Cross Speaker Emotion Transfer
v0.2.0
Implementación de Pytorch de la transferencia de emoción de bytedance a través de la transferencia de emociones basada en la normalización de la capa de condición del altavoz y el entrenamiento semi-supervisado en texto a voz.
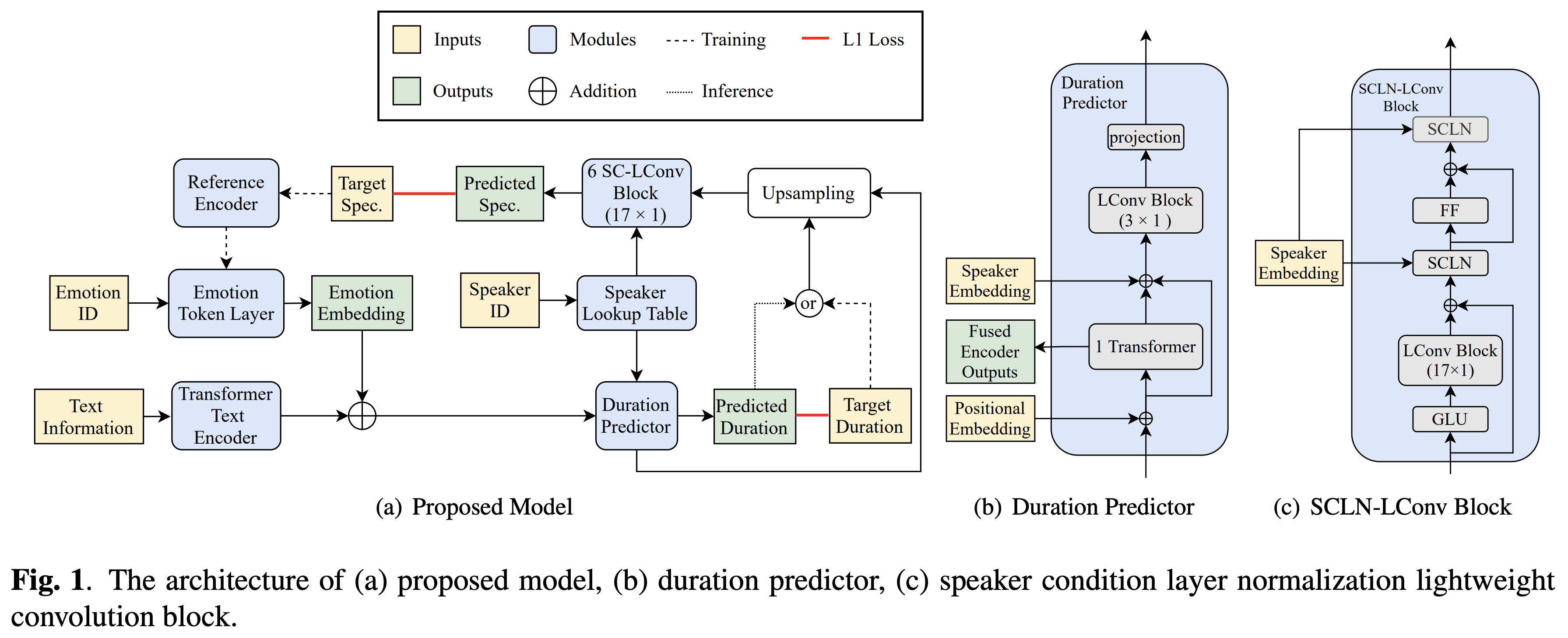
Las muestras de audio están disponibles en /demostración.
El conjunto de datos se refiere a los nombres de conjuntos de datos como RAVDESS en los siguientes documentos.
Puede instalar las dependencias de Python con
pip3 install -r requirements.txt
Además, instale FairSeq (documento oficial, GitHub) para utilizar LConvBlock . Consulte aquí para resolver cualquier problema al instalarlo. Tenga en cuenta que Dockerfile se proporciona para los usuarios Docker , pero debe instalar FairSeq manualmente.
Debe descargar los modelos previos a la aparición y ponerlos en output/ckpt/DATASET/ .
