Cross Speaker Emotion Transfer
v0.2.0
Реализация Pytorch перекрестной передачи эмоций Bytedance на основе нормализации слоя спикера и полупроницаемой тренировки по тексту в речь.
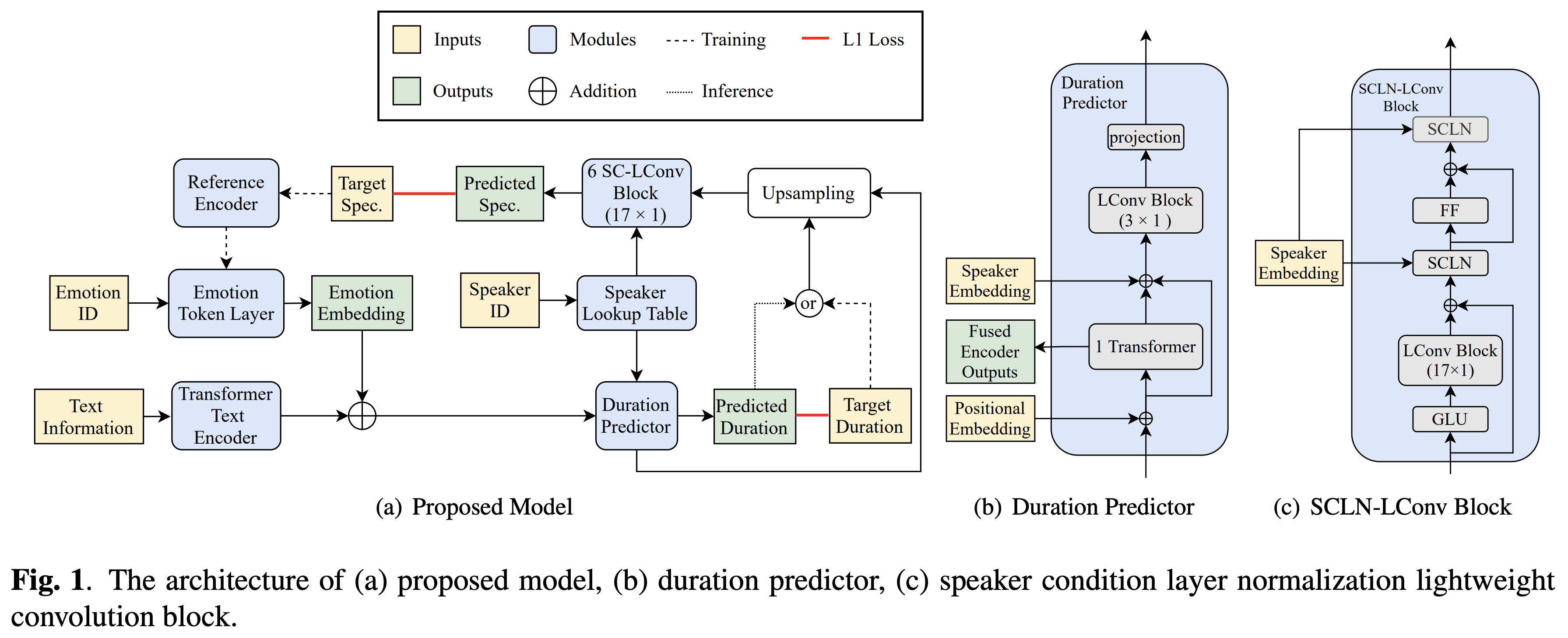
Образцы аудио доступны в /демо.
Набор данных относится к именам наборов данных, таких как RAVDESS в следующих документах.
Вы можете установить зависимости Python с
pip3 install -r requirements.txt
Кроме того, установите Fairseq (официальный документ, GitHub), чтобы использовать LConvBlock . Пожалуйста, проверьте здесь, чтобы решить любую проблему при его установке. Обратите внимание, что Dockerfile предоставлен для пользователей Docker , но вам нужно установить Fairseq вручную.
Вы должны загрузить предварительно подготовленные модели и поместить их в output/ckpt/DATASET/ .
