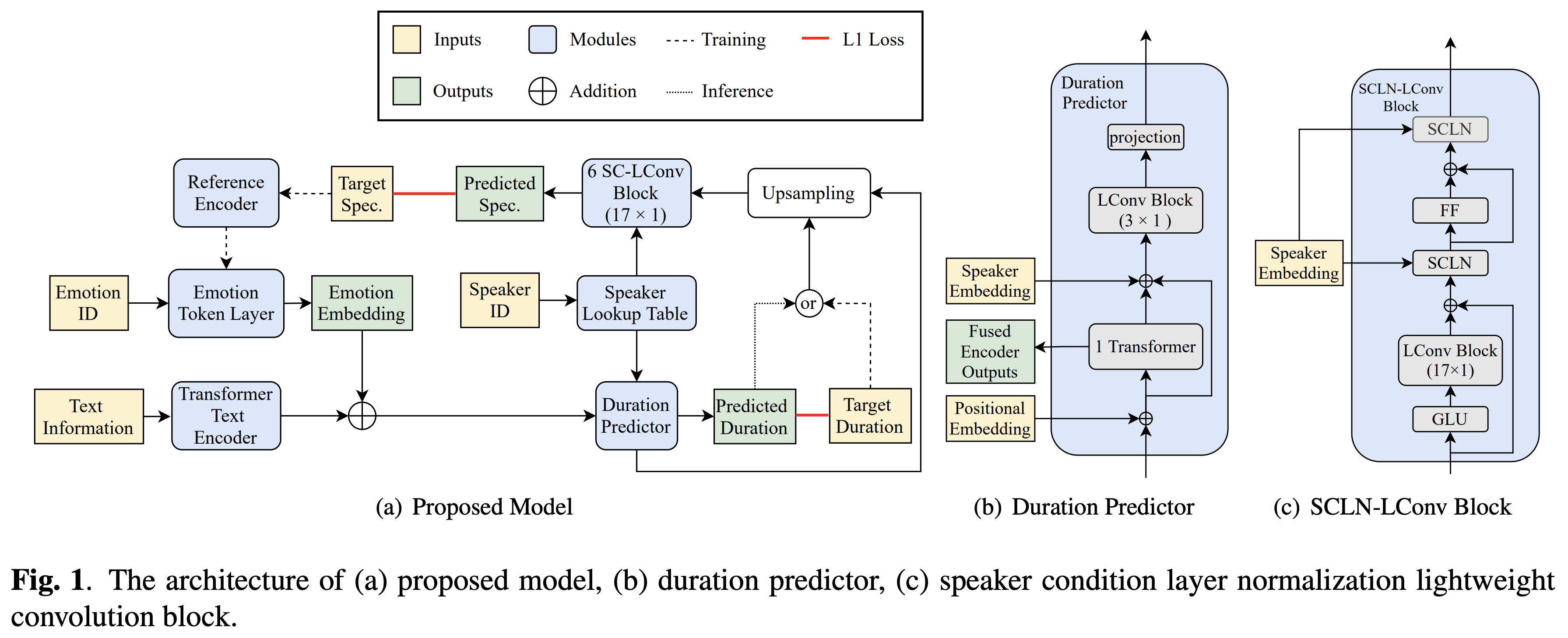
Cross Speaker Emotion Transfer
v0.2.0
Pytorch Mise en œuvre du transfert d'émotion croisé de ByTedance basé sur la normalisation de la couche de condition du haut-parleur et la formation semi-supervisée en texte vocal.
Des échantillons audio sont disponibles à / démo.
L'ensemble de données fait référence aux noms des ensembles de données tels que RAVDESS dans les documents suivants.
Vous pouvez installer les dépendances Python avec
pip3 install -r requirements.txt
Installez également Fairseq (document officiel, GitHub) pour utiliser LConvBlock . Veuillez vérifier ici pour résoudre tout problème lors de l'installation. Notez que Dockerfile est fourni pour les utilisateurs Docker , mais vous devez installer manuellement Fairseq.
Vous devez télécharger les modèles pré-entraînés et les mettre dans output/ckpt/DATASET/ .
