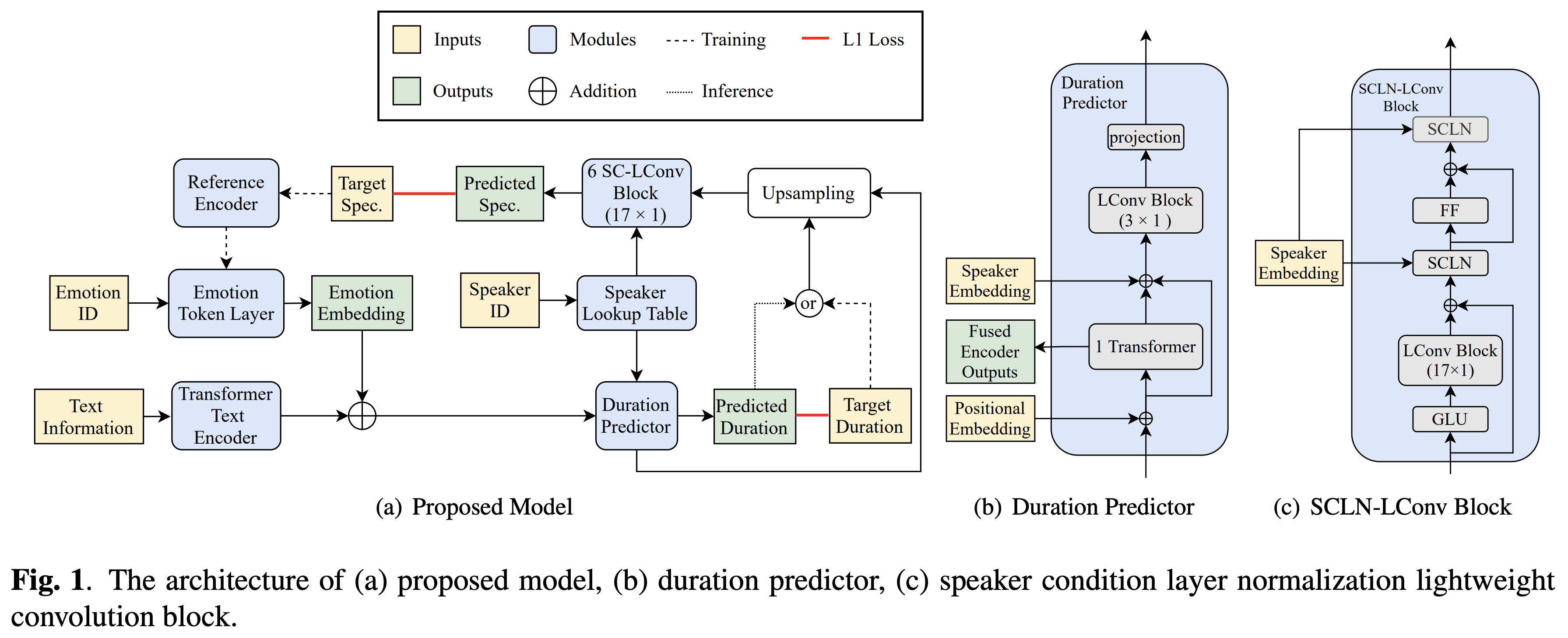
Cross Speaker Emotion Transfer
v0.2.0
A implementação de Pytorch da transferência de emoção cruzada do Bytedance com base na normalização da camada de condição do alto-falante e treinamento semi-supervisionado em texto para fala.
Amostras de áudio estão disponíveis em /demonstração.
O conjunto de dados refere -se aos nomes de conjuntos de dados como RAVDESS nos seguintes documentos.
Você pode instalar as dependências do Python com
pip3 install -r requirements.txt
Além disso, instale o Fairseq (documento oficial, GitHub) para utilizar LConvBlock . Por favor, verifique aqui para resolver qualquer problema ao instalá -lo. Observe que Dockerfile é fornecido para usuários Docker , mas você precisa instalar o Fairseq manualmente.
Você precisa baixar os modelos pré -tenhados e colocá -los em output/ckpt/DATASET/ .
