SincNet
1.0.0
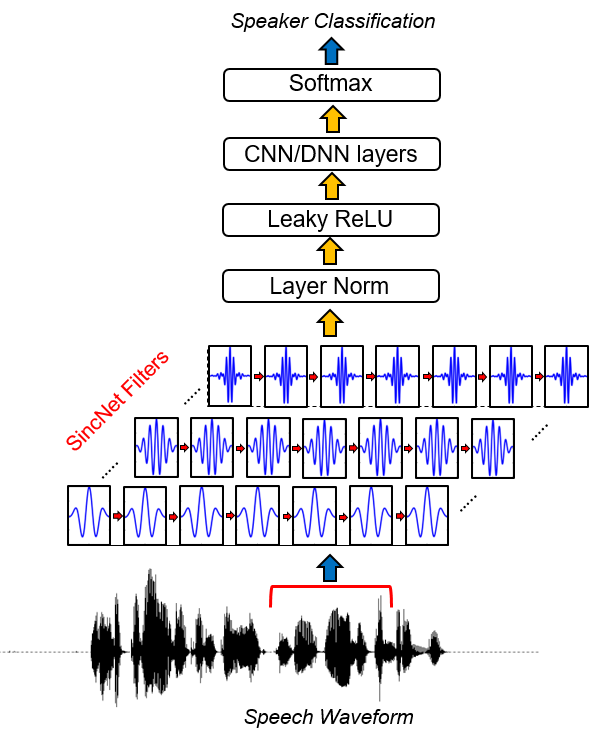
Sincnet是用于处理原始音频样品的神经体系结构。这是一个新颖的卷积神经网络(CNN),它鼓励第一卷积层发现更有意义的过滤器。 SINCNET基于实现带通滤波器的参数化SINC函数。
与标准CNN相比,学习每个滤波器的所有元素,只有使用建议的方法直接从数据中学习了低和高截止频率。这提供了一种非常紧凑,有效的方法,可以得出专门针对所需应用的定制过滤器库。
该项目释放了一系列代码和实用程序,以使用SINCNET执行说话者识别。提供了使用TIMIT数据库标识的说话者识别的示例。如果您对应用于语音识别的SINCNET感兴趣,则可以查看Pytorch-Kaldi Github存储库(https://github.com/mravanelli/pytorch-kaldi)。
看看我们的视频介绍Sincnet
如果您使用此代码或部分代码,请引用我们!
Mirco Ravanelli,Yoshua Bengio,“与Sincnet的Raw Woveform的发言人” Arxiv
conda install -c conda-forge pysoundfile )Sincnet也在语音脑(https://speechbrain.github.io/)项目中实施。我们鼓励您也要研究它!它是一个基于Pytorch的一合化语音处理工具包,目前支持语音识别,扬声器识别,SLU,语音增强,语音分离,多微米光音信号处理。它旨在灵活,易于使用,模块化且文献良好。一探究竟。
2019年2月16日:
即使代码可以轻松地适应任何语音数据集,但在文档的以下部分,我们提供了一个基于流行的Timit数据集的示例。
1。运行TIMIT数据准备。
此步骤对于存储一个圆锥形版的版本是必要的,在该版本中,删除了开始和末端的沉默,并将每个语音发音的幅度归一化。为此,运行以下代码:
python TIMIT_preparation.py $TIMIT_FOLDER $OUTPUT_FOLDER data_lists/TIMIT_all.scp
在哪里:
2。运行扬声器ID实验。
python speaker_id.py --cfg=cfg/SincNet_TIMIT.cfg
网络可能需要几个小时才能收敛(取决于您的GPU卡的速度)。在我们的情况下,使用NVIDIA TITAN X ,完整的培训大约需要24小时。如果在集群中使用代码,则至关重要的是将标准化数据集复制到本地节点,因为代码的当前版本需要经常访问存储的WAV文件。请注意,在此版本中未实现几种提高代码速度的可能优化,因为不超出此工作的范围。
3。结果。
结果将保存到CFG文件中指定的output_folder中。在此文件夹中,您可以找到一个文件( res.res )汇总培训和测试错误率。 Model_raw.pkl是最后一次迭代后保存的SINCNET模型。使用上面指定的CFG文件,我们获得以下结果:
epoch 0, loss_tr=5.542032 err_tr=0.984189 loss_te=4.996982 err_te=0.969038 err_te_snt=0.919913
epoch 8, loss_tr=1.693487 err_tr=0.434424 loss_te=2.735717 err_te=0.612260 err_te_snt=0.069264
epoch 16, loss_tr=0.861834 err_tr=0.229424 loss_te=2.465258 err_te=0.520276 err_te_snt=0.038240
epoch 24, loss_tr=0.528619 err_tr=0.144375 loss_te=2.948707 err_te=0.534053 err_te_snt=0.062049
epoch 32, loss_tr=0.362914 err_tr=0.100518 loss_te=2.530276 err_te=0.469060 err_te_snt=0.015152
epoch 40, loss_tr=0.267921 err_tr=0.076445 loss_te=2.761606 err_te=0.464799 err_te_snt=0.023088
