SincNet
1.0.0
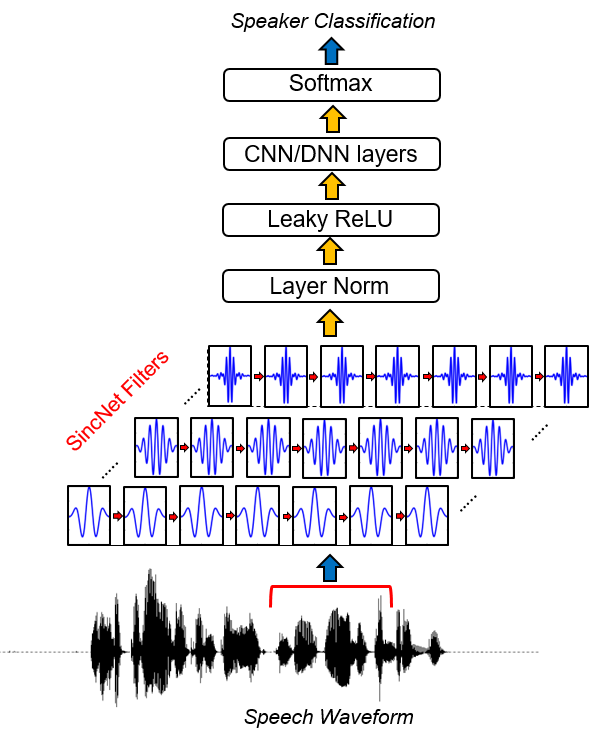
Sincnet est une architecture neuronale pour le traitement des échantillons audio bruts . Il s'agit d'un nouveau réseau neuronal convolutionnel (CNN) qui encourage la première couche convolutionnelle à découvrir des filtres plus significatifs . SINCNET est basé sur des fonctions SINC paramétrisées, qui implémentent des filtres de passe-bande.
Contrairement aux CNN standard, qui apprennent tous les éléments de chaque filtre, seules les fréquences de coupure faibles et élevées sont directement tirées des données avec la méthode proposée. Cela offre un moyen très compact et efficace de dériver une banque de filtre personnalisée spécialement réglée pour l'application souhaitée.
Ce projet libère une collection de codes et d'utilitaires pour effectuer l'identification des haut-parleurs avec Sincnet. Un exemple d'identification des haut-parleurs avec la base de données TIMIT est fourni. Si vous êtes intéressé par Sincnet appliquée à la reconnaissance de la parole, vous pouvez jeter un coup d'œil dans le référentiel Pytorch-Kaldi Github (https://github.com/mravanelli/pytorch-kaldi).
Jetez un œil à notre vidéo Introduction à Sincnet
Si vous en utilisez ce code ou une partie, veuillez nous citer!
Mirco Ravanelli, Yoshua Bengio, «Reconnaissance des haut-parleurs de la forme d'onde brute avec Sincnet» Arxiv
conda install -c conda-forge pysoundfile )Sincnet est implémenté dans le projet SpeechBrain (https://speechbrain.github.io/). Nous vous encourageons également à y jeter un œil! Il s'agit d'une boîte à outils de traitement de la parole basée sur Pytorch tout-en-un qui prend actuellement en charge la reconnaissance de la parole, la reconnaissance des conférenciers, le SLU, l'amélioration de la parole, la séparation de la parole, le traitement du signal multi-microphone. Il est conçu pour être flexible, facile à utiliser, modulaire et bien documenté. Vérifiez-le.
16 février 2019:
Même si le code peut être facilement adapté à n'importe quel ensemble de données vocal, dans la partie suivante de la documentation, nous fournissons un exemple basé sur le jeu de données TIMIT populaire.
1. Exécutez la préparation des données TIMIT.
Cette étape est nécessaire pour stocker une version de TIMIT dans laquelle les silences de démarrage et de fin sont supprimés et l'amplitude de chaque énoncé de parole est normalisée. Pour le faire, exécutez le code suivant:
python TIMIT_preparation.py $TIMIT_FOLDER $OUTPUT_FOLDER data_lists/TIMIT_all.scp
où:
2. Exécutez l'expérience d'identification du haut-parleur.
python speaker_id.py --cfg=cfg/SincNet_TIMIT.cfg
Le réseau peut prendre plusieurs heures pour converger (selon la vitesse de votre carte GPU). Dans notre cas, en utilisant un Nvidia Titan X , la formation complète a pris environ 24 heures. Si vous utilisez le code dans un cluster est crucial pour copier l'ensemble de données normalisé dans le nœud local, car la version actuelle du code nécessite des accès fréquents aux fichiers WAV stockés. Notez que plusieurs optimisations possibles pour améliorer la vitesse du code ne sont pas implémentées dans cette version car sont hors de portée de ce travail.