Чтобы извлечь токены мягких эмоций из эталонного звука, запустите
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --speaker_id SPEAKER_ID --ref_audio REF_AUDIO_PATH --restore_step RESTORE_STEP --mode single --dataset DATASET
Или, чтобы использовать жесткие токены эмоций из идентификатора эмоций, бегите
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --speaker_id SPEAKER_ID --emotion_id EMOTION_ID --restore_step RESTORE_STEP --mode single --dataset DATASET
Словарь ученых докладчиков можно найти на preprocessed_data/DATASET/speakers.json output/result/
Пакетный вывод также поддерживается, попробуйте
python3 synthesize.py --source preprocessed_data/DATASET/val.txt --restore_step RESTORE_STEP --mode batch --dataset DATASET
Чтобы синтезировать все высказывания в preprocessed_data/DATASET/val.txt . Обратите внимание, что в этом режиме поддерживаются только тяжелые жетоны эмоций от данного идентификатора эмоций.
Поддерживаемые наборы данных
Ваш собственный язык и набор данных могут быть адаптированы здесь.
Для Multi-Speaker TTS с внешним динамиком Embedder загрузите Rescnn Softmax+триплетный предварительно предварительно предварительно проведенный модели DeepSpeaker Филипперей для динамика, внедряющего его и найдите его в ./deepspeaker/pretrained_models/ .
Бегать
python3 prepare_align.py --dataset DATASET
для некоторых приготовлений.
Для принудительного выравнивания Монреаль принудительный выравниватель (MFA) используется для получения выравнивания между высказываниями и последовательностями фонем. Предварительные выравнивания для наборов данных представлены здесь. Вы должны расстегнуть разанипировать файлы в preprocessed_data/DATASET/TextGrid/ . С другой стороны, вы можете запустить выравниватель самостоятельно.
