SincNet
1.0.0
Sincnet является нейронной архитектурой для обработки необработанных образцов звука . Это новая сверточная нейронная сеть (CNN), которая поощряет первый сверточный слой открывать более значимые фильтры . Sincnet основан на параметризованных функциях SINC, которые реализуют полосовые фильтры.
В отличие от стандартных CNN, которые изучают все элементы каждого фильтра, только частоты с низким и высоким разрезом непосредственно изучаются из данных с предложенным методом. Это предлагает очень компактный и эффективный способ получить индивидуальный банк фильтров, специально настроенный для желаемого приложения.
Этот проект выпускает коллекцию кодов и утилит для выполнения идентификации докладчиков с Sincnet. Приведен пример идентификации динамика с базой данных TIMIT. Если вы заинтересованы в Sincnet, применяемом к распознаванию речи, вы можете посмотреть в репозиторий Pytorch-kaldi Github (https://github.com/mravanelli/pytorch-kaldi).
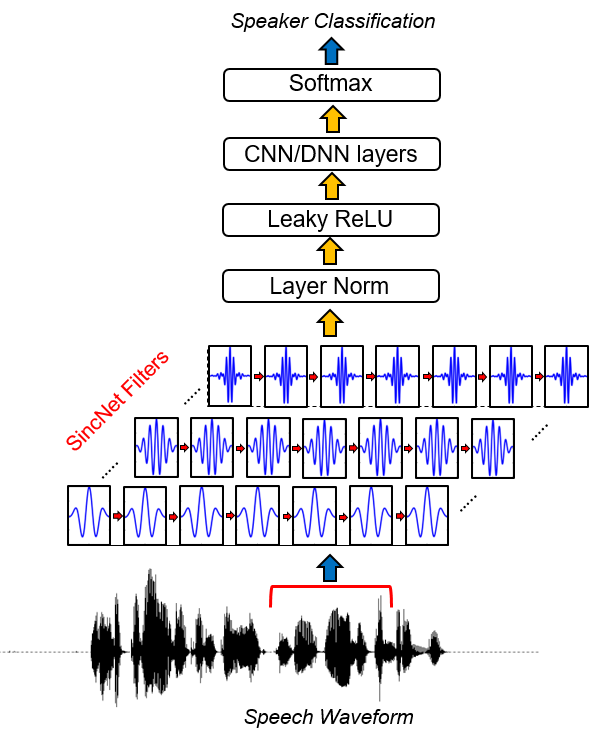
Посмотрите на наше видео введение в Sincnet
Если вы используете этот код или его часть, пожалуйста, цитируйте нас!
Mirco Ravanelli, Yoshua Bengio, «Распознавание спикеров от Raw Formeform с Sincnet» Arxiv
conda install -c conda-forge pysoundfile )Sincnet реализован в проекте SpeechBrain (https://speechbrain.github.io/). Мы призываем вас взглянуть на это! Это инструментарий речи на основе речи на основе Pytorch, который в настоящее время поддерживает распознавание речи, распознавание динамиков, SLU, улучшение речи, разделение речи, обработку мультимикрофона. Он предназначен для того, чтобы быть гибким, простым в использовании, модульной и хорошо документированной. Проверьте это.
16 февраля 2019 года:
Несмотря на то, что код может быть легко адаптирован к любому набору данных речи, в следующей части документации мы приведем пример, основанный на популярном наборе данных Timit.
1. Запустите подготовку данных Timit.
Этот шаг необходим для хранения версии Timit, в которой удаляются начало и конечные молния, а амплитуда каждого высказывания речи нормализуется. Для этого запустите следующий код:
python TIMIT_preparation.py $TIMIT_FOLDER $OUTPUT_FOLDER data_lists/TIMIT_all.scp
где:
2. Запустите эксперимент с динамиком.
python speaker_id.py --cfg=cfg/SincNet_TIMIT.cfg
Сеть может занять несколько часов, чтобы сходиться (в зависимости от скорости вашей карты GPU). В нашем случае, используя Nvidia Titan X , полная тренировка заняла около 24 часов. Если вы используете код в кластере, имеет решающее значение для копирования нормализованного набора данных в локальный узел, поскольку текущая версия кода требует частых доступа к хранимым файлам WAV. Обратите внимание, что несколько возможных оптимизаций для улучшения скорости кода не реализованы в этой версии, так как выходит за рамки этой работы.
3. Результаты.
