SincNet
1.0.0
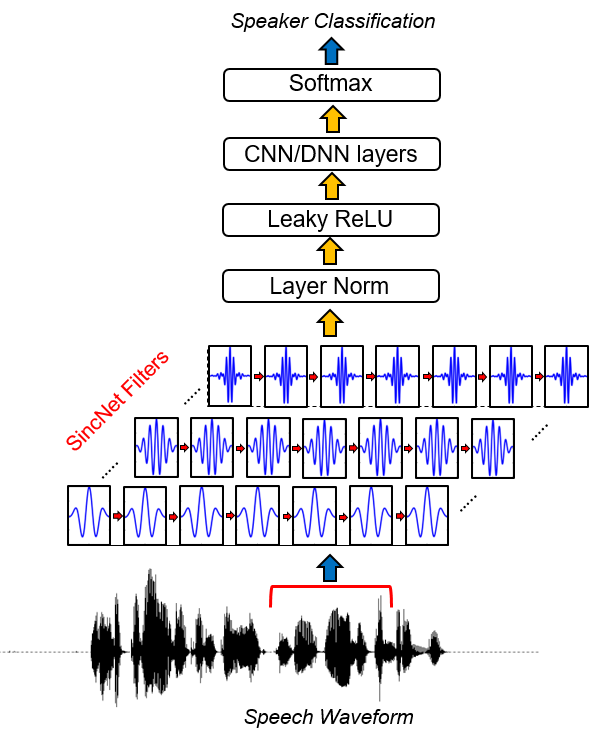
SINCNETは、生のオーディオサンプルを処理するためのニューラルアーキテクチャです。これは、より意味のあるフィルターを発見するための最初の畳み込み層を奨励する新しい畳み込みニューラルネットワーク(CNN)です。 SINCNETは、バンドパスフィルターを実装するパラメーター化されたSINC関数に基づいています。
標準のCNNとは対照的に、各フィルターのすべての要素を学習し、低および高カットオフ周波数のみが提案された方法でデータから直接学習されます。これにより、非常にコンパクトで効率的な方法が提供され、目的のアプリケーション用に特別に調整されたカスタマイズされたフィルターバンクを導き出します。
このプロジェクトは、Sincnetでスピーカーの識別を実行するために、コードとユーティリティのコレクションをリリースします。 TIMITデータベースとのスピーカー識別の例が提供されます。 SINCNETが音声認識に適用されることに興味がある場合は、Pytorch-Kaldi Githubリポジトリ(https://github.com/mravanelli/pytorch-kaldi)をご覧ください。
Sincnetのビデオ紹介をご覧ください
このコードまたはその一部を使用する場合は、私たちを引用してください!
Mirco Ravanelli、Yoshua Bengio、「sincnetを使用した生の波形からのスピーカー認識」 arxiv
conda install -c conda-forge pysoundfile )SINCNETは、SpeechBrain(https://speechbrain.github.io/)プロジェクトにも実装されています。同様に、それを調べることをお勧めします!これは、音声認識、スピーカー認識、SLU、音声強化、音声分離、マルチミクロファン信号処理をサポートしているオールインワンのPytorchベースの音声処理ツールキットです。柔軟性があり、使いやすく、モジュール式で、十分に文書化されているように設計されています。それをチェックしてください。
2019年2月16日:
コードをあらゆるスピーチデータセットに簡単に調整できますが、ドキュメントの以下の部分では、人気のあるTimitデータセットに基づいた例を提供します。
1.タイミットデータの準備を実行します。
このステップは、開始と終了のサイレンスが削除され、各音声発話の振幅が正規化されるTimitのバージョンを保存するために必要です。それを行うには、次のコードを実行します。
python TIMIT_preparation.py $TIMIT_FOLDER $OUTPUT_FOLDER data_lists/TIMIT_all.scp
どこ:
2。スピーカーID実験を実行します。
python speaker_id.py --cfg=cfg/SincNet_TIMIT.cfg
ネットワークは収束に数時間かかる場合があります(GPUカードの速度に応じて)。私たちの場合、 Nvidia Titan Xを使用して、完全なトレーニングには約24時間かかりました。クラスター内のコードを使用する場合、コードの現在のバージョンには保存されたWAVファイルに頻繁にアクセスする必要があるため、正規化されたデータセットをローカルノードにコピーするために重要です。この作業の範囲外であるため、このバージョンではコード速度を改善するためのいくつかの可能な最適化は実装されていません。
3。結果。
結果は、CFGファイルで指定されたoutput_folderに保存されます。このフォルダーでは、トレーニングとテストエラー率を要約するファイル( Res.Res )を見つけることができます。 Model Model_raw.pklは、最後のイテレーションの後に保存されたSINCNETモデルです。上記のCFGファイルを使用して、次の結果を取得します。
epoch 0, loss_tr=5.542032 err_tr=0.984189 loss_te=4.996982 err_te=0.969038 err_te_snt=0.919913
epoch 8, loss_tr=1.693487 err_tr=0.434424 loss_te=2.735717 err_te=0.612260 err_te_snt=0.069264
epoch 16, loss_tr=0.861834 err_tr=0.229424 loss_te=2.465258 err_te=0.520276 err_te_snt=0.038240
epoch 24, loss_tr=0.528619 err_tr=0.144375 loss_te=2.948707 err_te=0.534053 err_te_snt=0.062049
epoch 32, loss_tr=0.362914 err_tr=0.100518 loss_te=2.530276 err_te=0.469060 err_te_snt=0.015152
