SincNet
1.0.0
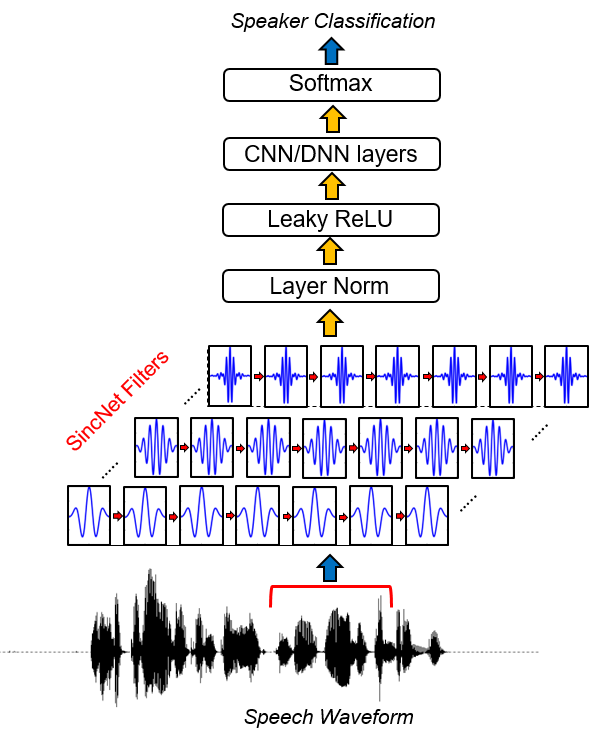
A Sincnet é uma arquitetura neural para processar amostras de áudio cruas . É uma nova rede neural convolucional (CNN) que incentiva a primeira camada convolucional a descobrir filtros mais significativos . O Sincnet é baseado em funções SINC parametrizadas, que implementam filtros de passagem de banda.
Em contraste com os CNNs padrão, que aprendem todos os elementos de cada filtro, apenas frequências de corte baixo e alto são aprendidas diretamente com os dados com o método proposto. Isso oferece uma maneira muito compacta e eficiente de derivar um banco de filtro personalizado especificamente sintonizado para o aplicativo desejado.
Este projeto libera uma coleção de códigos e serviços públicos para realizar a identificação do alto -falante com a Sincnet. Um exemplo de identificação do alto -falante com o banco de dados Timit é fornecido. Se você estiver interessado em Sincnet solicitada ao reconhecimento de fala, pode dar uma olhada no repositório Pytorch-Kaldi Github (https://github.com/mravanelli/pytorch-kaldi).
Dê uma olhada em nosso vídeo Introdução à Sincnet
Se você usar este código ou parte dele, cite -nos!
Mirco Ravanelli, Yoshua Bengio, “Reconhecimento de alto -falantes da forma de onda bruta com Sincnet” Arxiv
conda install -c conda-forge pysoundfile )A Sincnet é implementada no projeto Speechbrain (https://speechbrain.github.io/). Nós o encorajamos a dar uma olhada nele também! É um kit de ferramentas de processamento de fala baseado em Pytorch, baseado em Pytorch, que atualmente suporta reconhecimento de fala, reconhecimento de alto-falante, SLU, aprimoramento da fala, separação de fala, processamento de sinal multi-microfone. Ele foi projetado para ser flexível, fácil de usar, modular e bem documentado. Confira.
16 de fevereiro de 2019:
Embora o código possa ser facilmente adaptado a qualquer conjunto de dados de fala, na parte a seguir da documentação, fornecemos um exemplo com base no conjunto de dados TIMIT popular.
1. Execute a preparação dos dados do Timit.
Esta etapa é necessária para armazenar uma versão do Timit na qual os silêncios de início e final são removidos e a amplitude de cada expressão de fala é normalizada. Para fazer isso, execute o seguinte código:
python TIMIT_preparation.py $TIMIT_FOLDER $OUTPUT_FOLDER data_lists/TIMIT_all.scp
onde:
2. Execute o experimento de identificação do alto -falante.
python speaker_id.py --cfg=cfg/SincNet_TIMIT.cfg
A rede pode levar várias horas para convergir (dependendo da velocidade do seu cartão GPU). No nosso caso, usando um Nvidia Titan X , o treinamento completo levou cerca de 24 horas. Se você usar o código em um cluster, for crucial para copiar o conjunto de dados normalizado no nó local, pois a versão atual do código requer acessos frequentes aos arquivos WAV armazenados. Observe que várias otimizações possíveis para melhorar a velocidade do código não são implementadas nesta versão, pois estão fora do escopo deste trabalho.
