SincNet
1.0.0
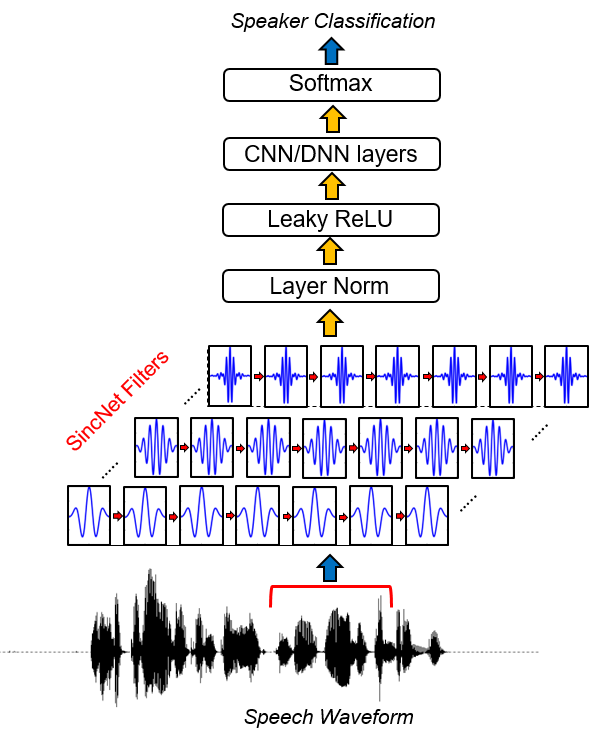
Sincnet은 원시 오디오 샘플을 처리하기위한 신경 아키텍처입니다. 첫 번째 컨볼 루션 층이보다 의미있는 필터를 발견하도록 장려하는 새로운 컨볼 루션 신경망 (CNN)입니다. Sincnet은 대역 통과 필터를 구현하는 매개 변수화 된 SINC 기능을 기반으로합니다.
표준 CNN과 달리, 각 필터의 모든 요소를 학습하는 경우, 제안 된 방법이있는 데이터에서 낮은 컷오프 주파수 만 직접 학습됩니다. 이는 원하는 응용 프로그램을 위해 특별히 조정 된 맞춤형 필터 뱅크를 도출하는 매우 작고 효율적인 방법을 제공합니다.
이 프로젝트는 SINCNET을 사용하여 스피커 식별을 수행하기위한 코드 및 유틸리티 모음을 출시합니다. Timit 데이터베이스와의 스피커 식별의 예가 제공됩니다. 음성 인식에 적용되는 Sincnet에 관심이 있다면 Pytorch-kaldi Github 저장소 (https://github.com/mravanelli/pytorch-kaldi)를 살펴볼 수 있습니다.
Sincnet에 대한 비디오 소개를 살펴보십시오
이 코드를 사용하거나 그 일부를 사용하면 우리를 인용하십시오!
Mirco Ravanelli, Yoshua Bengio,“Sincnet과의 원시 파형의 스피커 인식” Arxiv
conda install -c conda-forge pysoundfile )Sincnet은 SpeechBrain (https://speechbrain.github.io/) 프로젝트에서도 구현됩니다. 우리는 당신도 그것을 살펴 보는 것이 좋습니다! 현재 음성 인식, 스피커 인식, SLU, 음성 향상, 음성 분리, 다중 미크로폰 신호 처리를 지원하는 올인원 Pytorch 기반 음성 처리 툴킷입니다. 유연하고 사용하기 쉽고 모듈 식이며 잘 문서화되도록 설계되었습니다. 확인하십시오.
2019 년 2 월 16 일 :
코드는 모든 음성 데이터 세트에 쉽게 조정할 수 있지만 문서의 다음 부분에서는 인기있는 TIMIT 데이터 세트를 기반으로 한 예를 제공합니다.
1. 티미트 데이터 준비를 실행하십시오.
이 단계는 시작 및 끝 침묵이 제거되고 각 음성 발화의 진폭이 정규화되는 Timit 버전을 저장하는 데 필요합니다. 그렇게하려면 다음 코드를 실행하십시오.
python TIMIT_preparation.py $TIMIT_FOLDER $OUTPUT_FOLDER data_lists/TIMIT_all.scp
어디:
2. 스피커 ID 실험을 실행하십시오.
python speaker_id.py --cfg=cfg/SincNet_TIMIT.cfg
네트워크를 수렴하는 데 몇 시간이 걸릴 수 있습니다 (GPU 카드의 속도에 따라 다름). 우리의 경우 Nvidia Titan X를 사용하여 전체 훈련에는 약 24 시간이 걸렸습니다. 클러스터 내의 코드를 사용하는 경우 현재 버전의 코드는 저장된 WAV 파일에 자주 액세스해야하므로 정규화 된 데이터 세트를 로컬 노드에 복사하는 데 중요합니다. 이 버전에서는 코드 속도를 향상시키기위한 몇 가지 가능한 최적화가 구현되지 않으므로이 작업의 범위를 벗어났습니다.
3. 결과.