Para extrair tokens de emoção suave de um áudio de referência, execute
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --speaker_id SPEAKER_ID --ref_audio REF_AUDIO_PATH --restore_step RESTORE_STEP --mode single --dataset DATASET
Ou, para usar tokens emoção dura de um id em emoção, corra
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --speaker_id SPEAKER_ID --emotion_id EMOTION_ID --restore_step RESTORE_STEP --mode single --dataset DATASET
O dicionário de alto -falantes instruídos pode ser encontrado em preprocessed_data/DATASET/speakers.json , e os enunciados gerados serão colocados em output/result/ .
A inferência em lote também é suportada, tente
python3 synthesize.py --source preprocessed_data/DATASET/val.txt --restore_step RESTORE_STEP --mode batch --dataset DATASET
Para sintetizar todos os enunciados em preprocessed_data/DATASET/val.txt . Observe que apenas os tokens de emoção difícil de um determinado ID da emoção são suportados nesse modo.
Os conjuntos de dados suportados são
Seu próprio idioma e conjunto de dados podem ser adaptados a seguir aqui.
Para um TTS multi-falante com o orador externo incorporador, faça o download do Modelo de Pré-Priendido de Rescnn Softmax+Tripleto do Philipperemy Deepaker para o alto-falante incorporando e localize-o em ./deepspeaker/pretrained_models/ .
Correr
python3 prepare_align.py --dataset DATASET
para alguns preparativos.
Para o alinhamento forçado, o alinhador forçado de Montreal (MFA) é usado para obter os alinhamentos entre os enunciados e as seqüências de fonemas. Alinhamentos pré-extraídos para os conjuntos de dados são fornecidos aqui. Você