SincNet
1.0.0
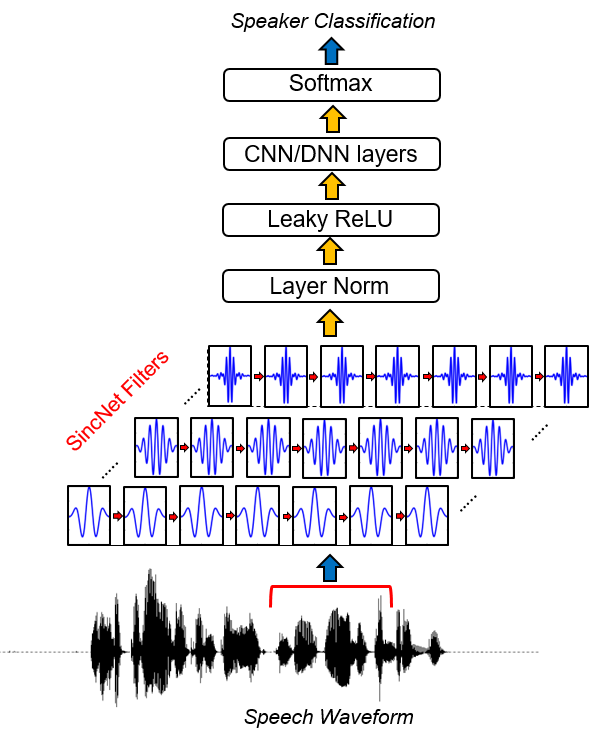
Sincnet adalah arsitektur saraf untuk memproses sampel audio mentah . Ini adalah Novel Convolutional Neural Network (CNN) yang mendorong lapisan konvolusional pertama untuk menemukan filter yang lebih bermakna . SINCNET didasarkan pada fungsi SINC parametrized, yang menerapkan filter band-pass.
Berbeda dengan CNN standar, yang mempelajari semua elemen dari setiap filter, hanya frekuensi cutoff rendah dan tinggi yang secara langsung dipelajari dari data dengan metode yang diusulkan. Ini menawarkan cara yang sangat kompak dan efisien untuk memperoleh bank filter yang disesuaikan secara khusus disetel untuk aplikasi yang diinginkan.
Proyek ini merilis kumpulan kode dan utilitas untuk melakukan identifikasi pembicara dengan Sincnet. Contoh identifikasi pembicara dengan database Timit disediakan. Jika Anda tertarik pada Sincnet yang diterapkan pada pengakuan ucapan, Anda dapat melihat ke dalam repositori Pytorch-kaldi Github (https://github.com/mravanelli/pytorch-kaldi).
Perhatikan Video kami Pengantar Sincnet
Jika Anda menggunakan kode ini atau bagiannya, silakan kutip kami!
Mirco Ravanelli, Yoshua Bengio, “Pengakuan Pembicara dari Bentuk Gelombang Raw dengan Sincnet” Arxiv
conda install -c conda-forge pysoundfile )Sincnet diimplementasikan dalam proyek Pidato (https://speechbrain.github.io/) juga. Kami mendorong Anda untuk melihatnya juga! Ini adalah toolkit pemrosesan bicara berbasis Pytorch all-in-one yang saat ini mendukung pengenalan suara, pengenalan pembicara, SLU, peningkatan bicara, pemisahan bicara, pemrosesan sinyal multi-mikrofon. Ini dirancang untuk menjadi fleksibel, mudah digunakan, modular, dan terdokumentasi dengan baik. Lihatlah.
Feb, 16 2019:
Meskipun kode dapat dengan mudah diadaptasi dengan dataset ucapan apa pun, di bagian dokumentasi berikut, kami memberikan contoh berdasarkan dataset Timit yang populer.
1. Jalankan persiapan data Timit.
Langkah ini diperlukan untuk menyimpan versi Timit di mana keheningan awal dan akhir dihapus dan amplitudo setiap ucapan ucapan dinormalisasi. Untuk melakukannya, jalankan kode berikut:
python TIMIT_preparation.py $TIMIT_FOLDER $OUTPUT_FOLDER data_lists/TIMIT_all.scp
Di mana:
2. Jalankan Eksperimen ID Pembicara.
python speaker_id.py --cfg=cfg/SincNet_TIMIT.cfg
Jaringan mungkin membutuhkan waktu beberapa jam untuk bertemu (tergantung pada kecepatan kartu GPU Anda). Dalam kasus kami, menggunakan NVIDIA Titan X , pelatihan penuh memakan waktu sekitar 24 jam. Jika Anda menggunakan kode dalam cluster sangat penting untuk menyalin dataset yang dinormalisasi ke dalam node lokal, karena versi kode saat ini membutuhkan akses yang sering ke file WAV yang disimpan. Perhatikan bahwa beberapa optimasi yang mungkin untuk meningkatkan kecepatan kode tidak diimplementasikan dalam versi ini karena berada di luar ruang lingkup pekerjaan ini.
