SincNet
1.0.0
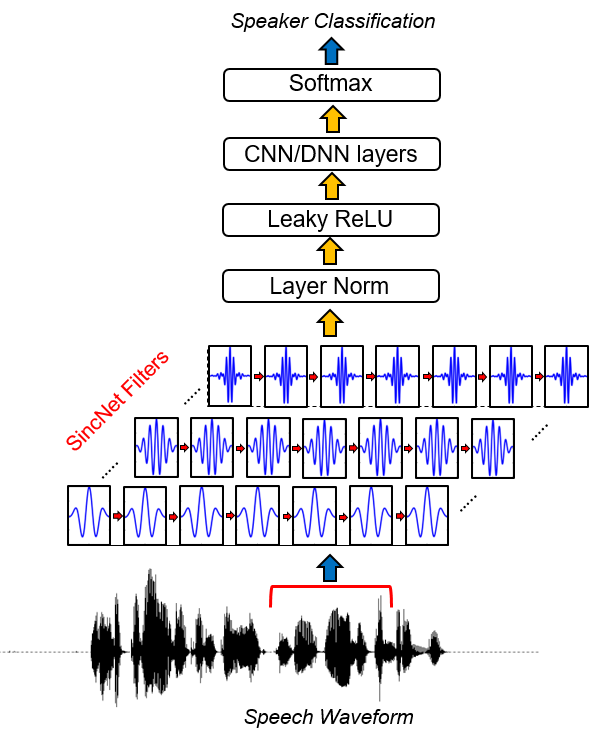
Sincnet es una arquitectura neuronal para procesar muestras de audio en bruto . Es una nueva red neuronal convolucional (CNN) que alienta la primera capa convolucional a descubrir filtros más significativos . Sincnet se basa en funciones de SINC parametrizadas, que implementan filtros de paso de banda.
A diferencia de los CNN estándar, que aprenden todos los elementos de cada filtro, solo las frecuencias de corte bajas y altas se aprenden directamente de los datos con el método propuesto. Esto ofrece una forma muy compacta y eficiente de derivar un banco de filtro personalizado específicamente ajustado para la aplicación deseada.
Este proyecto libera una colección de códigos y utilidades para realizar la identificación del altavoz con Sincnet. Se proporciona un ejemplo de identificación del altavoz con la base de datos TIMIT. Si está interesado en Sincnet aplicado al reconocimiento de voz, puede echar un vistazo al repositorio de Pytorch-Kaldi Github (https://github.com/mravanelli/pytorch-kaldi).
Eche un vistazo a nuestra introducción de video a Sincnet
Si usa este código o parte de él, ¡cíquanos!
Mirco Ravanelli, Yoshua Bengio, "Reconocimiento de altavoces de la forma de onda bruta con Sincnet" Arxiv
conda install -c conda-forge pysoundfile )Sincnet se implementa en el proyecto Speechbrain (https://spaechbrain.github.io/). ¡Te recomendamos que lo eches un vistazo también! Es un conjunto de herramientas de procesamiento de voz basado en Pytorch todo en uno que actualmente admite el reconocimiento de voz, el reconocimiento de los oradores, la SLU, la mejora del habla, la separación del habla, el procesamiento de señales multimicrófonos. Está diseñado para ser flexible, fácil de usar, modular y bien documentado. Échale un vistazo.
Feb, 16 de 2019:
Aunque el código se puede adaptar fácilmente a cualquier conjunto de datos de habla, en la siguiente parte de la documentación proporcionamos un ejemplo basado en el popular conjunto de datos Timit.
1. Ejecute la preparación de datos Timit.
Este paso es necesario para almacenar una versión de Timit en la que se eliminan los silencios de inicio y extremo y la amplitud de cada expresión del habla se normaliza. Para hacerlo, ejecute el siguiente código:
python TIMIT_preparation.py $TIMIT_FOLDER $OUTPUT_FOLDER data_lists/TIMIT_all.scp
dónde:
2. Ejecute el experimento de identificación del altavoz.
python speaker_id.py --cfg=cfg/SincNet_TIMIT.cfg
La red puede tardar varias horas en converger (dependiendo de la velocidad de su tarjeta GPU). En nuestro caso, utilizando un Nvidia Titan X , el entrenamiento completo tomó aproximadamente 24 horas. Si usa el código dentro de un clúster, es crucial para copiar el conjunto de datos normalizado en el nodo local, ya que la versión actual del código requiere accesos frecuentes a los archivos WAV almacenados. Tenga en cuenta que varias optimizaciones posibles para mejorar la velocidad del código no se implementan en esta versión, ya que están fuera del alcance de este trabajo.