3. Resultados.
Os resultados são salvos no output_folder especificado no arquivo CFG. Nesta pasta, você pode encontrar um arquivo ( res.res ) resumindo as taxas de erro e teste de teste. O modelo Model_raw.pkl é o modelo Sincnet salvo após a última iteração. Usando o arquivo CFG especificado acima, obtemos os seguintes resultados:
epoch 0, loss_tr=5.542032 err_tr=0.984189 loss_te=4.996982 err_te=0.969038 err_te_snt=0.919913
epoch 8, loss_tr=1.693487 err_tr=0.434424 loss_te=2.735717 err_te=0.612260 err_te_snt=0.069264
epoch 16, loss_tr=0.861834 err_tr=0.229424 loss_te=2.465258 err_te=0.520276 err_te_snt=0.038240
epoch 24, loss_tr=0.528619 err_tr=0.144375 loss_te=2.948707 err_te=0.534053 err_te_snt=0.062049
epoch 32, loss_tr=0.362914 err_tr=0.100518 loss_te=2.530276 err_te=0.469060 err_te_snt=0.015152
epoch 40, loss_tr=0.267921 err_tr=0.076445 loss_te=2.761606 err_te=0.464799 err_te_snt=0.023088
epoch 48, loss_tr=0.215479 err_tr=0.061406 loss_te=2.737486 err_te=0.453493 err_te_snt=0.010823
epoch 56, loss_tr=0.173690 err_tr=0.050732 loss_te=2.812427 err_te=0.443322 err_te_snt=0.011544
epoch 64, loss_tr=0.145256 err_tr=0.043594 loss_te=2.917569 err_te=0.438507 err_te_snt=0.009380
epoch 72, loss_tr=0.128894 err_tr=0.038486 loss_te=3.009008 err_te=0.438005 err_te_snt=0.019481
....
epoch 320, loss_tr=0.033052 err_tr=0.009639 loss_te=4.076542 err_te=0.416710 err_te_snt=0.006494
epoch 328, loss_tr=0.033344 err_tr=0.010117 loss_te=3.928874 err_te=0.415024 err_te_snt=0.007215
epoch 336, loss_tr=0.033228 err_tr=0.010166 loss_te=4.030224 err_te=0.410034 err_te_snt=0.005051
epoch 344, loss_tr=0.033313 err_tr=0.010166 loss_te=4.402949 err_te=0.428691 err_te_snt=0.009380
epoch 352, loss_tr=0.031828 err_tr=0.009238 loss_te=4.080747 err_te=0.414066 err_te_snt=0.006494
epoch 360, loss_tr=0.033095 err_tr=0.009600 loss_te=4.254683 err_te=0.419954 err_te_snt=0.005772
O converge é inicialmente muito rápido (consulte as 30 primeiras épocas). Depois disso, a melhoria do desempenho diminui e os oscilações no desempenho da taxa de erro da sentença aparecem. Apesar dessas oscilações, uma tendência média de melhoria pode ser observada nas épocas subsequentes. Neste experimento, paramos nosso treinamento na Epoch 360. Os campos do arquivo res.Res têm o seguinte significado:
Você pode encontrar nosso modelo treinado para Timit aqui.
Para dar uma olhada na implementação da Sincnet, você deve abrir o arquivo dnn_models.py e ler as classes Sincnet , SINC_CONV e a função SINC .
Neste repositório, usamos o conjunto de dados Timit como um tutorial para mostrar como a Sincnet funciona. Com a versão atual do código, você pode usar facilmente um corpus diferente. Para fazer isso, você deve fornecer em entrada os arquivos de entrada específicos do Corpora (no formato WAV) e seus próprios rótulos. Assim, você deve modificar os caminhos nos arquivos *.scp encontrados na pasta Data_Lists.
Para atribuir a cada frase o rótulo certo, você também deve modificar o dicionário " timit_labels.npy ". Os rótulos são especificados dentro de um dicionário Python que contém IDs de sentença como chaves (por exemplo, " SI1027 ") e Speaker_ids como valores. Cada spoer_id é um número inteiro, variando de 0 a n_spks-1. No conjunto de dados Timit, você pode recuperar facilmente o ID do alto -falante do caminho (por exemplo, trem/dr1/fcjf0/si1027.wav é a sentença_id " Si1027 " proferida pelo alto -falante " fcjf0 "). Para outros conjuntos de dados, você poderá recuperar de tal maneira que este dicionário contenha pares de alto -falantes e IDs de sentença.
Você deve modificar o arquivo de configuração ( cfg/sincnet_timit.cfg ) de acordo com seus novos caminhos. Lembre -se também de alterar o campo " Class_lay = 462 " de acordo com o número de alto -falantes N_SPKS que você possui no seu conjunto de dados.
A versão do conjunto de dados do LibreseCech usado no papel está disponível mediante solicitação . Em nosso trabalho, usamos apenas 12-15 segundos de material de treinamento para cada falante e processamos as frases originais do Librispeech para realizar a normalização da amplitude. Além disso, usamos um VAD simples baseado em energia para evitar silêncios no início e no final de cada frase, bem como dividir em vários pedaços as frases que contêm silêncio mais longo
[1] Mirco Ravanelli, Yoshua Bengio, “Reconhecimento de alto -falantes da forma de onda bruta com Sincnet” Arxiv


