pytorch 3dunet
vent stride_shape override in prediction
3D U-NET及其变体的Pytorch实现:
基于3D U-NET的UNet3D标准3D U-NET:从稀疏注释中学习密集的体积分割
基于SNEMI3D Connectomics Challenge的超人准确性的ResidualUNet3D残留3D U-NET
ResidualUNetSE3D类似于残留的ResidualUNet3D ,并基于高分辨率医疗量的深度学习语义分割增加了挤压和激发块。原始挤压和激发纸:挤压网络
该代码允许对U-NET进行训练:语义细分(二进制和多级)和回归问题(例如,纳入,学习反应)。
还支持2D U-NET,请参见2Dunet_confocal或2dunet_dsb2018,例如配置。只需确保将单例Z-Dimension保留在您的H5数据集中(即(1, Y, X)而不是(Y, X) ),因为数据加载 /数据增强需要等级3的张量。2DU-NET本身使用标准2D卷积层代替具有核心大小的3D卷积卷积(1, 3, 3) 。
输入数据应存储在HDF5文件中。用于培训的HDF5文件应包含两个数据集: raw和label 。选择的是,在使用PixelWiseCrossEntropyLoss培训时,应该提供weight数据集。 raw数据集应包含输入数据,而label数据集的地面真相标签。可选的weight数据集应包含加权输入不同区域中损耗函数的值,并且大小应与label数据集相同。 raw / label数据集的格式取决于问题是2D还是3D,以及数据是单渠道还是多通道,请参见下表:
| 2d | 3D | |
|---|---|---|
| 单渠道 | (1,Y,X) | (z,y,x) |
| 多通道 | (C,1,Y,X) | (C,Z,Y,X) |
pytorch-3dunet是一个跨平台软件包,也可以在Windows和OS X上运行。
pytorch-3dunet软件包的最简单方法是通过Conda/Mamba: conda install -c conda-forge mamba
mamba create -n pytorch-3dunet -c pytorch -c nvidia -c conda-forge pytorch pytorch-cuda=12.1 pytorch-3dunet
conda activate pytorch-3dunet
安装后,可以在Conda环境中访问以下命令: train3dunet用于训练网络和predict3dunet进行预测(请参见下文)。
python setup.py install
确保已安装的pytorch与您的CUDA版本兼容,否则培训/预测将无法在GPU上运行。
鉴于pytorch-3dunet软件包是通过CONDA安装的,因此可以通过简单调用网络来训练网络:
train3dunet --config <CONFIG>
其中CONFIG是YAML配置文件的路径,该文件指定了培训过程的所有方面。
为了培训您自己的数据,只需提供配置中HDF5培训和验证数据集的路径即可。
一个人可以使用张板tensorboard --logdir <checkpoint_dir>/logs/ (您需要安装在Conda Env中的tensorflow ),其中checkpoint_dir是在配置中指定的检查点目录的路径。