epoch 48, loss_tr=0.215479 err_tr=0.061406 loss_te=2.737486 err_te=0.453493 err_te_snt=0.010823
epoch 56, loss_tr=0.173690 err_tr=0.050732 loss_te=2.812427 err_te=0.443322 err_te_snt=0.011544
epoch 64, loss_tr=0.145256 err_tr=0.043594 loss_te=2.917569 err_te=0.438507 err_te_snt=0.009380
epoch 72, loss_tr=0.128894 err_tr=0.038486 loss_te=3.009008 err_te=0.438005 err_te_snt=0.019481
....
epoch 320, loss_tr=0.033052 err_tr=0.009639 loss_te=4.076542 err_te=0.416710 err_te_snt=0.006494
epoch 328, loss_tr=0.033344 err_tr=0.010117 loss_te=3.928874 err_te=0.415024 err_te_snt=0.007215
epoch 336, loss_tr=0.033228 err_tr=0.010166 loss_te=4.030224 err_te=0.410034 err_te_snt=0.005051
epoch 344, loss_tr=0.033313 err_tr=0.010166 loss_te=4.402949 err_te=0.428691 err_te_snt=0.009380
epoch 352, loss_tr=0.031828 err_tr=0.009238 loss_te=4.080747 err_te=0.414066 err_te_snt=0.006494
epoch 360, loss_tr=0.033095 err_tr=0.009600 loss_te=4.254683 err_te=0.419954 err_te_snt=0.005772
收敛最初非常快(请参阅前30个时期)。之后,出现了句子错误率性能中的性能提高和振荡。尽管这些振荡可以观察到后续时期的平均改善趋势。在这项实验中,我们在Epoch 360上停止了培训。Res.res.res.文件的字段具有以下含义:
您可以在此处找到我们训练有素的模型。
要查看SINCNET实现,您应该打开文件dnn_models.py并读取SINCNET , SINC_CONV和函数SINC的类。
在此存储库中,我们将Timit数据集用作教程,以显示SINCNET的工作原理。使用当前版本的代码,您可以轻松使用其他语料库。为此,您应该在输入特定于Corpora的输入文件(以WAV格式)和您自己的标签中提供。因此,您应该将路径修改为在data_lists文件夹中找到的 *.scp文件。
要将正确标签分配给每个句子,您还必须修改字典“ timit_labels.npy ”。标签是在Python字典中指定的,该字典包含句子ID作为键(例如“ SI1027 ”)和Speaker_IDS作为值。每个扬声器_ID都是一个整数,范围从0到N_SPKS-1。在TIMIT数据集中,您可以轻松地从路径中检索扬声器ID(例如, train/dr1/fcjf0/si1027.wav是句子_id“ si1027 ”,由扬声器“ fcjf0 ”说明)。对于其他数据集,您应该能够以包含扬声器和句子ID对的字典来检索。
然后,应根据您的新路径修改配置文件( CFG/SINCNET_TIMIT.CFG )。还请记住,根据数据集中的扬声器n_spk的数量,更改字段“ class_lay = 462 ”。
本文中使用的LibrisPeech数据集的版本可应要求提供。在我们的工作中,我们只为每个说话者使用了12-15秒的培训材料,并处理了原始的LibrisPeech句子以执行幅度归一化。此外,我们使用了一个简单的基于能量的VAD来避免在每个句子的开头和结尾处沉默,并在多个块中分裂的句子,这些句子包含更长的寂静
[1] Mirco Ravanelli,Yoshua Bengio,“与Sincnet的Raw Woveform的说话者” Arxiv


