SincNet
1.0.0
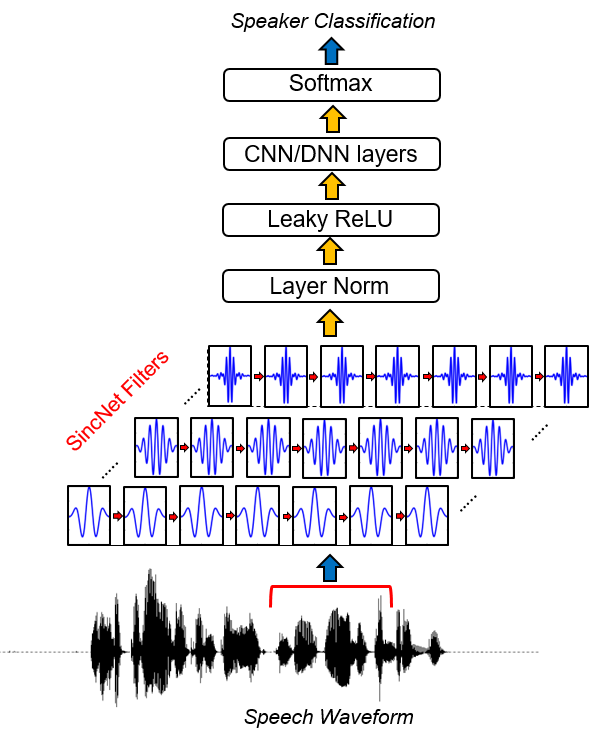
SINCNET هي بنية عصبية لمعالجة عينات الصوت الخام . إنها شبكة عصبية تلافيفية جديدة (CNN) تشجع الطبقة التلافيفية الأولى لاكتشاف مرشحات أكثر جدوى . يعتمد SINCNET على وظائف SINC المعتمدة ، والتي تنفذ مرشحات تمرير النطاق.
على عكس CNNs القياسية ، والتي تتعلم جميع عناصر كل مرشح ، يتم تعلم ترددات قطع منخفضة وعالية فقط مباشرة من البيانات ذات الطريقة المقترحة. يوفر هذا طريقة مدمجة وفعالة للغاية لاشتقاق بنك مرشح مخصص تم ضبطه خصيصًا للتطبيق المطلوب.
يطلق هذا المشروع مجموعة من الرموز والمرافق لأداء هوية المتحدث مع SINCNET. يتم توفير مثال على تحديد هوية السماعة مع قاعدة بيانات TIMIT. إذا كنت مهتمًا بتطبيق sincnet على التعرف على الكلام ، فيمكنك إلقاء نظرة على مستودع Pytorch-Kaldi Github (https://github.com/mravanelli/Pytorch-kaldi).
ألق نظرة على مقدمة الفيديو الخاصة بنا إلى Sincnet
إذا كنت تستخدم هذا الرمز أو جزء منه ، يرجى الاستشهاد بنا!
Mirco Ravanelli ، Yoshua Bengio ، "التعرف على المتحدث من الموجة الخام مع sincnet" Arxiv
conda install -c conda-forge pysoundfile )يتم تنفيذ SINCNET في مشروع Fkebrain (https://speechbrain.github.io/) أيضًا. نشجعك على إلقاء نظرة على ذلك أيضًا! إنها مجموعة أدوات معالجة الكلام القائمة على Pytorch التي تدعم حاليًا التعرف على الكلام ، والتعرف على المتحدثين ، والعلاج SLU ، وتعزيز الكلام ، وفصل الكلام ، ومعالجة الإشارات متعددة الميكروفون. إنه مصمم ليكون مرنًا وسهل الاستخدام ومعيار وموثق جيدًا. تحقق من ذلك.
فبراير ، 16 2019:
على الرغم من أنه يمكن تكييف الرمز بسهولة مع أي مجموعة بيانات للكلام ، في الجزء التالي من الوثائق ، نقدم مثالاً بناءً على مجموعة بيانات الوقت الشائعة.
1. تشغيل إعداد بيانات الوقت.
هذه الخطوة ضرورية لتخزين نسخة من الوقت الذي تتم فيه إزالة الصمت والنهاية وتطبيع سعة كل نطق خطاب. للقيام بذلك ، قم بتشغيل الكود التالي:
python TIMIT_preparation.py $TIMIT_FOLDER $OUTPUT_FOLDER data_lists/TIMIT_all.scp
أين:
2. قم بتشغيل تجربة معرف السماعة.
python speaker_id.py --cfg=cfg/SincNet_TIMIT.cfg
قد تستغرق الشبكة عدة ساعات لتلتقي (اعتمادًا على سرعة بطاقة GPU الخاصة بك). في حالتنا ، باستخدام Nvidia Titan X ، استغرق التدريب الكامل حوالي 24 ساعة. إذا كنت تستخدم الرمز داخل المجموعة أمرًا ضروريًا لنسخ مجموعة البيانات الطبيعية في العقدة المحلية ، لأن الإصدار الحالي من الرمز يتطلب وصولًا متكررًا إلى ملفات WAV المخزنة. لاحظ أن العديد من التحسينات المحتملة لتحسين سرعة الكود لا يتم تنفيذها في هذا الإصدار لأنها خارج نطاق هذا العمل.
3. النتائج.