BCEWithLogitsLoss , DiceLoss , BCEDiceLoss , GeneralizedDiceLoss :目标数据必须为4D(每个频道一个目标二进制掩码)。 When training with WeightedCrossEntropyLoss , CrossEntropyLoss , PixelWiseCrossEntropyLoss the target dataset has to be 3D, see also pytorch documentation for CE loss: https://pytorch.org/docs/master/generated/torch.nn.CrossEntropyLoss.htmlmodel配置部分中的final_sigmoid仅适用于推理时间(验证,测试):BCEWithLogitsLoss , DiceLoss , BCEDiceLoss , GeneralizedDiceLoss Set final_sigmoid=TrueWeightedCrossEntropyLoss , CrossEntropyLoss , PixelWiseCrossEntropyLoss )设置final_sigmoid=False ,以便将Softmax归一化应用于输出。 鉴于pytorch-3dunet软件包是通过Conda安装的,因此可以通过以下方式进行预测:
predict3dunet --config <CONFIG>
为了在您自己的数据上进行预测,只需提供模型的路径以及HDF5测试文件的路径(请参阅示例test_config_segmentation.yaml)。
LazyHDF5Dataset和LazyPredictor 。这将通过以较慢的预测时间为代价来节省存储器,以节省内存。有关示例配置,请参见test_config_lazy。predictor部分中设置save_segmentation: true (请参阅test_config_multiclass)。 默认情况下,如果有多个GPU可用的培训/预测将使用DataParallel在所有GPU上运行。如果对所有可用GPU的培训/预测是不可取的,请使用CUDA_VISIBLE_DEVICES限制GPU的数量,例如
CUDA_VISIBLE_DEVICES=0,1 train3dunet --config < CONFIG >或者
CUDA_VISIBLE_DEVICES=0,1 predict3dunet --config < CONFIG > BCEWithLogitsLoss (二进制跨渗透)DiceLoss (标准的DiceLoss定义为1 - DiceCoefficient ;当地面真相中有2个以上的类别时,它将计算每个通道的DiceLoss并平均值)BCEDiceLoss (BCE和DICE损失的线性组合,即alpha * BCE + beta * Dice , alpha, beta可以在配置的loss部分中指定)CrossEntropyLoss (可以通过weight: [w_1, ..., w_k]在配置的loss部分中)PixelWiseCrossEntropyLoss (一个人可以指定每个像素权重,以便为地面真相中重要/代表性不足的区域提供更多梯度;必须在H5文件中提供培训和验证中weight数据集;请参阅trib_config.yml中的示例配置WeightedCrossEntropyLoss (有关详细说明,请参见下文中的“加权交叉凝胶(WCE)”)GeneralizedDiceLoss (请参阅以下论文中的“广义骰子损失(GDL)”以进行详细说明)注意:仅当训练数据集中的标签非常不平衡时,才能使用此损耗函数,例如一个具有至少3个数量级体素数的类,比其他类别要高3个数量级。