SincNet
1.0.0
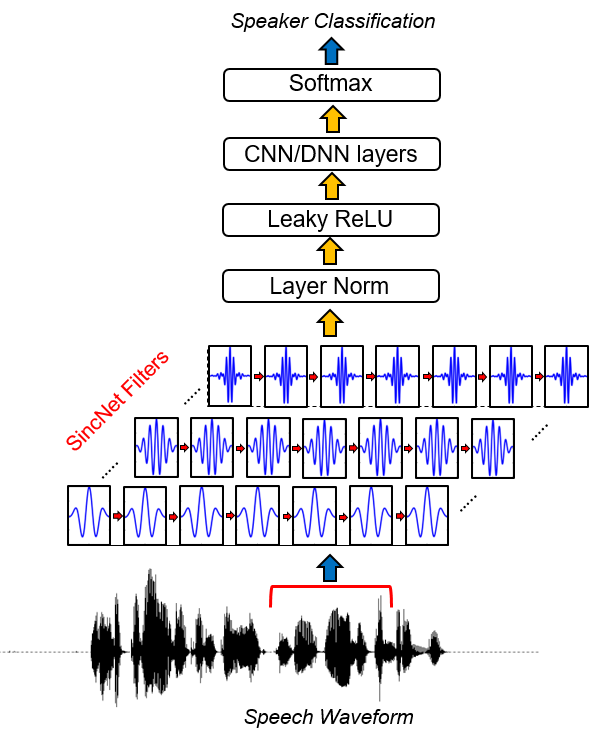
Sincnet เป็นสถาปัตยกรรมประสาทสำหรับการประมวลผล ตัวอย่างเสียงดิบ มันเป็นเครือข่ายนิวรัลนัลนวนิยาย (CNN) ที่กระตุ้นให้เลเยอร์ convolutional แรกค้นพบ ตัวกรองที่มีความหมาย มากขึ้น Sincnet ขึ้นอยู่กับฟังก์ชั่น SINC parametrized ซึ่งใช้ตัวกรอง Band-Pass
ตรงกันข้ามกับ CNN มาตรฐานที่เรียนรู้องค์ประกอบทั้งหมดของตัวกรองแต่ละตัวความถี่ที่มีการตัดต่ำและสูงเท่านั้นที่เรียนรู้โดยตรงจากข้อมูลด้วยวิธีการที่เสนอ นี่เป็นวิธีที่มีขนาดกะทัดรัดและมีประสิทธิภาพมากในการรับ ธนาคารตัวกรองที่ปรับแต่งเอง โดยเฉพาะสำหรับแอปพลิเคชันที่ต้องการ
โครงการนี้เปิดตัวคอลเลกชันของรหัสและยูทิลิตี้เพื่อดำเนินการระบุลำโพงด้วย Sincnet ตัวอย่างของการระบุลำโพงที่มีฐานข้อมูล Timit มีให้ หากคุณมีความสนใจใน Sincnet ที่ใช้กับการจดจำคำพูดคุณสามารถตรวจสอบที่เก็บ pytorch-kaldi github (https://github.com/mravanelli/Pytorch-kaldi)
ลองดูวิดีโอแนะนำของเราเกี่ยวกับ Sincnet
หากคุณใช้รหัสนี้หรือบางส่วนโปรดอ้างอิงเรา!
