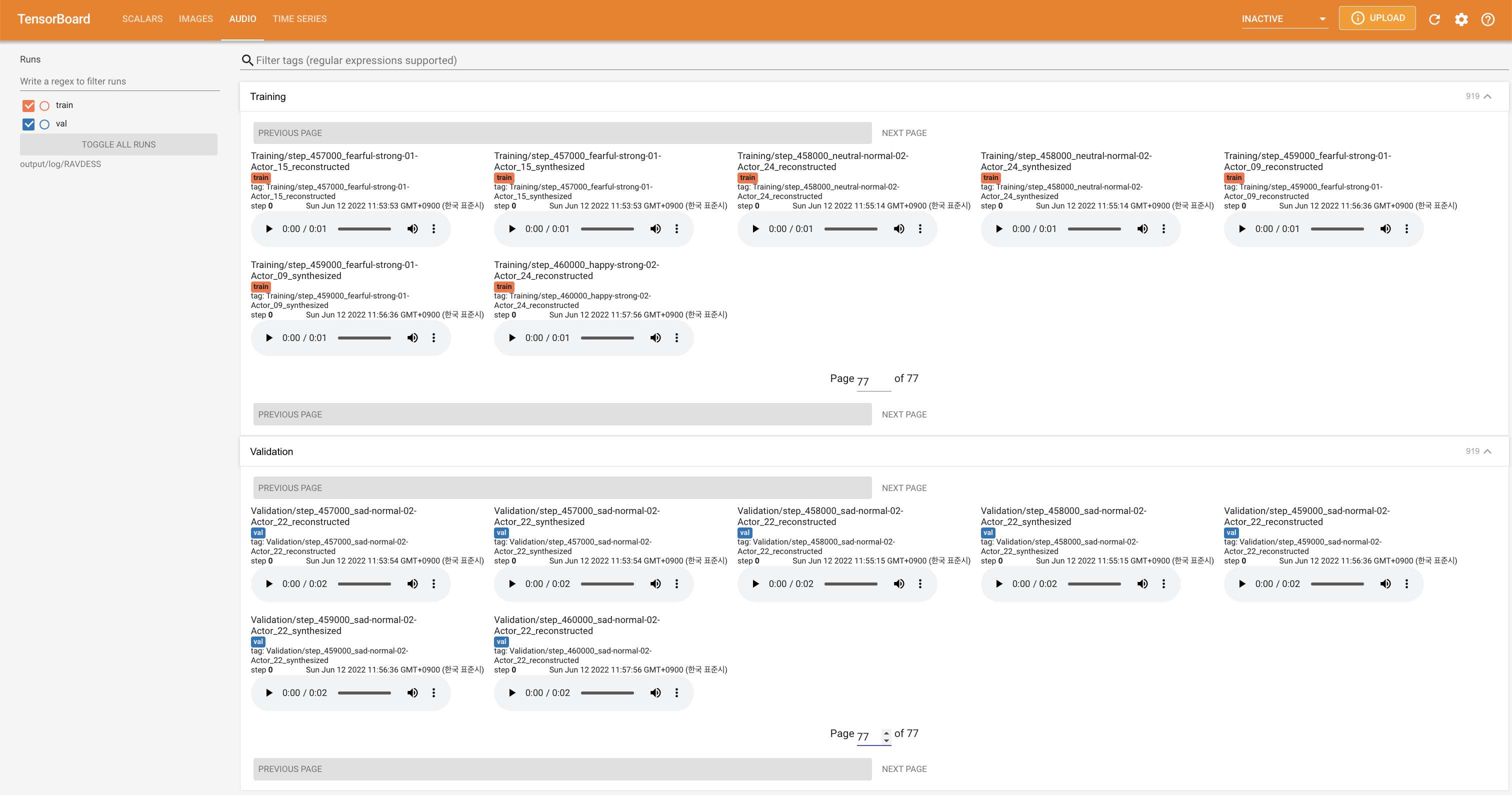
'none' dan 'DeepSpeaker' ).
Harap kutip repositori ini dengan "CITE Repositori ini" dari bagian sekitar (kanan atas halaman utama).


