Cross Speaker Emotion Transfer
v0.2.0
スピーカーの状態層の正規化とテキストへの半監視トレーニングに基づいたbytedanceのクロススピーカーの感情転送のPytorchの実装。
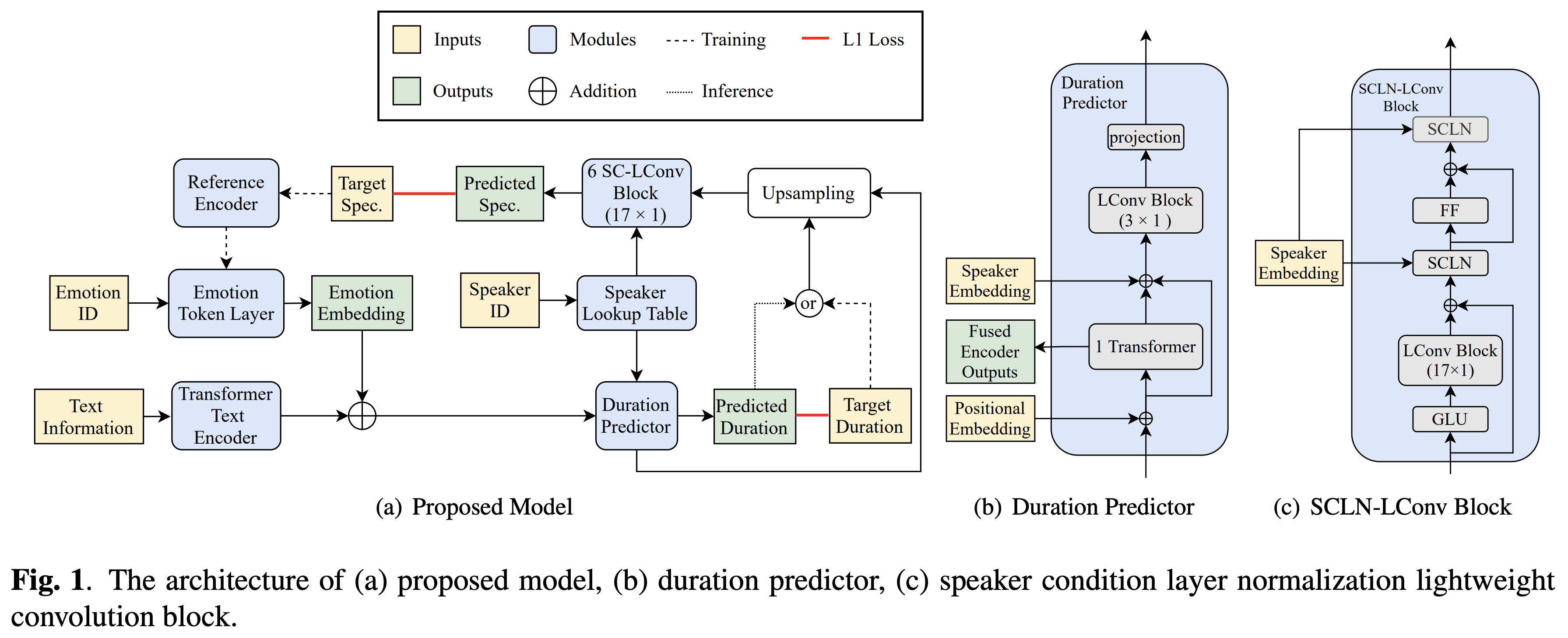
オーディオサンプルは /デモで利用できます。
データセットとは、次のドキュメントのRAVDESSなどのデータセットの名前を指します。
Python依存関係をインストールできます
pip3 install -r requirements.txt
また、FairSeq(公式文書、GitHub)をインストールして、 LConvBlockを利用します。インストールに関する問題を解決するには、こちらを確認してください。 Dockerfile Dockerユーザーに提供されていることに注意してください。ただし、FairSeqを手動でインストールする必要があります。
事前に保護されたモデルをダウンロードして、それらをoutput/ckpt/DATASET/に配置する必要があります。
リファレンスオーディオからソフト感情トークンを抽出するには、実行する