否则,请使用标准的DiceLoss 。有关某些受支持的损失函数的详细说明,请参见:广义骰子重叠,作为高度不平衡分段的深度学习损失函数。
MSELoss (均值误差损失)L1Loss (平均绝对误差损失)SmoothL1Loss (对离群值不如Mseloss敏感)WeightedSmoothL1Loss ( SmoothL1Loss的延伸,允许在给定阈值以下/低于以下的体素值以不同的方式加权体素值) MeanIoU (联合的平均十字路口)DiceCoefficient (计算每个通道骰子系数的计算并返回平均值),如果训练了3D U-NET来预测细胞边界,则可以使用以下语义实例实例分割指标(以下是通过在阈值边界映射上运行连接的组件并将结果的实例与地面真相实例分割进行比较):BoundaryAveragePrecision (将平均精度应用于边界概率图:阈值来自网络的输出,运行连接的组件以获取分割并计算结果分割和地面真相之间的AP)AdaptedRandError (请参阅http://brainiac2.mit.edu/snemi3d/evaluation详细说明)AveragePrecision (请参阅https://www.kaggle.com/stkbailey/step-by-step-sexplanation-of-scoring-metric)如果未指定的话MeanIoU默认情况下将使用。
PSNR (峰信号与噪声比)MSE (均方根错误) 培训/预测配置可以在3dunet_lightsheet_boundary中找到。预先训练的模型权重。为了在您自己的数据上使用预训练的模型:
best_checkpoint.pytorchpredict3dunet --config test_config.ymlpre_trained属性定为best_checkpoint.pytorch路径来调整预训练模型。可以从以下OSF项目下载用于培训的数据:
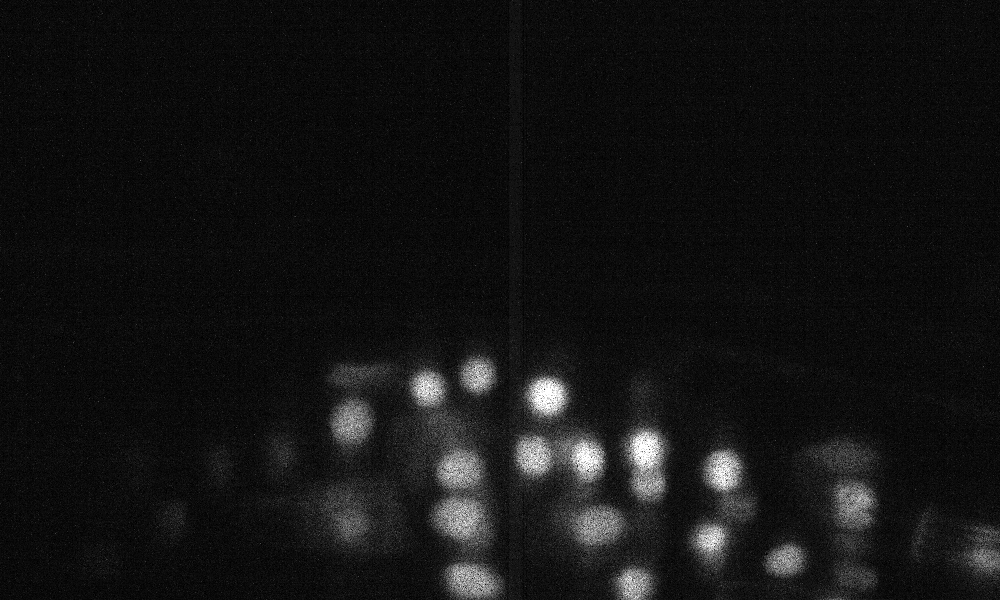
测试集上的样本Z片预测(顶部:原始输入,底部:边界预测):

培训/预测配置可以在3dunet_confocal_boundary中找到。预先训练的模型权重。为了在您自己的数据上使用预训练的模型:
best_checkpoint.pytorchpredict3dunet --config test_config.ymlpre_trained属性定为best_checkpoint.pytorch路径来调整预训练模型。可以从以下OSF项目下载用于培训的数据:
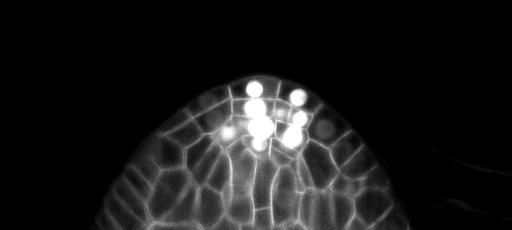
测试集上的样本Z片预测(顶部:原始输入,底部:边界预测):
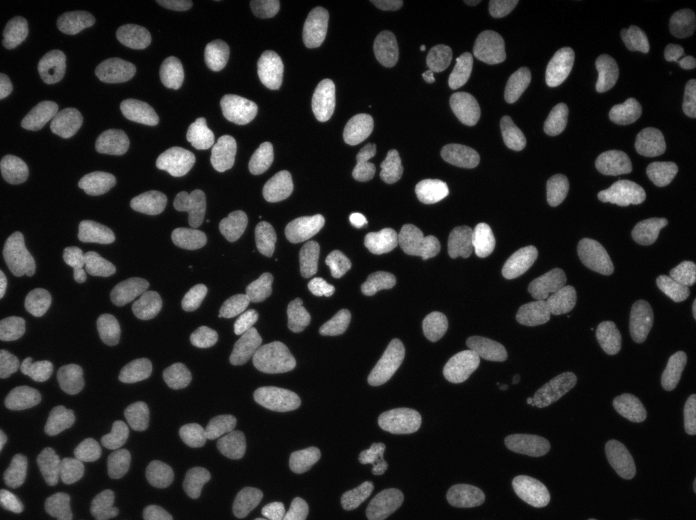
培训/预测配置可以在3Dunet_lightsheet_nuclei中找到。预先训练的模型权重。为了在您自己的数据上使用预训练的模型:
