VideoMAE
1.0.0
Videomae: أجهزة الترميز التلقائي المقنعة هي متعلمين فعالين في البيانات للفيديو الذي يتم إشرافه ذاتيًا قبل التدريب
Zhan Tong ، Yibing Song ، Jue Wang ، Limin Wang
جامعة نانجينغ ، Tencent AI Lab
[2023.4.18] ؟ يمكن للجميع تنزيل الحركية -400 ، والتي تستخدم في Videomae ، من هذا الرابط.
[2023.4.18] تم إصدار الكود والنماذج المدربة مسبقًا من Videomae V2! تحقق واستمتع بهذا الريبو!
[2023.4.17] نقترح إيفاد ، إطار عمل لاكتشاف عمل الفيديو الشامل .
[2023.2.28] يتم قبول Videomae V2 من قبل CVPR 2023 ! ؟
[2023.1.16] تتوفر الكود والنماذج التي تم تدريبها قبل الكشف عن الإجراءات في Videomae!
[2022.12.27] ؟ يمكن للجميع تنزيل ميزات الفيديو المستخرجة من Thumos و ActivityNet و HACS و Fineaction من Internvideo.
[2022.11.20] ؟ تم دمج Videomae في ، وبدعم من Sayak Paul.
[2022.10.25] ؟ تم دمج Videomae في MMAction2 ، ويمكن إعادة إنتاج النتائج على الحركية -400 بنجاح.
[2022.10.20] تتوفر النماذج والبرامج النصية التي تم تدريبها مسبقًا من VIT-S و VIT-H !
[2022.10.19] تتوفر النماذج والبرامج النصية التي تم تدريبها مسبقًا على UCF101 !
[2022.9.15] يتم قبول Videomae بواسطة Neurips 2022 كعرض تقديمي للأضواء ! ؟
[2022.8.8] ؟ تم دمج Videomae في محولات Huggingface الرسمية الآن!
[2022.7.7] قمنا بتحديث نتائج جديدة على معايير AVA 2.2 المصب. يرجى الرجوع إلى ورقتنا للحصول على التفاصيل.
[2022.4.24] تتوفر الكود والنماذج المدربة مسبقًا الآن!
[2022.3.24] سيتم إصدار الكود والنماذج التي تم تدريبها مسبقًا هنا. مرحبًا بك لمشاهدة هذا المستودع للحصول على آخر التحديثات.
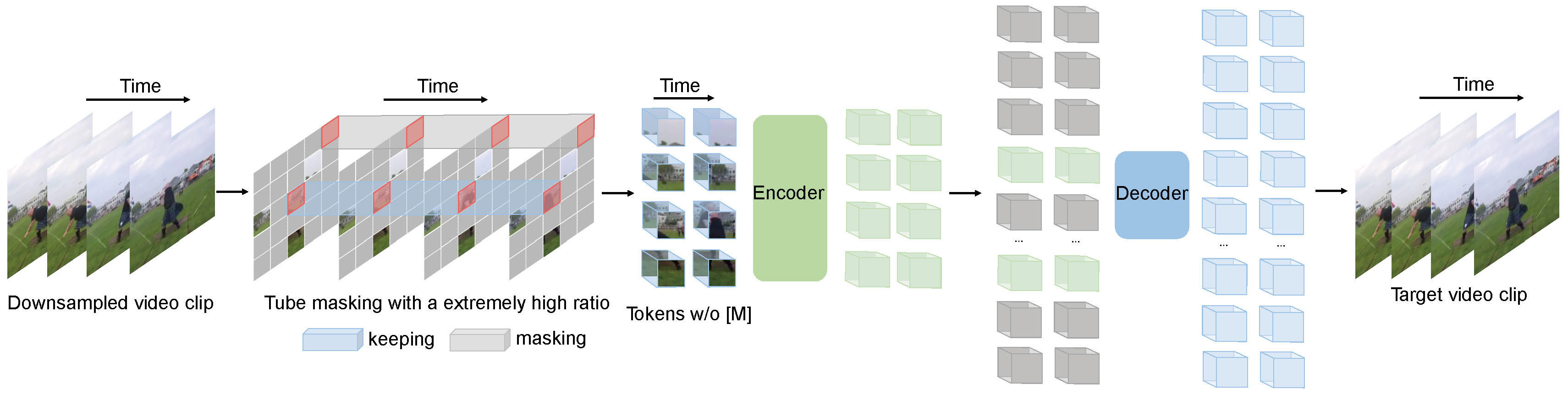
تقوم Videomae بمهمة نمذجة الفيديو المقنعة للتدريب المسبق للفيديو. نقترح نسبة التقنيع المرتفعة للغاية (90 ٪ -95 ٪) واستراتيجية إخفاء الأنبوب لإنشاء مهمة صعبة للتدريب المسبق للفيديو.