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --speaker_id SPEAKER_ID --ref_audio REF_AUDIO_PATH --restore_step RESTORE_STEP --mode single --dataset DATASET
または、感情IDからハード感情トークンを使用するには、実行する
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --speaker_id SPEAKER_ID --emotion_id EMOTION_ID --restore_step RESTORE_STEP --mode single --dataset DATASET
学習スピーカーの辞書はpreprocessed_data/DATASET/speakers.jsonで見つけることができ、生成された発話はoutput/result/に配置されます。
バッチ推論もサポートされています
python3 synthesize.py --source preprocessed_data/DATASET/val.txt --restore_step RESTORE_STEP --mode batch --dataset DATASET
preprocessed_data/DATASET/val.txtのすべての発話を合成します。このモードでは、特定の感情IDからのハード感情トークンのみがサポートされていることに注意してください。
サポートされているデータセットは次のとおりです
ここでは、独自の言語とデータセットを採用できます。
外部スピーカーの封入器を備えたマルチスピーカーTTSについては、スピーカーの埋め込み用のPhilipperemyのディープスピーカーのRescnn SoftMax+Triplet Tretrained Modelをダウンロードし、それを./deepspeaker/pretrained_models/に見つけます。
走る
python3 prepare_align.py --dataset DATASET
いくつかの準備のために。
強制アライメントのために、モントリオールの強制アライナー(MFA)を使用して、発話と音素シーケンスの間のアライメントを取得します。データセットの事前に抽出されたアライメントはここに記載されています。 preprocessed_data/DATASET/TextGrid/でファイルを解凍する必要があります。または、自分でアライナーを実行できます。