epoch 40, loss_tr=0.267921 err_tr=0.076445 loss_te=2.761606 err_te=0.464799 err_te_snt=0.023088
epoch 48, loss_tr=0.215479 err_tr=0.061406 loss_te=2.737486 err_te=0.453493 err_te_snt=0.010823
epoch 56, loss_tr=0.173690 err_tr=0.050732 loss_te=2.812427 err_te=0.443322 err_te_snt=0.011544
epoch 64, loss_tr=0.145256 err_tr=0.043594 loss_te=2.917569 err_te=0.438507 err_te_snt=0.009380
epoch 72, loss_tr=0.128894 err_tr=0.038486 loss_te=3.009008 err_te=0.438005 err_te_snt=0.019481
....
epoch 320, loss_tr=0.033052 err_tr=0.009639 loss_te=4.076542 err_te=0.416710 err_te_snt=0.006494
epoch 328, loss_tr=0.033344 err_tr=0.010117 loss_te=3.928874 err_te=0.415024 err_te_snt=0.007215
epoch 336, loss_tr=0.033228 err_tr=0.010166 loss_te=4.030224 err_te=0.410034 err_te_snt=0.005051
epoch 344, loss_tr=0.033313 err_tr=0.010166 loss_te=4.402949 err_te=0.428691 err_te_snt=0.009380
epoch 352, loss_tr=0.031828 err_tr=0.009238 loss_te=4.080747 err_te=0.414066 err_te_snt=0.006494
epoch 360, loss_tr=0.033095 err_tr=0.009600 loss_te=4.254683 err_te=0.419954 err_te_snt=0.005772
収束は最初は非常に高速です(最初の30エポックを参照)。その後、パフォーマンスの改善が減少し、文のエラー率のパフォーマンスが表示されます。これらの振動にもかかわらず、その後のエポックでは平均改善傾向が観察できます。この実験では、Epoch 360でトレーニングを停止しました。Res.Resファイルのフィールドには次の意味があります。
Timitの訓練されたモデルをここで見つけることができます。
SINCNETの実装を調べるには、ファイルdnn_models.pyを開き、 sincnet 、 sinc_conv 、およびfunction sincを読む必要があります。
このリポジトリでは、Timitデータセットをチュートリアルとして使用して、SINCNETの仕組みを示しました。コードの現在のバージョンを使用すると、別のコーパスを簡単に使用できます。それを行うには、corpora固有の入力ファイル(WAV形式)と独自のラベルを入力して提供する必要があります。したがって、Data_Listsフォルダーにある *.SCPファイルへのパスを変更する必要があります。
各文に正しいラベルを割り当てるには、辞書「 timit_labels.npy 」も変更する必要があります。ラベルは、キーとして文IDを含むPython辞書内(例: " Si1027 ")およびSpeaker_idsを値として指定します。各スピーカー_IDは、0からN_SPKS-1の範囲の整数です。 TIMITデータセットでは、パスからスピーカーIDを簡単に取得できます(例: Train/DR1/FCJF0/SI1027.WAVは、スピーカー「 FCJF0 」で発せられるdente_id " si1027 ")。他のデータセットの場合、スピーカーのペアと文IDのペアを含むこの辞書をそのような方法で取得できるはずです。
次に、新しいパスに従って構成ファイル( CFG/SINCNET_TIMIT.CFG )を変更する必要があります。また、データセットにあるスピーカーn_spksの数に従って、フィールド「 class_lay = 462 」を変更することも忘れないでください。
論文で使用されるLibrispeechデータセットのバージョンは、リクエストに応じて入手できます。私たちの作業では、スピーカーごとに12〜15秒のトレーニング資料しか使用しておらず、振幅正規化を実行するために元のLibrispeech文を処理しました。さらに、単純なエネルギーベースのVADを使用して、各文の最初と終わりに沈黙を避け、複数の沈黙を含む文を複数のチャンクに分割しました
[1] Mirco Ravanelli、Yoshua Bengio、「sincnetを使用した生の波形からのスピーカー認識」arxiv