Para extraer tokens de emoción suave de un audio de referencia, ejecute
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --speaker_id SPEAKER_ID --ref_audio REF_AUDIO_PATH --restore_step RESTORE_STEP --mode single --dataset DATASET
O, para usar tokens de emoción dura de una identificación de emoción, correr
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --speaker_id SPEAKER_ID --emotion_id EMOTION_ID --restore_step RESTORE_STEP --mode single --dataset DATASET
El diccionario de los altavoces aprendidos se puede encontrar en preprocessed_data/DATASET/speakers.json , y las expresiones generadas se colocarán en output/result/ .
También es compatible con la inferencia por lotes, intente
python3 synthesize.py --source preprocessed_data/DATASET/val.txt --restore_step RESTORE_STEP --mode batch --dataset DATASET
Para sintetizar todas las expresiones en preprocessed_data/DATASET/val.txt . Tenga en cuenta que solo los tokens de emoción dura de una identificación de emoción dada se apoyan en este modo.
Los conjuntos de datos compatibles son
Su propio idioma y conjunto de datos se pueden adaptar siguiendo aquí.
Para un TTS de múltiples altavoces con un incrustador de altavoces externo, descargue el modelo de retraso previo al petróleo rescnn Softmax+de Filipperemy's DeepSpeaker para la incrustación del altavoz y lo ubique ./deepspeaker/pretrained_models/
Correr
python3 prepare_align.py --dataset DATASET
para algunos preparativos.
Para la alineación forzada, el alineador forzado de Montreal (MFA) se usa para obtener las alineaciones entre las expresiones y las secuencias de fonema. Aquí se proporcionan alineaciones preextracidas para los conjuntos de