その後、前処理スクリプトを実行します
python3 preprocess.py --dataset DATASET
モデルを訓練します
python3 train.py --dataset DATASET
有用なオプション:
--use_amp引数を追加します。CUDA_VISIBLE_DEVICES=<GPU_IDs>を指定します。使用
tensorboard --logdir output/log
LocalHostでTensorboardを提供します。損失曲線、合成されたメルスペクトルグラム、およびオーディオが表示されます。
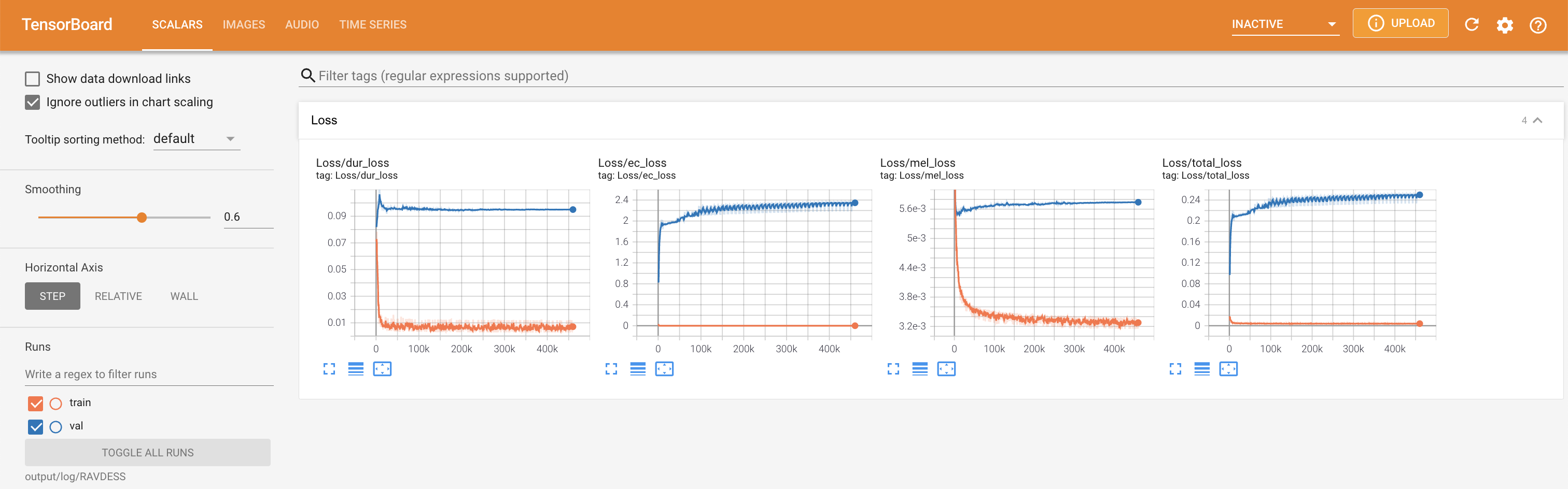
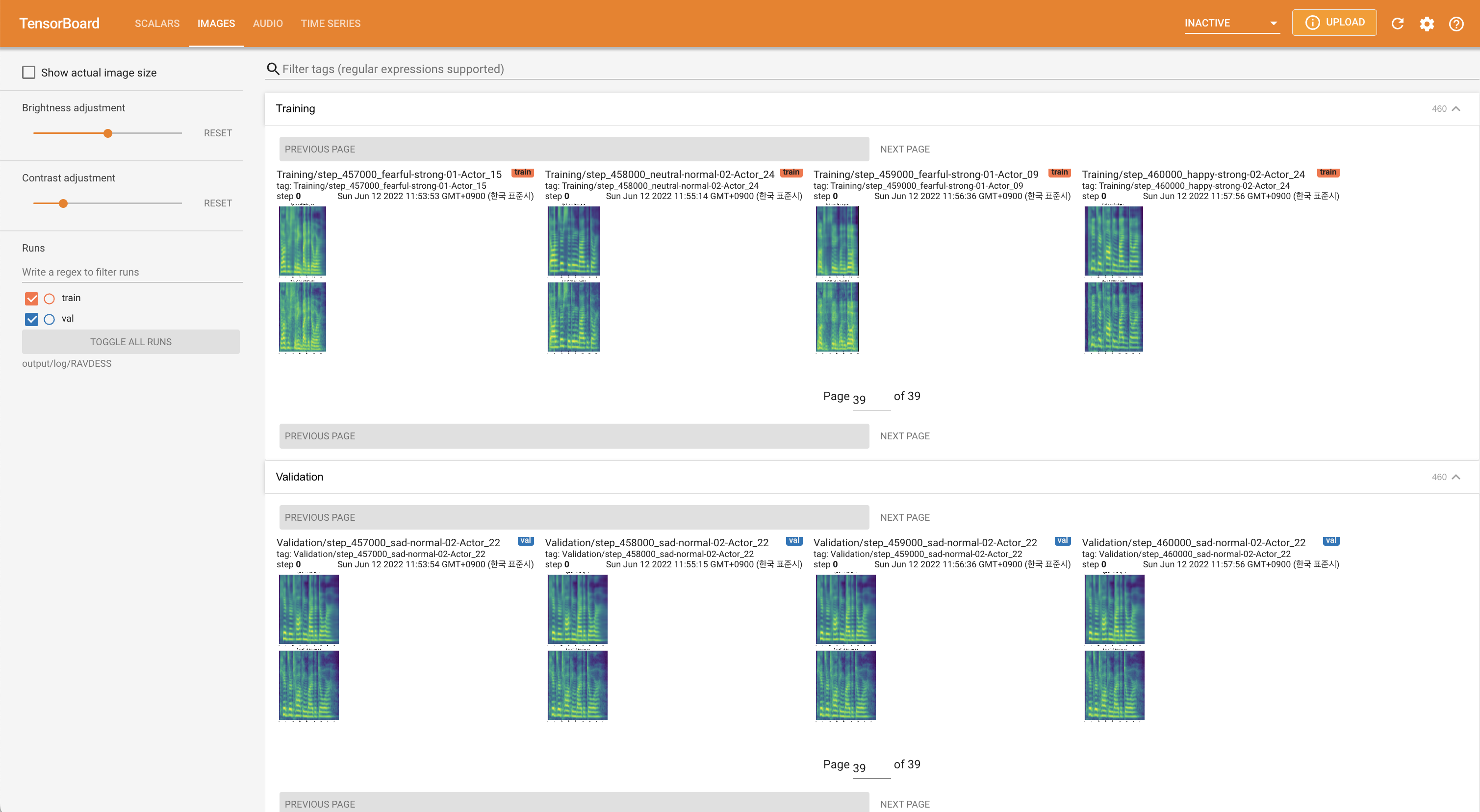
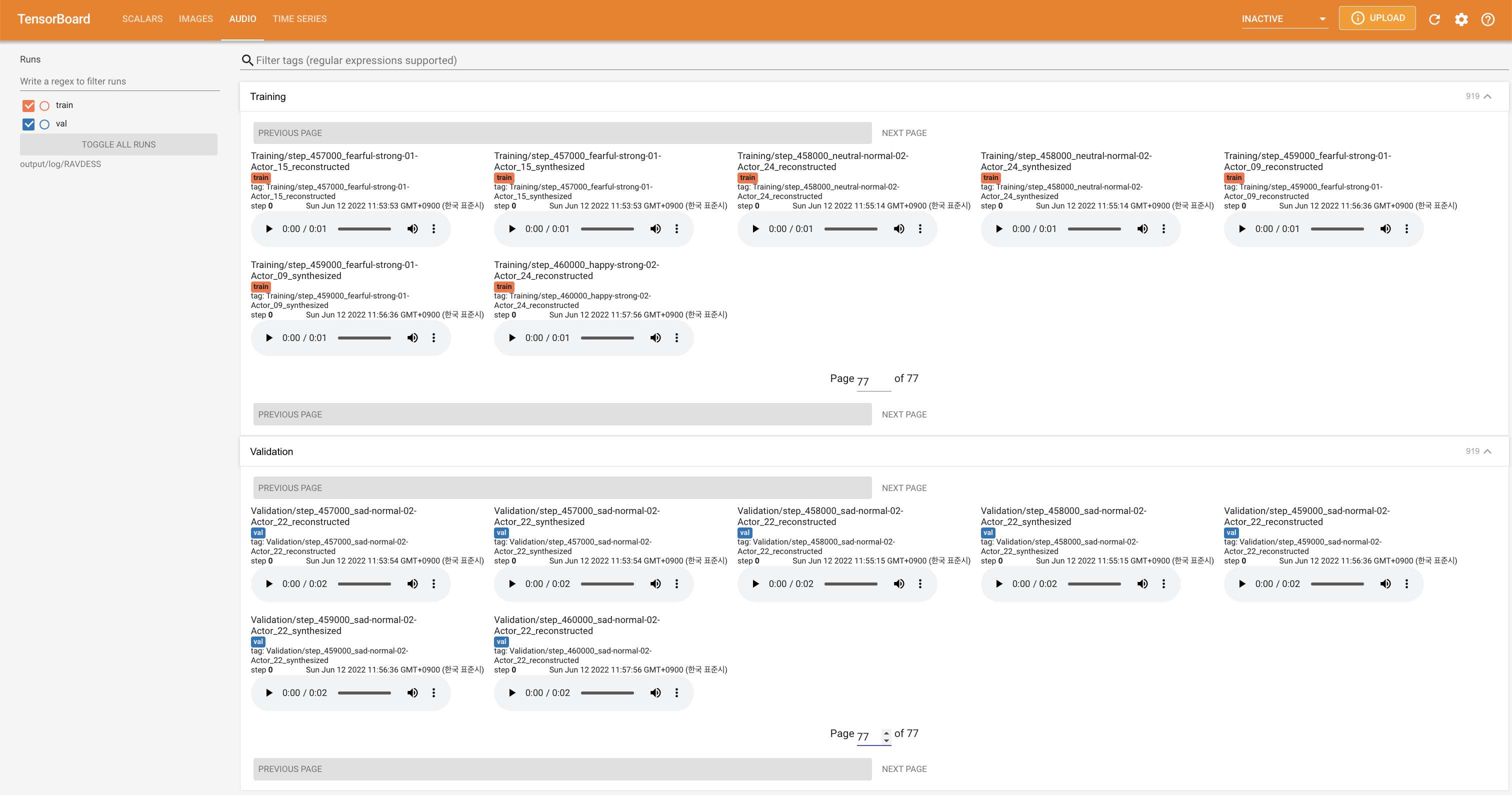
'none'と'DeepSpeaker'の間)を設定して切り替えることができます。
このリポジトリは、セクションについての「このリポジトリを引用」して引用してください(メインページの右上)。