3. Resultados.
Los resultados se guardan en la salida_folder especificada en el archivo CFG. En esta carpeta, puede encontrar un archivo ( res.res ) que resume las tasas de error de capacitación y prueba. El modelo modelo_raw.pkl es el modelo Sincnet guardado después de la última iteración. Usando el archivo CFG especificado anteriormente, obtenemos los siguientes resultados:
epoch 0, loss_tr=5.542032 err_tr=0.984189 loss_te=4.996982 err_te=0.969038 err_te_snt=0.919913
epoch 8, loss_tr=1.693487 err_tr=0.434424 loss_te=2.735717 err_te=0.612260 err_te_snt=0.069264
epoch 16, loss_tr=0.861834 err_tr=0.229424 loss_te=2.465258 err_te=0.520276 err_te_snt=0.038240
epoch 24, loss_tr=0.528619 err_tr=0.144375 loss_te=2.948707 err_te=0.534053 err_te_snt=0.062049
epoch 32, loss_tr=0.362914 err_tr=0.100518 loss_te=2.530276 err_te=0.469060 err_te_snt=0.015152
epoch 40, loss_tr=0.267921 err_tr=0.076445 loss_te=2.761606 err_te=0.464799 err_te_snt=0.023088
epoch 48, loss_tr=0.215479 err_tr=0.061406 loss_te=2.737486 err_te=0.453493 err_te_snt=0.010823
epoch 56, loss_tr=0.173690 err_tr=0.050732 loss_te=2.812427 err_te=0.443322 err_te_snt=0.011544
epoch 64, loss_tr=0.145256 err_tr=0.043594 loss_te=2.917569 err_te=0.438507 err_te_snt=0.009380
epoch 72, loss_tr=0.128894 err_tr=0.038486 loss_te=3.009008 err_te=0.438005 err_te_snt=0.019481
....
epoch 320, loss_tr=0.033052 err_tr=0.009639 loss_te=4.076542 err_te=0.416710 err_te_snt=0.006494
epoch 328, loss_tr=0.033344 err_tr=0.010117 loss_te=3.928874 err_te=0.415024 err_te_snt=0.007215
epoch 336, loss_tr=0.033228 err_tr=0.010166 loss_te=4.030224 err_te=0.410034 err_te_snt=0.005051
epoch 344, loss_tr=0.033313 err_tr=0.010166 loss_te=4.402949 err_te=0.428691 err_te_snt=0.009380
epoch 352, loss_tr=0.031828 err_tr=0.009238 loss_te=4.080747 err_te=0.414066 err_te_snt=0.006494
epoch 360, loss_tr=0.033095 err_tr=0.009600 loss_te=4.254683 err_te=0.419954 err_te_snt=0.005772
El converge es inicialmente muy rápido (ver las primeras 30 épocas). Después de eso, la mejora del rendimiento disminuye y aparecen las oscilaciones en la tasa de error de oración. A pesar de estas oscilaciones, se puede observar una tendencia de mejora promedio para las épocas posteriores. En este experimento, detuvimos nuestro entrenamiento en la época 360. Los campos del archivo res.res tienen el siguiente significado:
Puede encontrar nuestro modelo capacitado para Timit aquí.
Para echar un vistazo a la implementación de Sincnet, debe abrir el archivo dnn_models.py y leer las clases Sincnet , SINC_CONV y la función SINC .
En este repositorio, utilizamos el conjunto de datos Timit como un tutorial para mostrar cómo funciona Sincnet. Con la versión actual del código, puede usar fácilmente un corpus diferente. Para hacerlo, debe proporcionar en la entrada los archivos de entrada específicos de Corpora (en formato WAV) y sus propias etiquetas. Por lo tanto, debe modificar las rutas en los archivos *.scp que encuentra en la carpeta data_lists.
Para asignar a cada oración la etiqueta correcta, también debe modificar el diccionario " timit_labels.npy ". Las etiquetas se especifican dentro de un diccionario de Python que contiene ID de oración como claves (por ejemplo, " SI1027 ") y Speaker_IDS como valores. Cada altavoz_id es un entero, que va de 0 a n_spks-1. En el conjunto de datos Timit, puede recuperar fácilmente la ID del altavoz de la ruta (p. Ej., Train/DR1/FCJF0/Si1027.Wav es la oración_id " Si1027 " pronunciada por el orador " FCJF0 "). Para otros conjuntos de datos, debería poder recuperar de tal manera que este diccionario contenga pares de altavoces e ID de oraciones.
Luego debe modificar el archivo de configuración ( CFG/sincnet_timit.cfg ) de acuerdo con sus nuevas rutas. Recuerde también cambiar el campo " class_lay = 462 " de acuerdo con el número de altavoces N_SPK que tiene en su conjunto de datos.
La versión del conjunto de datos de Librispeech utilizado en el documento está disponible a pedido . En nuestro trabajo, hemos utilizado solo 12-15 segundos de material de entrenamiento para cada altavoz y procesamos las oraciones originales de Libresiseect para realizar la normalización de la amplitud. Además, utilizamos un VAD basado en energía simple para evitar silencios al principio y al final de cada oración, así como para dividir en múltiples fragmentos las oraciones que contienen un silencio más largo
[1] Mirco Ravanelli, Yoshua Bengio, "Reconocimiento de altavoces de la forma de onda cruda con Sincnet" Arxiv