3. Résultats.
Les résultats sont enregistrés dans le fichier Output_Folder spécifié dans le fichier CFG. Dans ce dossier, vous pouvez trouver un fichier ( res.res ) résumant les taux d'erreur de formation et de test. Le modèle modèle_raw.pkl est le modèle SincNet enregistré après la dernière itération. En utilisant le fichier CFG spécifié ci-dessus, nous obtenons les résultats suivants:
epoch 0, loss_tr=5.542032 err_tr=0.984189 loss_te=4.996982 err_te=0.969038 err_te_snt=0.919913
epoch 8, loss_tr=1.693487 err_tr=0.434424 loss_te=2.735717 err_te=0.612260 err_te_snt=0.069264
epoch 16, loss_tr=0.861834 err_tr=0.229424 loss_te=2.465258 err_te=0.520276 err_te_snt=0.038240
epoch 24, loss_tr=0.528619 err_tr=0.144375 loss_te=2.948707 err_te=0.534053 err_te_snt=0.062049
epoch 32, loss_tr=0.362914 err_tr=0.100518 loss_te=2.530276 err_te=0.469060 err_te_snt=0.015152
epoch 40, loss_tr=0.267921 err_tr=0.076445 loss_te=2.761606 err_te=0.464799 err_te_snt=0.023088
epoch 48, loss_tr=0.215479 err_tr=0.061406 loss_te=2.737486 err_te=0.453493 err_te_snt=0.010823
epoch 56, loss_tr=0.173690 err_tr=0.050732 loss_te=2.812427 err_te=0.443322 err_te_snt=0.011544
epoch 64, loss_tr=0.145256 err_tr=0.043594 loss_te=2.917569 err_te=0.438507 err_te_snt=0.009380
epoch 72, loss_tr=0.128894 err_tr=0.038486 loss_te=3.009008 err_te=0.438005 err_te_snt=0.019481
....
epoch 320, loss_tr=0.033052 err_tr=0.009639 loss_te=4.076542 err_te=0.416710 err_te_snt=0.006494
epoch 328, loss_tr=0.033344 err_tr=0.010117 loss_te=3.928874 err_te=0.415024 err_te_snt=0.007215
epoch 336, loss_tr=0.033228 err_tr=0.010166 loss_te=4.030224 err_te=0.410034 err_te_snt=0.005051
epoch 344, loss_tr=0.033313 err_tr=0.010166 loss_te=4.402949 err_te=0.428691 err_te_snt=0.009380
epoch 352, loss_tr=0.031828 err_tr=0.009238 loss_te=4.080747 err_te=0.414066 err_te_snt=0.006494
epoch 360, loss_tr=0.033095 err_tr=0.009600 loss_te=4.254683 err_te=0.419954 err_te_snt=0.005772
Le converge est initialement très rapide (voir les 30 premières époques). Après cela, l'amélioration des performances diminue et les oscillations dans les performances du taux d'erreur de phrase apparaissent. Malgré ces oscillations, une tendance d'amélioration moyenne peut être observée pour les époques suivantes. Dans cette expérience, nous avons arrêté notre formation à Epoch 360. Les champs du fichier res.res ont le sens suivant:
Vous pouvez trouver notre modèle formé pour Timit ici.
Pour jeter un œil à l'implémentation SincNet, vous devez ouvrir le fichier dnn_models.py et lire les classes Sincnet , SINC_CONV et la fonction SINC .
Dans ce référentiel, nous avons utilisé l'ensemble de données TIMIT comme tutoriel pour montrer comment fonctionne Sincnet. Avec la version actuelle du code, vous pouvez facilement utiliser un corpus différent. Pour le faire, vous devez fournir dans la saisie des fichiers d'entrée spécifiques aux corpus (au format WAV) et vos propres étiquettes. Vous devez donc modifier les chemins dans les fichiers * .scp que vous trouvez dans le dossier DATA_LISTS.
Pour attribuer à chaque phrase la bonne étiquette, vous devez également modifier le dictionnaire " timit_labels.npy ". Les étiquettes sont spécifiées dans un dictionnaire Python qui contient des ID de phrase en tant que clés (par exemple, " Si1027 ") et Speaker_ID comme valeurs. Chaque Speaker_id est un entier, allant de 0 à N_SPKS-1. Dans l'ensemble de données TIMIT, vous pouvez facilement récupérer l'ID du haut-parleur à partir du chemin (par exemple, Train / DR1 / FCJF0 / SI1027.wav est la phrase_id " SI1027 " prononcée par le haut-parleur " fcjf0 "). Pour d'autres ensembles de données, vous devriez être en mesure de récupérer de cette manière ce dictionnaire contenant des paires de conférenciers et des identifiants de phrase.
Vous devez ensuite modifier le fichier de configuration ( CFG / SINCNET_TIMIT.CFG ) en fonction de vos nouveaux chemins. N'oubliez pas non plus de modifier le champ " class_lay = 462 " en fonction du nombre de locuteurs n_spks que vous avez dans votre ensemble de données.
La version de l'ensemble de données LibRisPeleeCH utilisé dans le document est disponible sur demande . Dans nos travaux, nous n'avons utilisé que 12 à 15 secondes de matériel de formation pour chaque haut-parleur et nous avons traité les phrases de bibliothèque originales afin d'effectuer une normalisation d'amplitude. De plus, nous avons utilisé un VAD simple basé sur l'énergie pour éviter les silences au début et à la fin de chaque phrase ainsi que pour diviser en plusieurs morceaux les phrases qui contiennent un silence plus long
[1] Mirco Ravanelli, Yoshua Bengio, «Reconnaissance des haut-parleurs de la forme d'onde brute avec Sincnet» Arxiv