결과는 CFG 파일에 지정된 output_folder 에 저장됩니다. 이 폴더에서는 교육 및 테스트 오류율을 요약하는 파일 ( Res.Res )을 찾을 수 있습니다. Model Model_Raw.pkl 모델은 마지막 반복 후에 저장된 SincNet 모델입니다. 위에 지정된 CFG 파일을 사용하여 다음과 같은 결과를 얻습니다.
epoch 0, loss_tr=5.542032 err_tr=0.984189 loss_te=4.996982 err_te=0.969038 err_te_snt=0.919913
epoch 8, loss_tr=1.693487 err_tr=0.434424 loss_te=2.735717 err_te=0.612260 err_te_snt=0.069264
epoch 16, loss_tr=0.861834 err_tr=0.229424 loss_te=2.465258 err_te=0.520276 err_te_snt=0.038240
epoch 24, loss_tr=0.528619 err_tr=0.144375 loss_te=2.948707 err_te=0.534053 err_te_snt=0.062049
epoch 32, loss_tr=0.362914 err_tr=0.100518 loss_te=2.530276 err_te=0.469060 err_te_snt=0.015152
epoch 40, loss_tr=0.267921 err_tr=0.076445 loss_te=2.761606 err_te=0.464799 err_te_snt=0.023088
epoch 48, loss_tr=0.215479 err_tr=0.061406 loss_te=2.737486 err_te=0.453493 err_te_snt=0.010823
epoch 56, loss_tr=0.173690 err_tr=0.050732 loss_te=2.812427 err_te=0.443322 err_te_snt=0.011544
epoch 64, loss_tr=0.145256 err_tr=0.043594 loss_te=2.917569 err_te=0.438507 err_te_snt=0.009380
epoch 72, loss_tr=0.128894 err_tr=0.038486 loss_te=3.009008 err_te=0.438005 err_te_snt=0.019481
....
epoch 320, loss_tr=0.033052 err_tr=0.009639 loss_te=4.076542 err_te=0.416710 err_te_snt=0.006494
epoch 328, loss_tr=0.033344 err_tr=0.010117 loss_te=3.928874 err_te=0.415024 err_te_snt=0.007215
epoch 336, loss_tr=0.033228 err_tr=0.010166 loss_te=4.030224 err_te=0.410034 err_te_snt=0.005051
epoch 344, loss_tr=0.033313 err_tr=0.010166 loss_te=4.402949 err_te=0.428691 err_te_snt=0.009380
epoch 352, loss_tr=0.031828 err_tr=0.009238 loss_te=4.080747 err_te=0.414066 err_te_snt=0.006494
epoch 360, loss_tr=0.033095 err_tr=0.009600 loss_te=4.254683 err_te=0.419954 err_te_snt=0.005772
수렴은 처음에 매우 빠릅니다 (처음 30 개의 시대는 참조). 그 후 성능 개선이 감소하고 문장 오류율 성능으로의 진동이 나타납니다. 이러한 진동에도 불구하고 후속 시대에 대해 평균 개선 추세가 관찰 될 수 있습니다. 이 실험에서 우리는 Epoch 360에서의 훈련을 중단했습니다. Res.Res 파일의 필드에는 다음과 같은 의미가 있습니다.
Timit에 대한 숙련 된 모델을 여기에서 찾을 수 있습니다.
Sincnet 구현을 살펴 보려면 파일 DNN_Models.py 를 열고 SincNet , Sinc_conv 및 함수 Sinc 클래스를 읽어야합니다.
이 저장소에서는 Timit DataSet을 SINCNET의 작동 방식을 보여주는 자습서로 사용했습니다. 코드의 현재 버전을 사용하면 다른 코퍼스를 쉽게 사용할 수 있습니다. 그렇게하려면 Corpora 별 입력 파일 (WAV 형식) 및 자체 레이블을 입력해야합니다. 따라서 Data_Lists 폴더에서 찾은 *.SCP 파일로 경로를 수정해야합니다.
각 문장에 올바른 레이블을 할당하려면 사전 " timit_labels.npy "를 수정해야합니다. 레이블은 키 (예 : " Si1027 ") 및 speeper_ids로 값으로 문장 ID를 포함하는 Python 사전 내에 지정됩니다. 각 speeper_id는 0에서 n_spks-1까지의 정수입니다. TIMIT 데이터 세트에서는 경로에서 스피커 ID를 쉽게 검색 할 수 있습니다 (예 : Train/DR1/FCJF0/SI1027.WAV 는 스피커 " FCJF0 "에 의해 발화 된 Sentence_ID " SI1027 "). 다른 데이터 세트의 경우 스피커 및 문장 ID 쌍이 포함 된이 사전에 검색 할 수 있어야합니다.
그런 다음 새 경로에 따라 구성 파일 ( cfg/sincnet_timit.cfg )을 수정해야합니다. 또한 데이터 세트에있는 스피커 N_SPK의 수에 따라 " class_lay = 462 "필드를 변경하십시오.
논문에 사용 된 LibrisPeech 데이터 세트의 버전은 요청시 제공됩니다 . 우리의 작업에서, 우리는 각 스피커에 대해 12-15 초의 훈련 자료를 사용했으며 진폭 정규화를 수행하기 위해 원래 Librispeech 문장을 처리했습니다. 더욱
[1] Mirco Ravanelli, Yoshua Bengio,“Sincnet과의 원시 파형의 스피커 인식”Arxiv