Pour extraire les jetons d'émotion doux d'un audio de référence, exécutez
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --speaker_id SPEAKER_ID --ref_audio REF_AUDIO_PATH --restore_step RESTORE_STEP --mode single --dataset DATASET
Ou, pour utiliser des jetons d'émotion durs d'un identifiant d'émotion, courez
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --speaker_id SPEAKER_ID --emotion_id EMOTION_ID --restore_step RESTORE_STEP --mode single --dataset DATASET
Le dictionnaire des enceintes savants peut être trouvé sur preprocessed_data/DATASET/speakers.json , et les énoncés générés seront placés en output/result/ .
L'inférence par lots est également prise en charge, essayez
python3 synthesize.py --source preprocessed_data/DATASET/val.txt --restore_step RESTORE_STEP --mode batch --dataset DATASET
Pour synthétiser toutes les énoncés dans preprocessed_data/DATASET/val.txt . Veuillez noter que seuls les jetons émotionnels durs d'un ID d'émotion donné sont soutenus dans ce mode.
Les ensembles de données pris en charge sont
Votre propre langue et ensemble de données peuvent être adaptés à la suite ici.
Pour un TTS multi-haut-parleurs avec un intérêt de haut-parleur externe, téléchargez Rescnn Softmax + Triplet Pretraind Model of Philippermy's DeepPeaker pour le haut-parleur incorpore et le localisez dans ./deepspeaker/pretrained_models/ .
Courir
python3 prepare_align.py --dataset DATASET
pour certaines préparatifs.
Pour l'alignement forcé, l'aligneur forcé de Montréal (MFA) est utilisé pour obtenir les alignements entre les énoncés et les séquences de phonèmes. Les alignements pré-extractés pour les ensembles de données sont fournis ici. Vous devez décompresser les fichiers dans preprocessed_data/DATASET/TextGrid/ . Alternativement, vous pouvez exécuter l'aligneur par vous-même.
