VideoMAE
1.0.0
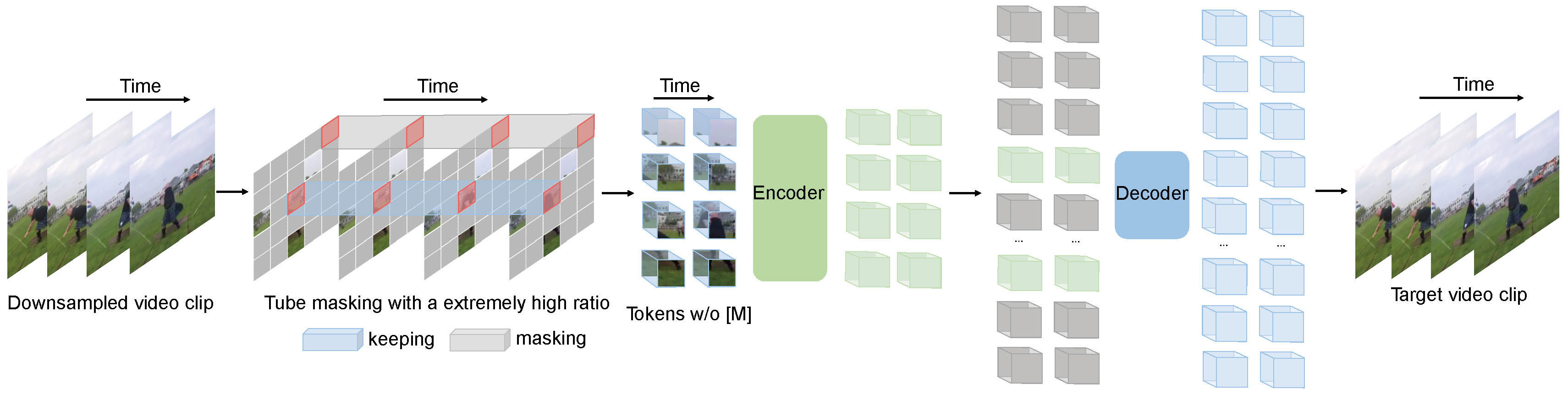
视频:蒙面自动编码器是自我监视视频预训练的数据效率学习者
Zhan Tong,Yibing Song,Jue Wang,Limin Wang
南京大学,腾讯AI实验室
[2023.4.18] ?每个人都可以从此链接中下载视频中使用的Kinetics-400 。
[2023.4.18]已发布了视频V2的代码和预训练的模型!检查并享受此仓库!
[2023.4.17]我们提出了Evad ,这是一个端到端的视频操作检测框架。
[2023.2.28]我们的视频V2被CVPR 2023接受! ?
[2023.1.16]可以在视频中使用代码和预训练的动作检测模型!
[2022.12.27] ?每个人都可以从Internvideo下载thumos , ActivityNet , HACS和Fineaction的提取的视频功能。
[2022.11.20] ? Videomae已融入并在@Sayak Paul的支持下。
[2022.10.25] ?视频已整合到MMATCTIO2中,可以成功地再现动力学400的结果。
[2022.10.20]可以提供Vit-S和Vit-H的预训练模型和脚本!
[2022.10.19]可以使用UCF101上的预训练模型和脚本!
[2022.9.15]视频被神经2022接受为聚光灯! ?
[2022.8.8] ? Videomae现在已整合到官方?Huggingface Transformers中!
[2022.7.7]我们已经在下游AVA 2.2基准上更新了新结果。请参阅我们的论文以获取详细信息。
[2022.4.24]现在可以使用代码和预训练的模型!