После этого запустите сценарий предварительной обработки
python3 preprocess.py --dataset DATASET
Тренировать свою модель с
python3 train.py --dataset DATASET
Полезные варианты:
--use_amp к вышеуказанной команде.CUDA_VISIBLE_DEVICES=<GPU_IDs> в начале вышеуказанной команды.Использовать
tensorboard --logdir output/log
Подавать в Tensorboard на вашем местном хосте. Кривые потерь, синтезированные мель-спектрограммы и аудио показаны.
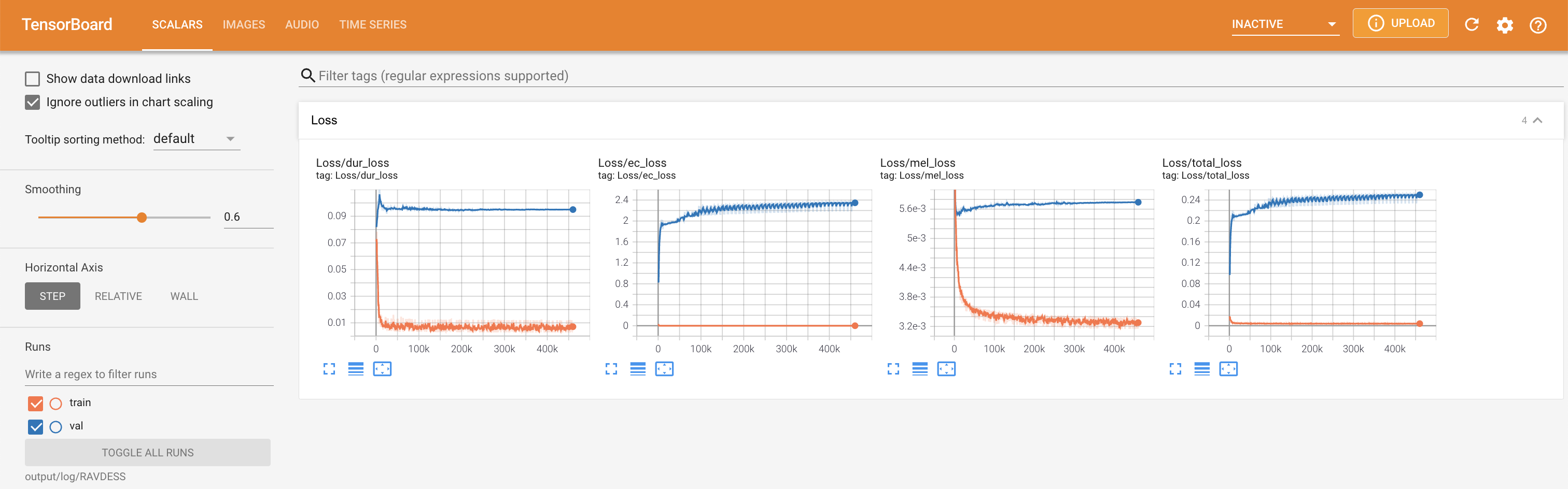
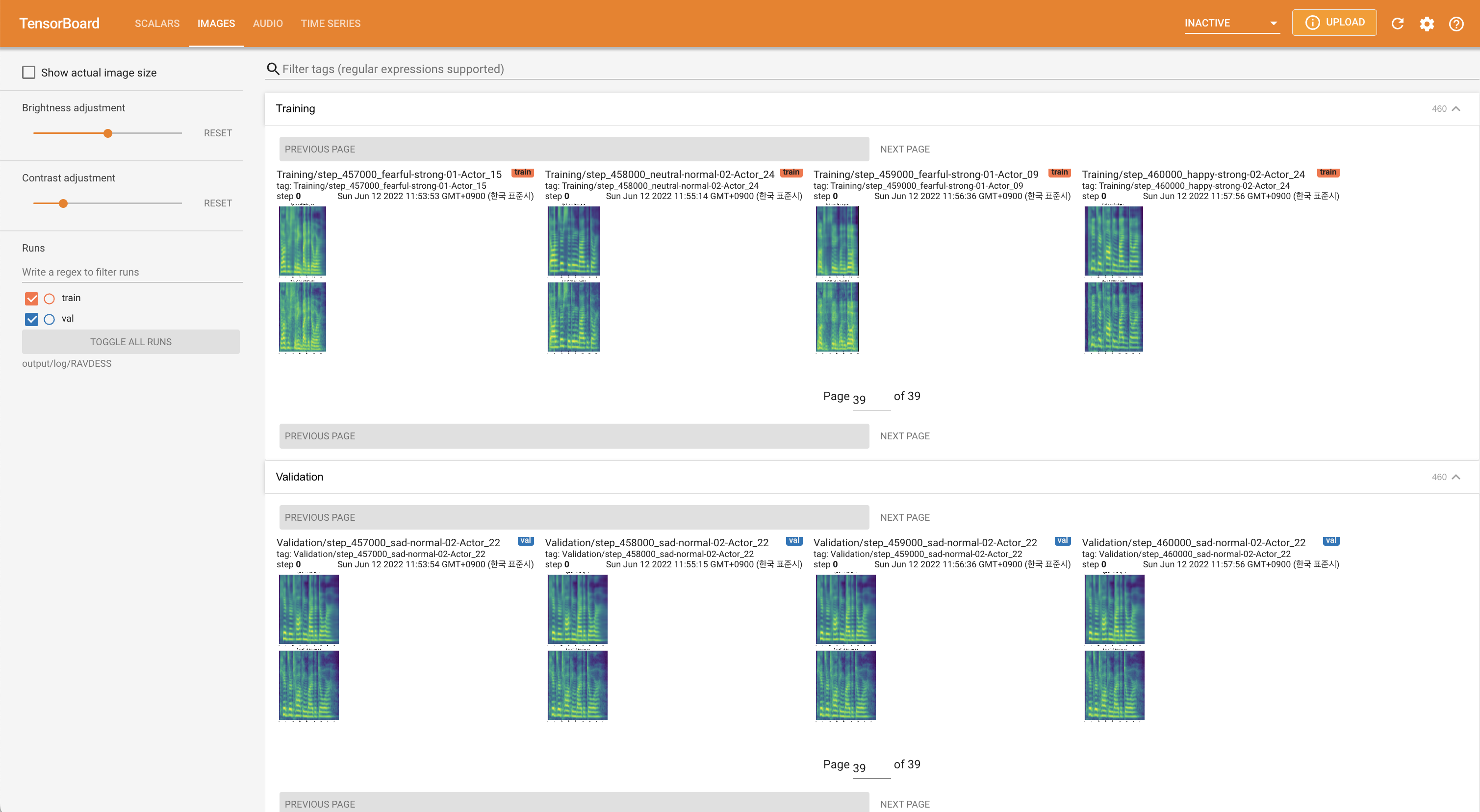
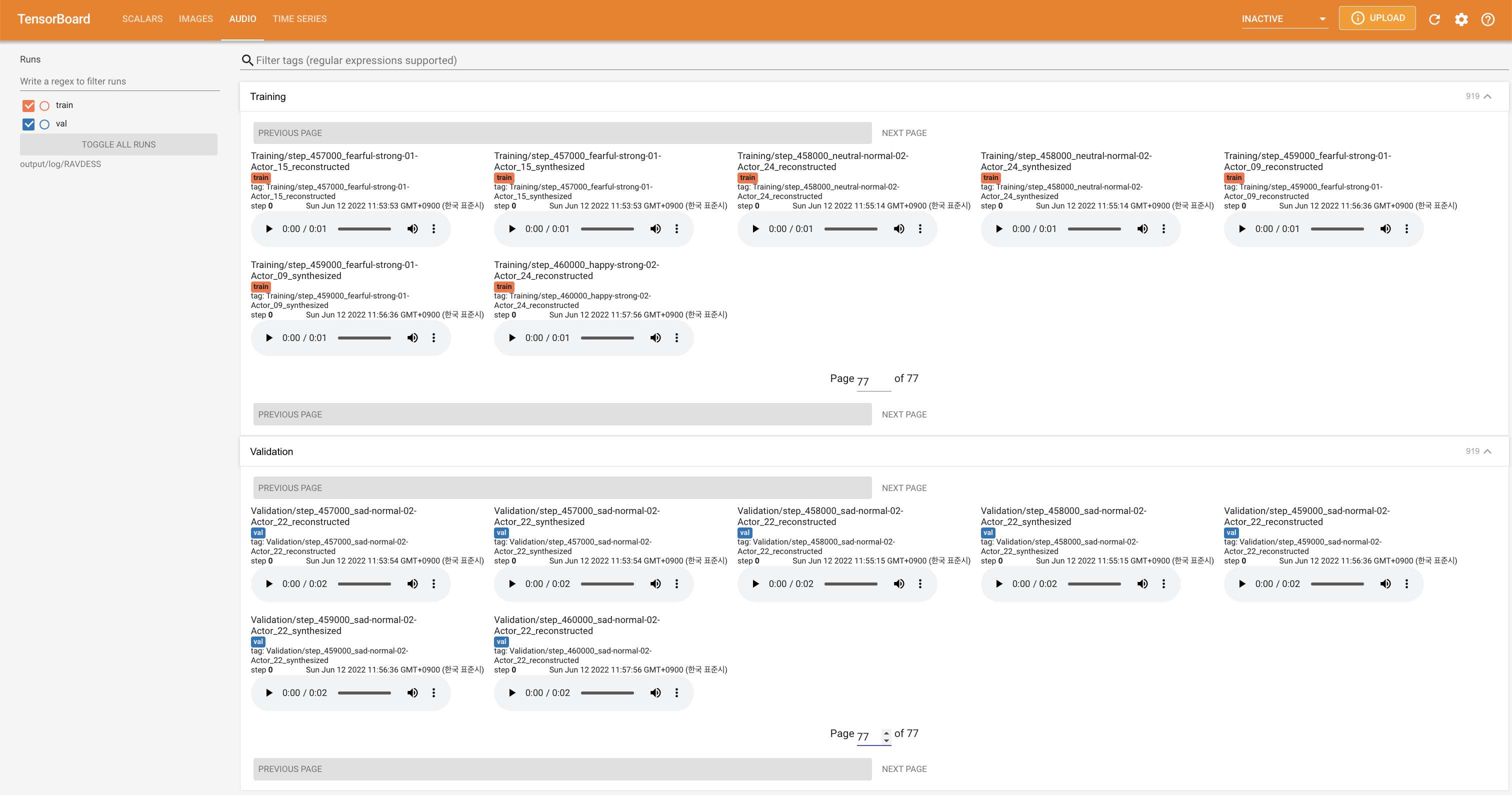
'none' и 'DeepSpeaker' ).
Пожалуйста, цитируйте этот репозиторий с помощью «цитируйте этот репозиторий» о разделе (верхняя правая на главной странице).