Après cela, exécutez le script de prétraitement par
python3 preprocess.py --dataset DATASET
Former votre modèle avec
python3 train.py --dataset DATASET
Options utiles:
--use_amp à la commande ci-dessus.CUDA_VISIBLE_DEVICES=<GPU_IDs> au début de la commande ci-dessus.Utiliser
tensorboard --logdir output/log
pour servir Tensorboard sur votre hôte local. Les courbes de perte, les spectrogrammes de MEL synthétisés et les audios sont affichés.
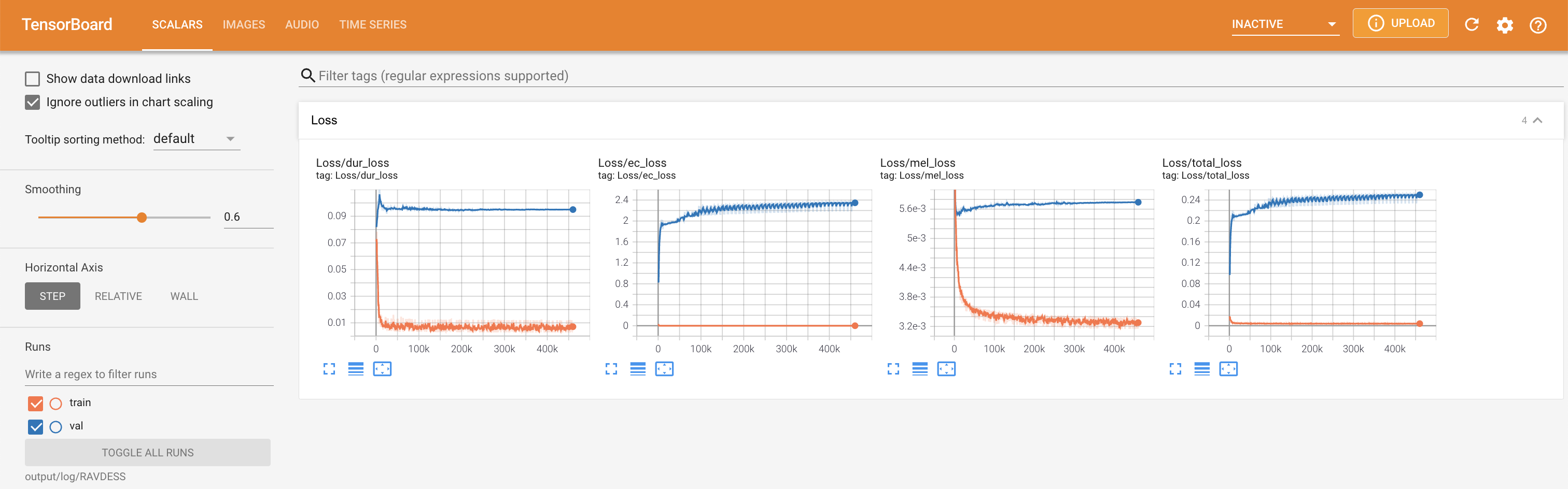
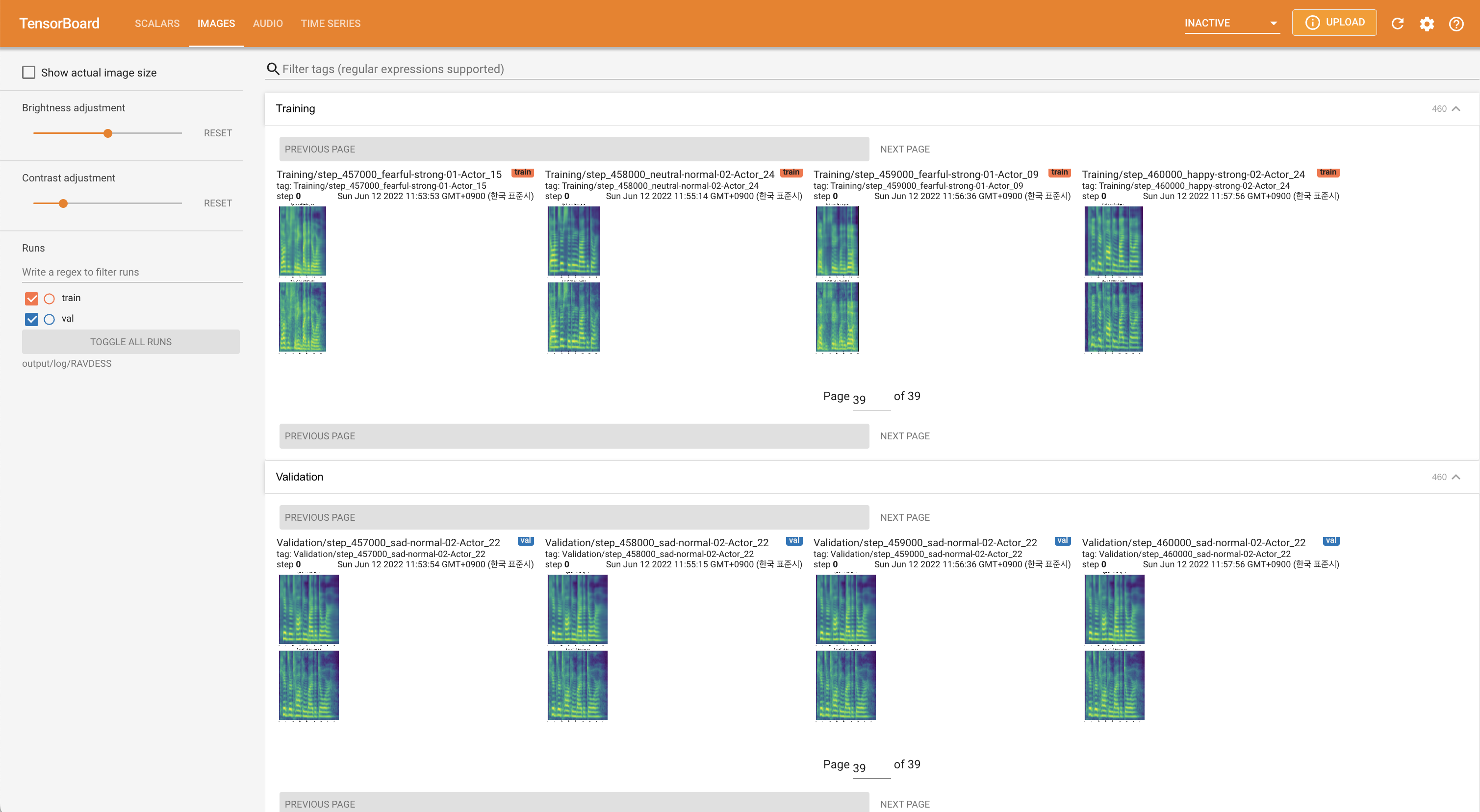
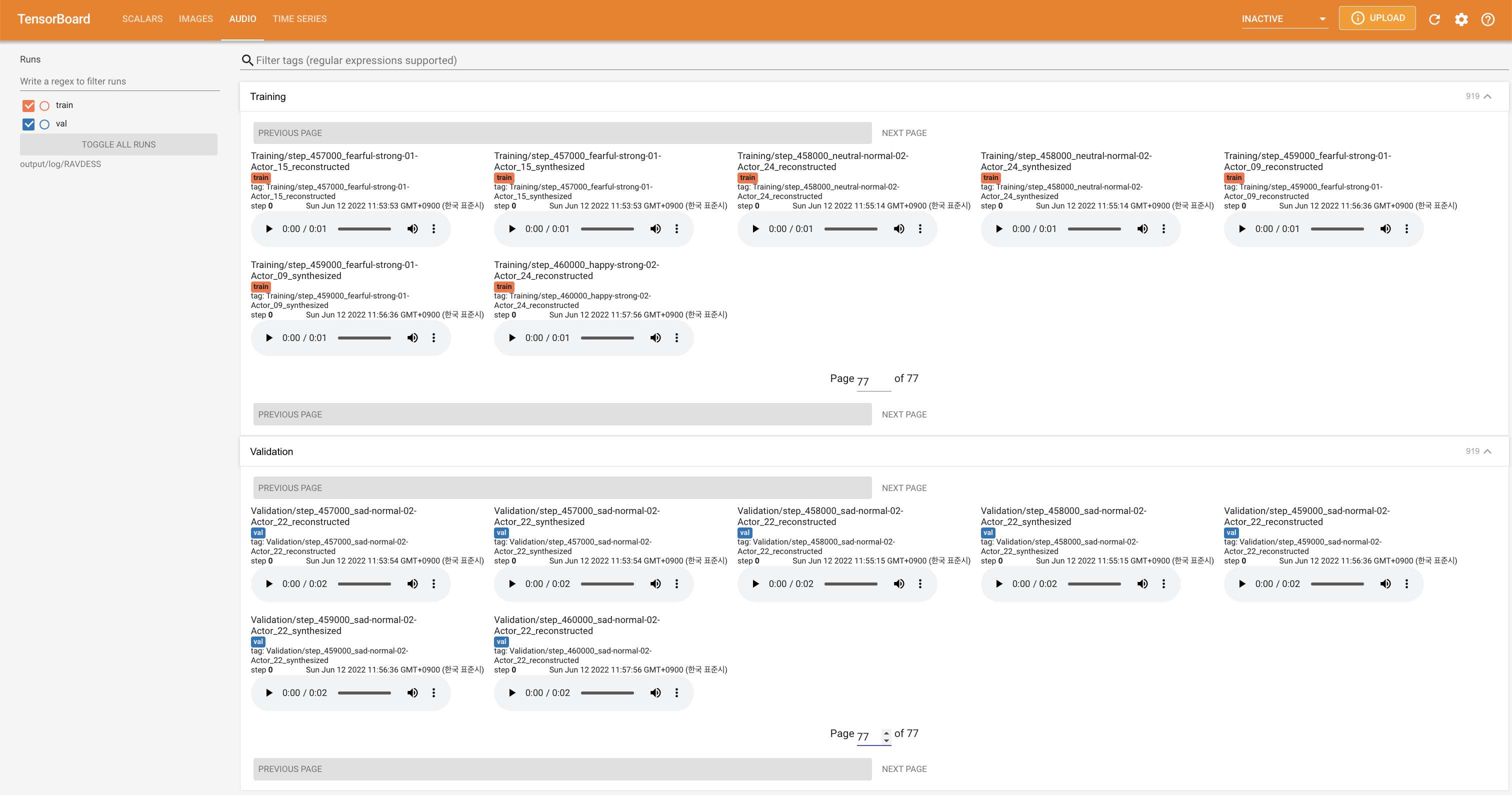
'none' et 'DeepSpeaker' ).
Veuillez citer ce référentiel par le "Citez ce référentiel" de la section environ (en haut à droite de la page principale).