[2022.3.24]代码和预培训模型将在此处发布。欢迎观看此存储库以获取最新更新。
Videomae执行用于视频预训练的掩盖视频建模的任务。我们提出了极高的掩蔽率(90%-95%)和管掩蔽策略,以为自我监督的视频预训练创造一个具有挑战性的任务。
Videomae使用简单的蒙版自动编码器和普通VIT主链来执行视频自我监督学习。由于掩盖率极高,视频的预训练时间比对比度学习方法( 3.2倍加速)要短得多。视频可以作为一个简单但强大的基线,用于在自我监视的视频预训练中进行未来的研究。
视频对不同尺度的视频数据集效果很好,可以在Kinects-400上获得87.4%的效果,在某种程度上,v2的v2,UCF101的91.3% , HMDB51的效果为75.4%,为91.3% 。据我们所知,Videomae是第一个使用香草VIT骨架在这四个受欢迎的基准测试上实现最先进的性能的视频,而不需要任何额外的数据或预训练的模型。
| 方法 | 额外的数据 | 骨干 | 解决 | #Frames X剪辑X农作物 | top-1 | 前五名 |
|---|---|---|---|---|---|---|
| 视频 | 不 | vit-s | 224x224 | 16x2x3 | 66.8 | 90.3 |
| 视频 | 不 | vit-b | 224x224 | 16x2x3 | 70.8 | 92.4 |
| 视频 | 不 | vit-l | 224x224 | 16x2x3 | 74.3 | 94.6 |
| 视频 | 不 | vit-l | 224x224 | 32x1x3 | 75.4 | 95.2 |
| 方法 | 额外的数据 | 骨干 | 解决 | #Frames X剪辑X农作物 | top-1 | 前五名 |
|---|---|---|---|---|---|---|
| 视频 | 不 | vit-s | 224x224 | 16x5x3 | 79.0 | 93.8 |
| 视频 | 不 | vit-b | 224x224 | 16x5x3 | 81.5 | 95.1 |
| 视频 | 不 | vit-l | 224x224 | 16x5x3 | 85.2 | 96.8 |
| 视频 | 不 | VIT-H | 224x224 | 16x5x3 | 86.6 | 97.1 |
| 视频 | 不 | vit-l | 320x320 | 32x4x3 | 86.1 | 97.3 |
| 视频 | 不 | VIT-H | 320x320 | 32x4x3 | 87.4 | 97.6 |
请在视频动作检测中检查代码和检查点。
| 方法 | 额外的数据 | 额外的标签 | 骨干 | #Frame X样本率 | 地图 |
|---|---|---|---|---|---|
| 视频 | 动力学400 | ✗ | vit-s | 16x4 | 22.5 |
| 视频 | 动力学400 | ✓ | vit-s | 16x4 | 28.4 |
| 视频 | 动力学400 | ✗ | vit-b | 16x4 | 26.7 |
| 视频 | 动力学400 | ✓ | vit-b | 16x4 | 31.8 |
| 视频 | 动力学400 | ✗ | vit-l | 16x4 | 34.3 |
| 视频 | 动力学400 | ✓ | vit-l | 16x4 | 37.0 |
| 视频 | 动力学400 | ✗ | VIT-H | 16x4 | 36.5 |
| 视频 | 动力学400 | ✓ | VIT-H | 16x4 | 39.5 |
| 视频 | 动力学700 | ✗ | vit-l | 16x4 | 36.1 |
| 视频 | 动力学700 | ✓ | vit-l | 16x4 | 39.3 |
| 方法 | 额外的数据 | 骨干 | UCF101 | HMDB51 |
|---|---|---|---|---|
| 视频 | 不 | vit-b | 91.3 | 62.6 |
| 视频 | 动力学400 | vit-b | 96.1 | 73.3 |
请按照install.md中的说明进行操作。
请按照Dataset.md中的说明进行数据准备。
训练前的指令在Prarin.md中。
微调指令在Finetune.md中。
我们在model_zoo.md中提供预训练和微调的模型。
我们在vis.sh中提供可视化的脚本。 COLAB笔记本以进行更好的可视化,即将推出。
Zhan Tong:[email protected]
感谢Ziteng Gao,Lei Chen,Chongjian GE和Zhiyu Zhao的友好支持。
该项目建立在Mae-Pytorch和Beit上。感谢这些出色代码库的贡献者。
该项目的大多数是根据许可证文件中发现的CC-BY-NC 4.0许可证发布的。该项目的部分可在单独的许可条款下获得:SlowFast和Pytorch-Image-Models由Apache 2.0许可证获得许可。 Beit已获得MIT许可证的许可。
如果您认为此项目很有帮助,请随时留下星际并引用我们的论文:
@inproceedings{tong2022videomae,
title={Video{MAE}: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training},
author={Zhan Tong and Yibing Song and Jue Wang and Limin Wang},
booktitle={Advances in Neural Information Processing Systems},
year={2022}
}
@article{videomae,
title={VideoMAE: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training},
author={Tong, Zhan and Song, Yibing and Wang, Jue and Wang, Limin},
journal={arXiv preprint arXiv:2203.12602},
year={2022}
}