precisa descompactar os arquivos em preprocessed_data/DATASET/TextGrid/ . Como alternativa, você pode executar o alinhador sozinho.
Depois disso, execute o script de pré -processamento por
python3 preprocess.py --dataset DATASET
Treine seu modelo com
python3 train.py --dataset DATASET
Opções úteis:
--use_amp do comando acima.CUDA_VISIBLE_DEVICES=<GPU_IDs> no início do comando acima.Usar
tensorboard --logdir output/log
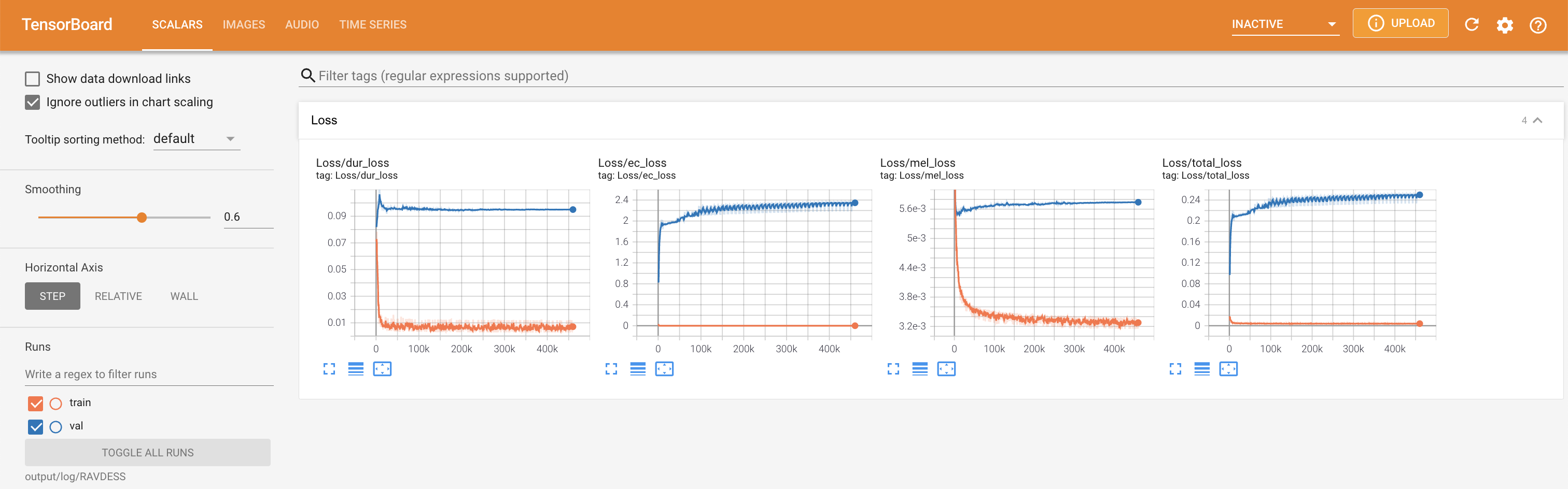
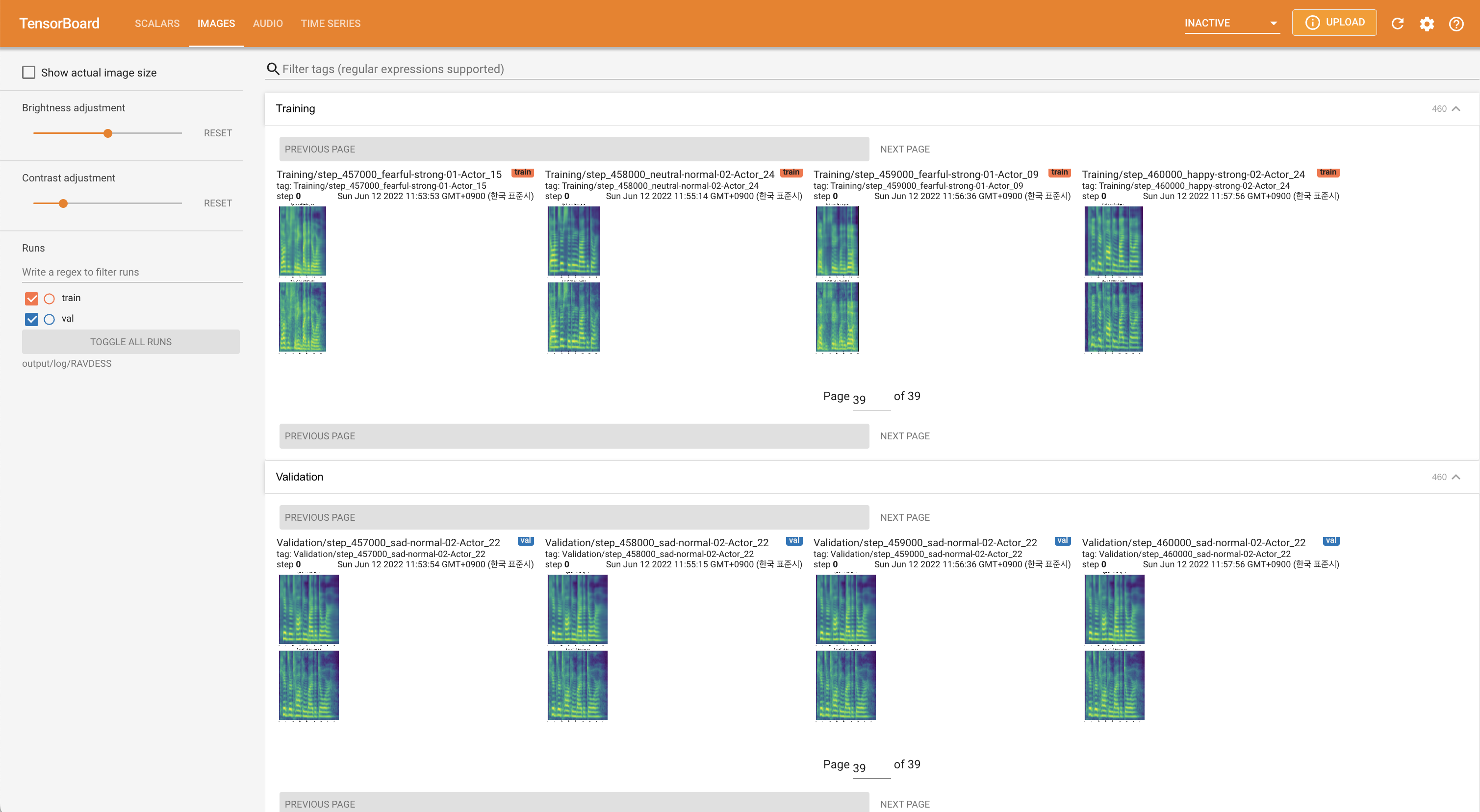
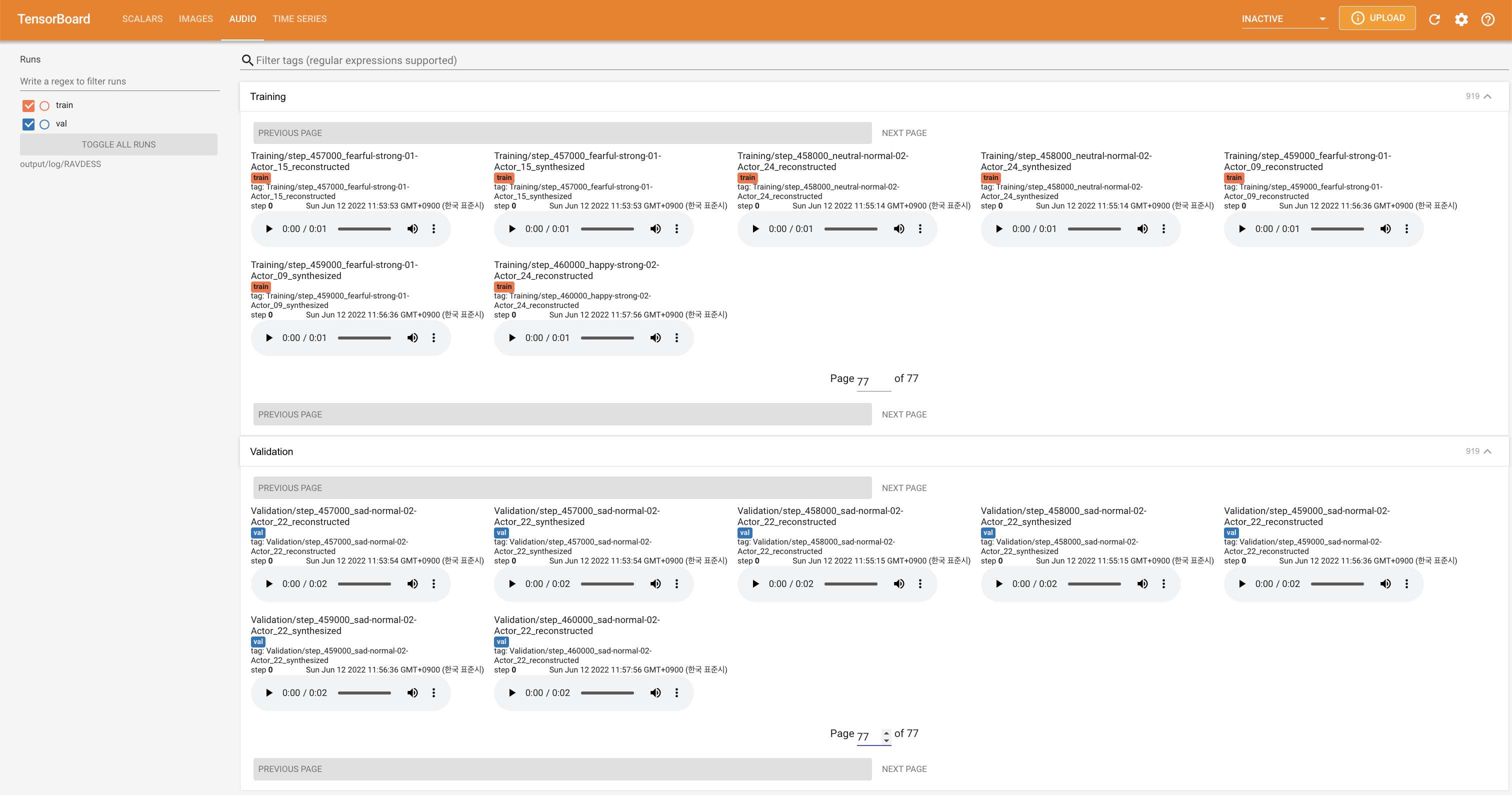
Para servir o Tensorboard em sua localhost. As curvas de perda, os espectrogramas MEL sintetizados e os áudios são mostrados.
'none' e 'DeepSpeaker' ).
Cite este repositório pelo "citar este repositório" da seção Sobre (canto superior direito da página principal).