Mirco Ravanelli, Yoshua Bengio,“ การรับรู้ลำโพงจากรูปคลื่นดิบกับ Sincnet” arxiv
conda install -c conda-forge pysoundfile )Sincnet ถูกนำไปใช้ในโครงการ Speechbrain (https://speechbrain.github.io/) เช่นกัน เราขอแนะนำให้คุณดูมันเช่นกัน! มันเป็นชุดเครื่องมือการประมวลผลคำพูดที่ใช้ pytorch แบบ all-in-one ที่สนับสนุนการรู้จำเสียงพูดการจดจำลำโพง, SLU, การเพิ่มประสิทธิภาพการพูด, การแยกคำพูด, การประมวลผลสัญญาณหลายไมโครโฟน มันถูกออกแบบมาให้มีความยืดหยุ่นง่ายต่อการใช้งานโมดูลาร์และบันทึกไว้อย่างดี ตรวจสอบ
ก.พ. , 16 2019:
แม้ว่ารหัสสามารถปรับให้เข้ากับชุดข้อมูลคำพูดใด ๆ ได้อย่างง่ายดายในส่วนต่อไปนี้ของเอกสารต่อไปนี้เราให้ตัวอย่างตามชุดข้อมูล Timit ยอดนิยม
1. เรียกใช้การเตรียมข้อมูลเวลา
ขั้นตอนนี้มีความจำเป็นในการจัดเก็บรุ่นของเวลาซึ่งการเริ่มต้นและความเงียบเริ่มต้นจะถูกลบออกและแอมพลิจูดของคำพูดแต่ละคำพูดจะถูกทำให้เป็นมาตรฐาน ในการทำมันเรียกใช้รหัสต่อไปนี้:
python TIMIT_preparation.py $TIMIT_FOLDER $OUTPUT_FOLDER data_lists/TIMIT_all.scp
ที่ไหน:
2. เรียกใช้การทดสอบ ID ลำโพง
python speaker_id.py --cfg=cfg/SincNet_TIMIT.cfg
เครือข่ายอาจใช้เวลาหลายชั่วโมงในการมาบรรจบกัน (ขึ้นอยู่กับความเร็วของการ์ด GPU ของคุณ) ในกรณีของเราการใช้ Nvidia Titan X การฝึกอบรมเต็มรูปแบบใช้เวลาประมาณ 24 ชั่วโมง หากคุณใช้รหัสภายในคลัสเตอร์เป็นสิ่งสำคัญในการคัดลอกชุดข้อมูลปกติลงในโหนดโลคัลเนื่องจากรหัสเวอร์ชันปัจจุบันต้องใช้การเข้าถึงบ่อยครั้งไปยังไฟล์ WAV ที่เก็บไว้ โปรดทราบว่าการเพิ่มประสิทธิภาพที่เป็นไปได้หลายประการเพื่อปรับปรุงความเร็วรหัสจะไม่ถูกนำมาใช้ในรุ่นนี้เนื่องจากอยู่นอกขอบเขตของงานนี้
3. ผลลัพธ์
ผลลัพธ์จะถูกบันทึกลงใน output_folder ที่ระบุในไฟล์ CFG ในโฟลเดอร์นี้คุณสามารถค้นหาไฟล์ ( res.res ) สรุปการฝึกอบรมและอัตราข้อผิดพลาดการทดสอบ model model_raw.pkl เป็นรุ่น Sincnet ที่บันทึกไว้หลังจากการวนซ้ำครั้งล่าสุด การใช้ไฟล์ CFG ที่ระบุไว้ข้างต้นเราได้ผลลัพธ์ต่อไปนี้:
epoch 0, loss_tr=5.542032 err_tr=0.984189 loss_te=4.996982 err_te=0.969038 err_te_snt=0.919913
epoch 8, loss_tr=1.693487 err_tr=0.434424 loss_te=2.735717 err_te=0.612260 err_te_snt=0.069264
epoch 16, loss_tr=0.861834 err_tr=0.229424 loss_te=2.465258 err_te=0.520276 err_te_snt=0.038240
epoch 24, loss_tr=0.528619 err_tr=0.144375 loss_te=2.948707 err_te=0.534053 err_te_snt=0.062049
epoch 32, loss_tr=0.362914 err_tr=0.100518 loss_te=2.530276 err_te=0.469060 err_te_snt=0.015152
epoch 40, loss_tr=0.267921 err_tr=0.076445 loss_te=2.761606 err_te=0.464799 err_te_snt=0.023088
epoch 48, loss_tr=0.215479 err_tr=0.061406 loss_te=2.737486 err_te=0.453493 err_te_snt=0.010823
epoch 56, loss_tr=0.173690 err_tr=0.050732 loss_te=2.812427 err_te=0.443322 err_te_snt=0.011544
epoch 64, loss_tr=0.145256 err_tr=0.043594 loss_te=2.917569 err_te=0.438507 err_te_snt=0.009380
epoch 72, loss_tr=0.128894 err_tr=0.038486 loss_te=3.009008 err_te=0.438005 err_te_snt=0.019481
....