datos. Debe descomprimir los archivos en preprocessed_data/DATASET/TextGrid/ . Alternativamente, puede ejecutar el alineador usted mismo.
Después de eso, ejecute el script de preprocesamiento por
python3 preprocess.py --dataset DATASET
Entrena tu modelo con
python3 train.py --dataset DATASET
Opciones útiles:
--use_amp al comando anterior.CUDA_VISIBLE_DEVICES=<GPU_IDs> al comienzo del comando anterior.Usar
tensorboard --logdir output/log
para servir tensorboard en su localhost. Se muestran las curvas de pérdida, los espectrogramas MEL sintetizados y los audios.
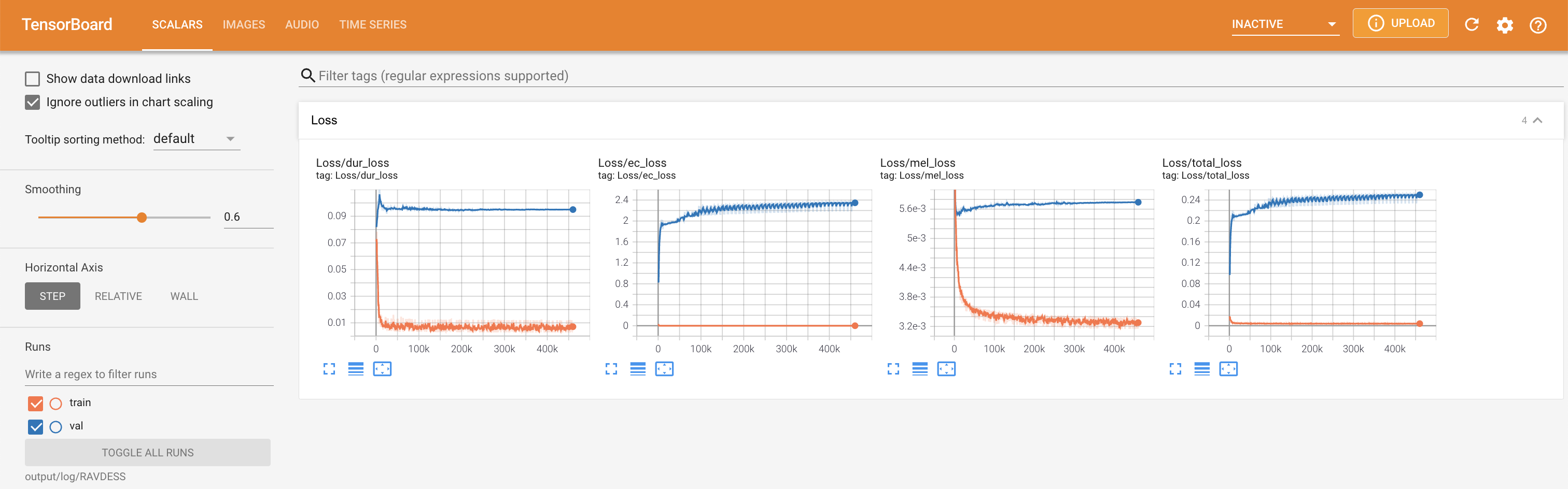
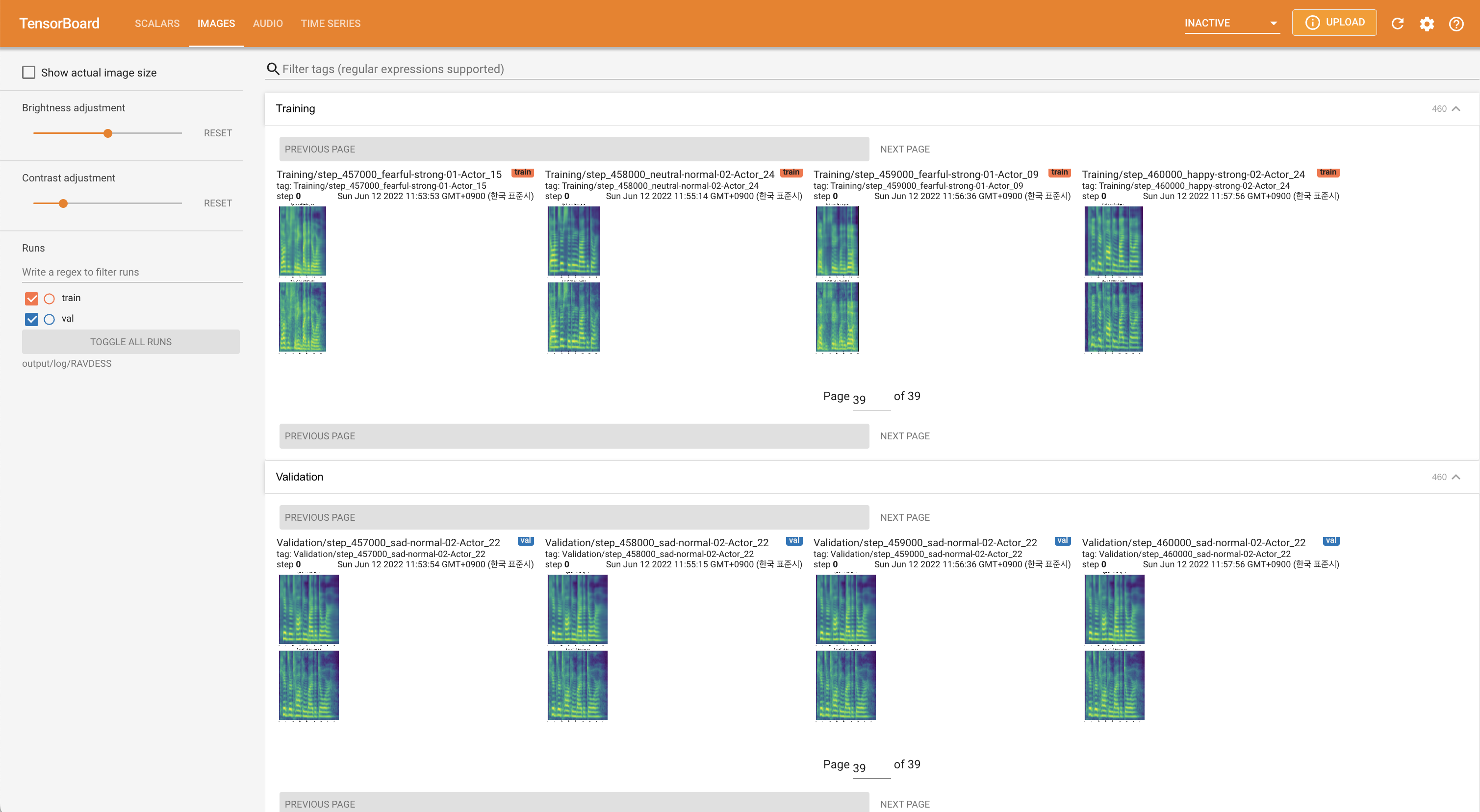
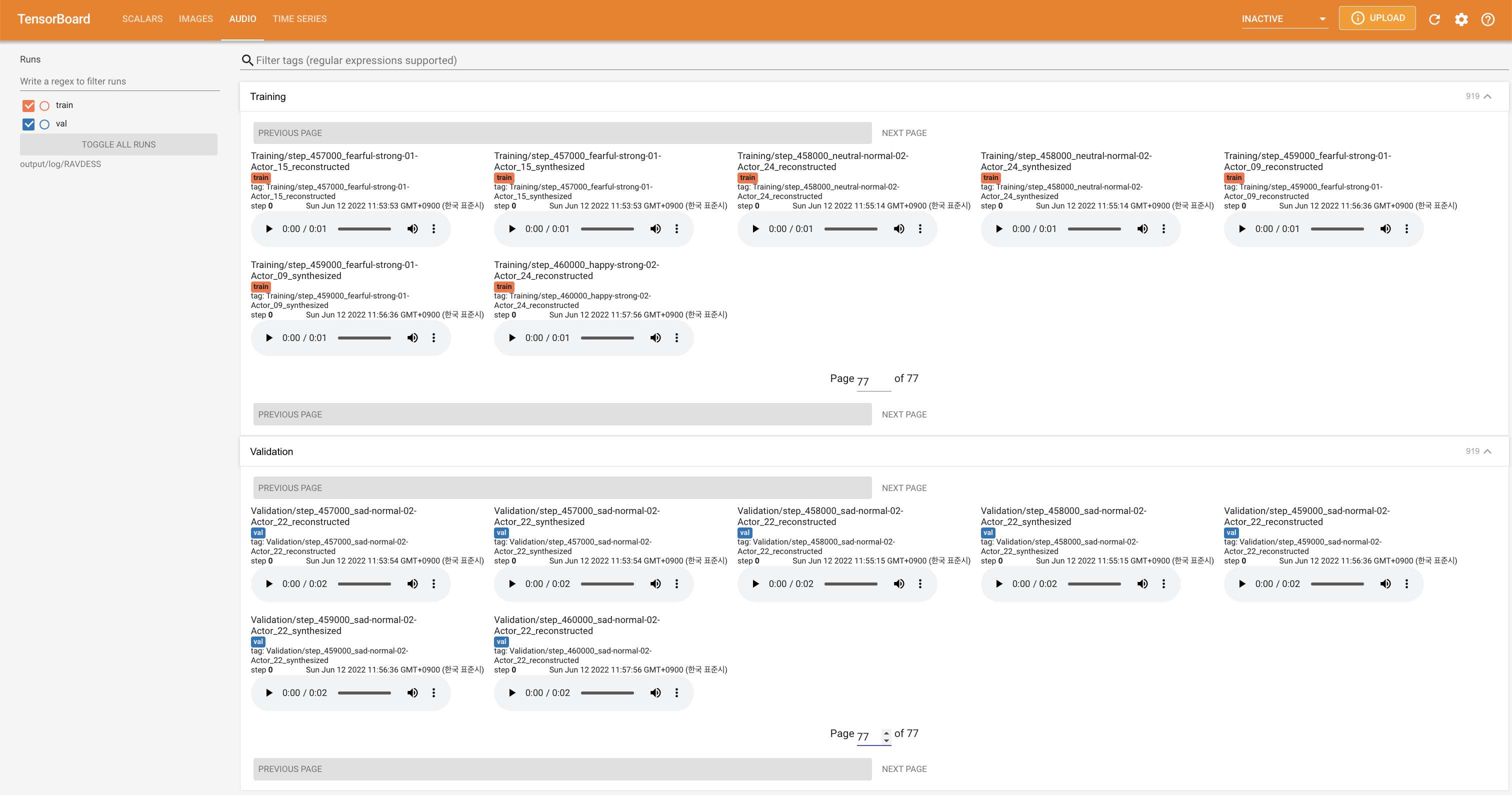
'none' y 'DeepSpeaker' ).
Cite este repositorio por el "cita este repositorio" de la sección Acerca de (arriba a la derecha de la página principal).