يتم حفظ النتائج في output_folder المحددة في ملف CFG. في هذا المجلد ، يمكنك العثور على ملف ( res.res ) يلخص معدلات الخطأ واختبار الاختبار. نموذج model_raw.pkl هو نموذج sincnet المحفوظ بعد التكرار الأخير. باستخدام ملف CFG المحدد أعلاه ، نحصل على النتائج التالية:
epoch 0, loss_tr=5.542032 err_tr=0.984189 loss_te=4.996982 err_te=0.969038 err_te_snt=0.919913
epoch 8, loss_tr=1.693487 err_tr=0.434424 loss_te=2.735717 err_te=0.612260 err_te_snt=0.069264
epoch 16, loss_tr=0.861834 err_tr=0.229424 loss_te=2.465258 err_te=0.520276 err_te_snt=0.038240
epoch 24, loss_tr=0.528619 err_tr=0.144375 loss_te=2.948707 err_te=0.534053 err_te_snt=0.062049
epoch 32, loss_tr=0.362914 err_tr=0.100518 loss_te=2.530276 err_te=0.469060 err_te_snt=0.015152
epoch 40, loss_tr=0.267921 err_tr=0.076445 loss_te=2.761606 err_te=0.464799 err_te_snt=0.023088
epoch 48, loss_tr=0.215479 err_tr=0.061406 loss_te=2.737486 err_te=0.453493 err_te_snt=0.010823
epoch 56, loss_tr=0.173690 err_tr=0.050732 loss_te=2.812427 err_te=0.443322 err_te_snt=0.011544
epoch 64, loss_tr=0.145256 err_tr=0.043594 loss_te=2.917569 err_te=0.438507 err_te_snt=0.009380
epoch 72, loss_tr=0.128894 err_tr=0.038486 loss_te=3.009008 err_te=0.438005 err_te_snt=0.019481
....
epoch 320, loss_tr=0.033052 err_tr=0.009639 loss_te=4.076542 err_te=0.416710 err_te_snt=0.006494
epoch 328, loss_tr=0.033344 err_tr=0.010117 loss_te=3.928874 err_te=0.415024 err_te_snt=0.007215
epoch 336, loss_tr=0.033228 err_tr=0.010166 loss_te=4.030224 err_te=0.410034 err_te_snt=0.005051
epoch 344, loss_tr=0.033313 err_tr=0.010166 loss_te=4.402949 err_te=0.428691 err_te_snt=0.009380
epoch 352, loss_tr=0.031828 err_tr=0.009238 loss_te=4.080747 err_te=0.414066 err_te_snt=0.006494
epoch 360, loss_tr=0.033095 err_tr=0.009600 loss_te=4.254683 err_te=0.419954 err_te_snt=0.005772
يتقارب في البداية سريعًا جدًا (انظر أول 30 حقبة). بعد ذلك ، انخفض تحسين الأداء وظهر الأداء في أداء معدل خطأ الجملة. على الرغم من هذه التذبذبات ، يمكن ملاحظة اتجاه التحسين المتوسط للأعمل اللاحقة. في هذه التجربة ، توقفنا عن تدريبنا في Epoch 360. إن حقول ملف Res.Res لها المعنى التالي:
يمكنك العثور على نموذجنا المدرب لتوقيت هنا.
لإلقاء نظرة على تطبيق sincnet ، يجب عليك فتح الملف dnn_models.py وقراءة الفئات sincnet و sinc_conv و function sinc .
في هذا المستودع ، استخدمنا مجموعة بيانات TIMIT كبرنامج تعليمي لإظهار كيفية عمل SINCNET. مع الإصدار الحالي من الكود ، يمكنك بسهولة استخدام مجموعة مختلفة. للقيام بذلك ، يجب عليك تقديم ملفات الإدخال الخاصة بـ Corpora (بتنسيق WAV) وملصقاتك الخاصة. يجب عليك تعديل المسارات في ملفات *.SCP التي تجدها في مجلد Data_lists.
لتعيين كل جملة الملصق الأيمن ، عليك أيضًا تعديل القاموس " timit_labels.npy ". يتم تحديد الملصقات داخل قاموس بيثون الذي يحتوي على معرفات الجملة كمفاتيح (على سبيل المثال ، " SI1027 ") و SPEKER_IDs كقيم. كل مكبر الصوت هو عدد صحيح ، يتراوح من 0 إلى N_Spks-1. في مجموعة بيانات TIMIT ، يمكنك بسهولة استرداد معرف السماعة من المسار (على سبيل المثال ، Train/DR1/FCJF0/SI1027.WAV هو Sentence_id " SI1027 " ينطق به المتحدث " FCJF0 "). بالنسبة لمجموعات البيانات الأخرى ، يجب أن تكون قادرًا على الاسترداد بهذه الطريقة التي تحتوي على أزواج من مكبرات الصوت ومعرفات الجملة.
يجب عليك بعد ذلك تعديل ملف التكوين ( CFG/SINCNET_TIMIT.CFG ) وفقًا لمساراتك الجديدة. تذكر أيضًا تغيير الحقل " class_lay = 462 " وفقًا لعدد مكبرات الصوت n_spks لديك في مجموعة البيانات الخاصة بك.
يتوفر إصدار مجموعة بيانات Librispeech المستخدمة في الورقة عند الطلب . في عملنا ، استخدمنا فقط 12-15 ثانية من مواد التدريب لكل متحدث وقمنا بمعالجة جمل Librispeech الأصلية من أجل إجراء تطبيع السعة. علاوة على ذلك ، استخدمنا VAD بسيط قائم على الطاقة لتجنب الصمت في بداية ونهاية كل جملة وكذلك لتقسيم الجمل التي تحتوي على صمت أطول
[1] Mirco Ravanelli ، Yoshua Bengio ، "التعرف على المتحدث من الموجة الخام مع sincnet" Arxiv