best_checkpoint.pytorchpredict3dunet --config test_config.ymlpre_trained属性定为best_checkpoint.pytorch路径来调整预训练模型。可以从以下OSF项目下载培训和验证集:https://osf.io/thxzn/
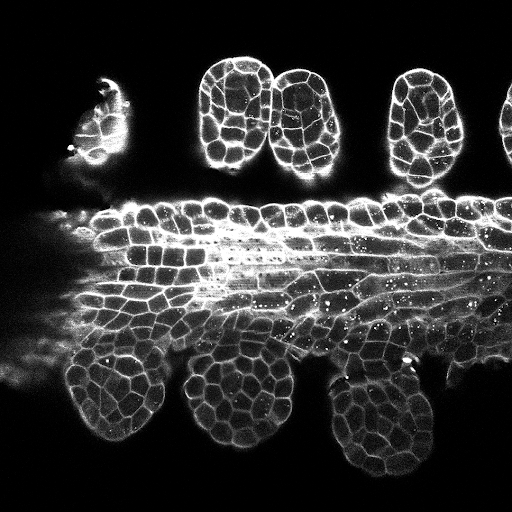
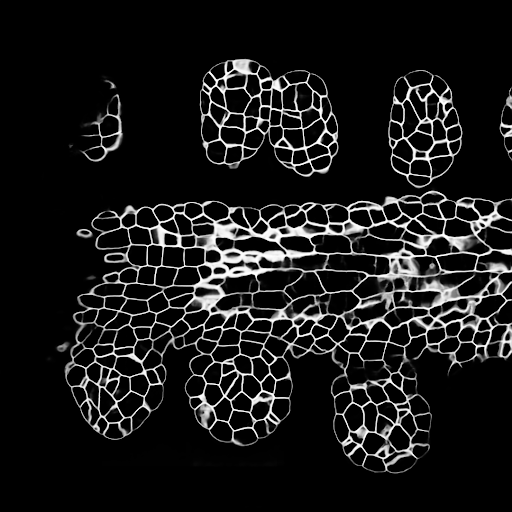
测试集的样品z板岩预测(顶部:原始输入,底部:核预测):

数据可以从以下下载:https://www.kaggle.com/c/data-science-bowl-2018/data
培训/预测配置可以在2dunet_dsb2018中找到。
测试图像的样本预测(顶部:原始输入,底部:核预测):

如果您想捐款,请提出拉请请求。
如果您使用此代码进行研究,请引用为:
@article {10.7554/eLife.57613,
article_type = {journal},
title = {Accurate and versatile 3D segmentation of plant tissues at cellular resolution},
author = {Wolny, Adrian and Cerrone, Lorenzo and Vijayan, Athul and Tofanelli, Rachele and Barro, Amaya Vilches and Louveaux, Marion and Wenzl, Christian and Strauss, Sören and Wilson-Sánchez, David and Lymbouridou, Rena and Steigleder, Susanne S and Pape, Constantin and Bailoni, Alberto and Duran-Nebreda, Salva and Bassel, George W and Lohmann, Jan U and Tsiantis, Miltos and Hamprecht, Fred A and Schneitz, Kay and Maizel, Alexis and Kreshuk, Anna},
editor = {Hardtke, Christian S and Bergmann, Dominique C and Bergmann, Dominique C and Graeff, Moritz},
volume = 9,
year = 2020,
month = {jul},
pub_date = {2020-07-29},
pages = {e57613},
citation = {eLife 2020;9:e57613},
doi = {10.7554/eLife.57613},
url = {https://doi.org/10.7554/eLife.57613},
keywords = {instance segmentation, cell segmentation, deep learning, image analysis},
journal = {eLife},
issn = {2050-084X},
publisher = {eLife Sciences Publications, Ltd},
}