Результаты сохраняются в output_folder, указанном в файле CFG. В этой папке вы можете найти файл ( res.res ), обобщающий уровень обучения и ошибок тестирования. Model Model_raw.pkl - это модель Sincnet, сохраненная после последней итерации. Используя файл CFG, указанный выше, мы получаем следующие результаты:
epoch 0, loss_tr=5.542032 err_tr=0.984189 loss_te=4.996982 err_te=0.969038 err_te_snt=0.919913
epoch 8, loss_tr=1.693487 err_tr=0.434424 loss_te=2.735717 err_te=0.612260 err_te_snt=0.069264
epoch 16, loss_tr=0.861834 err_tr=0.229424 loss_te=2.465258 err_te=0.520276 err_te_snt=0.038240
epoch 24, loss_tr=0.528619 err_tr=0.144375 loss_te=2.948707 err_te=0.534053 err_te_snt=0.062049
epoch 32, loss_tr=0.362914 err_tr=0.100518 loss_te=2.530276 err_te=0.469060 err_te_snt=0.015152
epoch 40, loss_tr=0.267921 err_tr=0.076445 loss_te=2.761606 err_te=0.464799 err_te_snt=0.023088
epoch 48, loss_tr=0.215479 err_tr=0.061406 loss_te=2.737486 err_te=0.453493 err_te_snt=0.010823
epoch 56, loss_tr=0.173690 err_tr=0.050732 loss_te=2.812427 err_te=0.443322 err_te_snt=0.011544
epoch 64, loss_tr=0.145256 err_tr=0.043594 loss_te=2.917569 err_te=0.438507 err_te_snt=0.009380
epoch 72, loss_tr=0.128894 err_tr=0.038486 loss_te=3.009008 err_te=0.438005 err_te_snt=0.019481
....
epoch 320, loss_tr=0.033052 err_tr=0.009639 loss_te=4.076542 err_te=0.416710 err_te_snt=0.006494
epoch 328, loss_tr=0.033344 err_tr=0.010117 loss_te=3.928874 err_te=0.415024 err_te_snt=0.007215
epoch 336, loss_tr=0.033228 err_tr=0.010166 loss_te=4.030224 err_te=0.410034 err_te_snt=0.005051
epoch 344, loss_tr=0.033313 err_tr=0.010166 loss_te=4.402949 err_te=0.428691 err_te_snt=0.009380
epoch 352, loss_tr=0.031828 err_tr=0.009238 loss_te=4.080747 err_te=0.414066 err_te_snt=0.006494
epoch 360, loss_tr=0.033095 err_tr=0.009600 loss_te=4.254683 err_te=0.419954 err_te_snt=0.005772
Конверг изначально очень быстро (см. Первые 30 эпох). После этого улучшение производительности уменьшается и колебания в результате показателя ошибок предложения появляются. Несмотря на эти колебания, для последующих эпох может наблюдаться средняя тенденция улучшения. В этом эксперименте мы прекратили наше обучение в Epoch 360. Поля файла Res.Res имеют следующее значение:
Вы можете найти нашу обученную модель для Timit здесь.
Чтобы посмотреть на реализацию Sincnet, вы должны открыть файл dnn_models.py и прочитать классы Sincnet , Sinc_conv и функцию Sinc .
В этом репозитории мы использовали набор данных Timit в качестве учебника, чтобы показать, как работает Sincnet. С текущей версией кода вы можете легко использовать другой корпус. Чтобы сделать это, вы должны предоставить при вводе входные входные файлы, специфичные для корпора (в формате WAV) и свои собственные этикетки. Таким образом, вы должны изменить пути в файлы *.scp, которые вы найдете в папке Data_lists.
Чтобы присвоить каждому предложению правую метку, вы также должны изменить словарь " timit_labels.npy ". Метки указаны в словаре Python, который содержит идентификаторы предложений в виде ключей (например, « Si1027 ») и Speaker_ids как значения. Каждый Speaker_id является целым числом, от 0 до N_SPKS-1. В наборе данных Timit вы можете легко извлечь идентификатор динамика с пути (например, Train/DR1/FCJF0/SI1027.WAV - это предложение_ид " si1027 ", произнесенный говорящим " fcjf0 "). Для других наборов данных вы должны быть в состоянии получить таким образом, что этот словарь, содержащий пары динамиков и идентификаторы предложений.
Затем вам следует изменить файл конфигурации ( cfg/sincnet_timit.cfg ) в соответствии с вашими новыми путями. Помните также, чтобы изменить поле « class_lay = 462 » в соответствии с количеством динамиков, которые у вас есть в вашем наборе данных.
Версия набора данных Librispeech, используемой в статье, доступна по запросу . В нашей работе мы использовали только 12-15 секунд учебного материала для каждого динамика, и мы обработали исходные предложения Librispeech, чтобы выполнить нормализацию амплитуды. Более того, мы использовали простой энергетический VAD, чтобы избежать молчания в начале и конце каждого предложения, а также для разделения нескольких кусков предложения, содержащие более длинное молчание
[1] Mirco Ravanelli, Yoshua Bengio, «Распознавание динамиков от Raw Forme с Sincnet» Arxiv