3. Hasil.
Hasilnya disimpan ke output_folder yang ditentukan dalam file CFG. Di folder ini, Anda dapat menemukan file ( res.res ) meringkas pelatihan dan tingkat kesalahan pengujian. Model model_raw.pkl adalah model Sincnet yang disimpan setelah iterasi terakhir. Menggunakan file CFG yang ditentukan di atas, kami mendapatkan hasil berikut:
epoch 0, loss_tr=5.542032 err_tr=0.984189 loss_te=4.996982 err_te=0.969038 err_te_snt=0.919913
epoch 8, loss_tr=1.693487 err_tr=0.434424 loss_te=2.735717 err_te=0.612260 err_te_snt=0.069264
epoch 16, loss_tr=0.861834 err_tr=0.229424 loss_te=2.465258 err_te=0.520276 err_te_snt=0.038240
epoch 24, loss_tr=0.528619 err_tr=0.144375 loss_te=2.948707 err_te=0.534053 err_te_snt=0.062049
epoch 32, loss_tr=0.362914 err_tr=0.100518 loss_te=2.530276 err_te=0.469060 err_te_snt=0.015152
epoch 40, loss_tr=0.267921 err_tr=0.076445 loss_te=2.761606 err_te=0.464799 err_te_snt=0.023088
epoch 48, loss_tr=0.215479 err_tr=0.061406 loss_te=2.737486 err_te=0.453493 err_te_snt=0.010823
epoch 56, loss_tr=0.173690 err_tr=0.050732 loss_te=2.812427 err_te=0.443322 err_te_snt=0.011544
epoch 64, loss_tr=0.145256 err_tr=0.043594 loss_te=2.917569 err_te=0.438507 err_te_snt=0.009380
epoch 72, loss_tr=0.128894 err_tr=0.038486 loss_te=3.009008 err_te=0.438005 err_te_snt=0.019481
....
epoch 320, loss_tr=0.033052 err_tr=0.009639 loss_te=4.076542 err_te=0.416710 err_te_snt=0.006494
epoch 328, loss_tr=0.033344 err_tr=0.010117 loss_te=3.928874 err_te=0.415024 err_te_snt=0.007215
epoch 336, loss_tr=0.033228 err_tr=0.010166 loss_te=4.030224 err_te=0.410034 err_te_snt=0.005051
epoch 344, loss_tr=0.033313 err_tr=0.010166 loss_te=4.402949 err_te=0.428691 err_te_snt=0.009380
epoch 352, loss_tr=0.031828 err_tr=0.009238 loss_te=4.080747 err_te=0.414066 err_te_snt=0.006494
epoch 360, loss_tr=0.033095 err_tr=0.009600 loss_te=4.254683 err_te=0.419954 err_te_snt=0.005772
Converge awalnya sangat cepat (lihat 30 zaman pertama). Setelah itu peningkatan kinerja berkurang dan osilasi ke dalam kinerja tingkat kesalahan kalimat muncul. Terlepas dari osilasi ini, tren perbaikan rata -rata dapat diamati untuk zaman berikutnya. Dalam percobaan ini, kami menghentikan pelatihan kami di Epoch 360. Bidang file res.res memiliki arti berikut:
Anda dapat menemukan model terlatih kami untuk Timit di sini.
Untuk melihat implementasi Sincnet, Anda harus membuka file dnn_models.py dan membaca kelas Sincnet , Sinc_conv dan fungsi SINC .
Dalam repositori ini, kami menggunakan dataset Timit sebagai tutorial untuk menunjukkan cara kerja Sincnet. Dengan versi kode saat ini, Anda dapat dengan mudah menggunakan korpus yang berbeda. Untuk melakukannya, Anda harus memberikan input file input khusus korpora (dalam format WAV) dan label Anda sendiri. Dengan demikian Anda harus memodifikasi jalur ke dalam file *.scp yang Anda temukan di folder data_lists.
Untuk menetapkan untuk setiap kalimat label yang tepat, Anda juga harus memodifikasi kamus " timit_labels.npy ". Label ditentukan dalam kamus Python yang berisi ID kalimat sebagai kunci (misalnya, " si1027 ") dan speaker_ids sebagai nilai. Setiap speaker_id adalah bilangan bulat, mulai dari 0 hingga n_spks-1. Dalam dataset Timit, Anda dapat dengan mudah mengambil ID speaker dari jalur (misalnya, Train/DR1/FCJF0/SI1027.WAV adalah kalimat_id " si1027 " yang diucapkan oleh speaker " fcjf0 "). Untuk kumpulan data lainnya, Anda harus dapat mengambil dengan cara yang sama dengan kamus ini yang berisi pasangan pembicara dan ID kalimat.
Anda kemudian harus memodifikasi file konfigurasi ( cfg/sincnet_timit.cfg ) sesuai dengan jalur baru Anda. Ingat juga untuk mengubah bidang " class_lay = 462 " sesuai dengan jumlah speaker N_SPKS yang Anda miliki dalam dataset Anda.
Versi dataset Librispeech yang digunakan dalam kertas tersedia berdasarkan permintaan . Dalam pekerjaan kami, kami hanya menggunakan 12-15 detik materi pelatihan untuk setiap pembicara dan kami memproses kalimat librispeech asli untuk melakukan normalisasi amplitudo. Selain itu, kami menggunakan VAD berbasis energi sederhana untuk menghindari keheningan di awal dan akhir setiap kalimat serta untuk membagi dalam beberapa potongan kalimat yang mengandung keheningan yang lebih lama
[1] Mirco Ravanelli, Yoshua Bengio, “Pengakuan Pembicara dari Bentuk Gelombang Raw dengan Sincnet” Arxiv