epoch 320, loss_tr=0.033052 err_tr=0.009639 loss_te=4.076542 err_te=0.416710 err_te_snt=0.006494
epoch 328, loss_tr=0.033344 err_tr=0.010117 loss_te=3.928874 err_te=0.415024 err_te_snt=0.007215
epoch 336, loss_tr=0.033228 err_tr=0.010166 loss_te=4.030224 err_te=0.410034 err_te_snt=0.005051
epoch 344, loss_tr=0.033313 err_tr=0.010166 loss_te=4.402949 err_te=0.428691 err_te_snt=0.009380
epoch 352, loss_tr=0.031828 err_tr=0.009238 loss_te=4.080747 err_te=0.414066 err_te_snt=0.006494
epoch 360, loss_tr=0.033095 err_tr=0.009600 loss_te=4.254683 err_te=0.419954 err_te_snt=0.005772
การบรรจบกันเริ่มแรกเร็วมาก (ดูยุค 30 ครั้งแรก) หลังจากนั้นการปรับปรุงประสิทธิภาพจะลดลงและการแกว่งลงในประสิทธิภาพของอัตราความผิดพลาดของประโยคจะปรากฏขึ้น แม้จะมีการแกว่งเหล่านี้ แต่ก็สามารถสังเกตแนวโน้มการปรับปรุงโดยเฉลี่ยสำหรับยุคที่ตามมา ในการทดลองนี้เราหยุดการฝึกอบรมของเราที่ Epoch 360 ฟิลด์ของไฟล์ res.res มีความหมายดังต่อไปนี้:
คุณสามารถค้นหาแบบจำลองที่ผ่านการฝึกอบรมของเราสำหรับเวลาที่นี่
หากต้องการดูการใช้งาน SINCNET คุณควรเปิดไฟล์ dnn_models.py และอ่านคลาส Sincnet , sinc_conv และฟังก์ชั่น sinc
ในที่เก็บนี้เราใช้ชุดข้อมูล Timit เป็นบทช่วยสอนเพื่อแสดงว่า Sincnet ทำงานอย่างไร ด้วยรหัสเวอร์ชันปัจจุบันคุณสามารถใช้คลังข้อมูลอื่นได้อย่างง่ายดาย ในการทำเช่นนั้นคุณควรให้ข้อมูลอินพุตเฉพาะ บริษัท (ในรูปแบบ WAV) และฉลากของคุณเอง คุณควรแก้ไขพา ธ ไปยังไฟล์ *.SCP ที่คุณพบในโฟลเดอร์ DATA_LISSS
ในการกำหนดป้ายกำกับที่ถูกต้องให้กับแต่ละประโยคคุณต้องแก้ไขพจนานุกรม " timit_labels.npy " ฉลากถูกระบุภายในพจนานุกรม Python ที่มีรหัสประโยคเป็นปุ่ม (เช่น " SI1027 ") และ Speaker_IDS เป็นค่า ลำโพงแต่ละตัวเป็นจำนวนเต็มตั้งแต่ 0 ถึง N_SPKS-1 ในชุดข้อมูล Timit คุณสามารถดึงรหัสลำโพงจากเส้นทาง (เช่น Train/DR1/FCJF0/SI1027.WAV เป็น SENTENCE_ID " SI1027 " พูดโดยลำโพง " FCJF0 ") สำหรับชุดข้อมูลอื่น ๆ คุณควรจะสามารถเรียกคืนได้ในลักษณะที่พจนานุกรมนี้มีลำโพงและรหัสประโยคคู่นี้
คุณควรแก้ไขไฟล์ config ( cfg/sincnet_timit.cfg ) ตามเส้นทางใหม่ของคุณ โปรดจำไว้ว่าเพื่อเปลี่ยนฟิลด์ " class_lay = 462 " ตามจำนวนลำโพง n_spks ที่คุณมีในชุดข้อมูลของคุณ
ชุดข้อมูล librispeech ที่ใช้ในกระดาษมีให้เมื่อมีการร้องขอ ในงานของเราเราใช้สื่อการฝึกอบรมเพียง 12-15 วินาทีสำหรับผู้พูดแต่ละคนและเราประมวลผลประโยค Librispeech ดั้งเดิมเพื่อทำการทำให้เป็นมาตรฐานแอมพลิจูด ยิ่งกว่านั้นเราใช้ VAD ที่ใช้พลังงานอย่างง่ายเพื่อหลีกเลี่ยงความเงียบในตอนต้นและจุดสิ้นสุดของแต่ละประโยครวมถึงการแยกประโยคหลายชิ้นที่มีความเงียบอีกต่อไป
[1] Mirco Ravanelli, Yoshua Bengio,“ การจดจำลำโพงจากรูปคลื่นดิบกับ Sincnet” arxiv