يستخدم Videomae Autoender Simple المقنعة والعمود الفقري العادي في VIT لأداء التعلم الخاضع للإشراف على الفيديو. نظرًا لنسبة التقنيع المرتفعة للغاية ، يكون وقت التدريب المسبق للفيديو أقصر بكثير من طرق التعلم التباين (تسريع 3.2x ). يمكن أن تكون Videomae بمثابة خط أساسي بسيط ولكنه قوي للبحث المستقبلي في التدريب على الفيديو الخاضع للإشراف ذاتيًا.
تعمل Videomae بشكل جيد لمجموعات بيانات الفيديو ذات المقاييس المختلفة ويمكنها تحقيق 87.4 ٪ على Kinects-400 ، و 75.4 ٪ على شيء ما ، و 91.3 ٪ على UCF101 ، و 62.6 ٪ على HMDB51. على أفضل حالاتنا ، تعتبر Videomae أول من يحقق الأداء الحديث في هذه المعايير الأربعة الشائعة مع العمود الفقري الفانيليا فير ، بينما لا تحتاج إلى أي بيانات إضافية أو نماذج مدربة مسبقًا.
| طريقة | بيانات إضافية | العمود الفقري | دقة | #fframes x clips x محاصيل | أعلى 1 | أعلى 5 |
|---|---|---|---|---|---|---|
| videomae | لا | VIT-S | 224x224 | 16x2x3 | 66.8 | 90.3 |
| videomae | لا | فيت ب | 224x224 | 16x2x3 | 70.8 | 92.4 |
| videomae | لا | VIT-L | 224x224 | 16x2x3 | 74.3 | 94.6 |
| videomae | لا | VIT-L | 224x224 | 32x1x3 | 75.4 | 95.2 |
| طريقة | بيانات إضافية | العمود الفقري | دقة | #fframes x clips x محاصيل | أعلى 1 | أعلى 5 |
|---|---|---|---|---|---|---|
| videomae | لا | VIT-S | 224x224 | 16x5x3 | 79.0 | 93.8 |
| videomae | لا | فيت ب | 224x224 | 16x5x3 | 81.5 | 95.1 |
| videomae | لا | VIT-L | 224x224 | 16x5x3 | 85.2 | 96.8 |
| videomae | لا | VIT-H | 224x224 | 16x5x3 | 86.6 | 97.1 |
| videomae | لا | VIT-L | 320 × 320 | 32x4x3 | 86.1 | 97.3 |
| videomae | لا | VIT-H | 320 × 320 | 32x4x3 | 87.4 | 97.6 |
يرجى التحقق من الكود ونقاط التفتيش في الكشف عن عمل الفيديو.
| طريقة | بيانات إضافية | تسمية إضافية | العمود الفقري | #إطار X معدل العينة | رسم خريطة |
|---|---|---|---|---|---|
| videomae | حركية-400 | ✗ | VIT-S | 16x4 | 22.5 |
| videomae | حركية-400 | ✓ | VIT-S | 16x4 | 28.4 |
| videomae | حركية-400 | ✗ | فيت ب | 16x4 | 26.7 |
| videomae | حركية-400 | ✓ | فيت ب | 16x4 | 31.8 |
| videomae | حركية-400 | ✗ | VIT-L | 16x4 | 34.3 |
| videomae | حركية-400 | ✓ | VIT-L | 16x4 | 37.0 |
| videomae | حركية-400 | ✗ | VIT-H | 16x4 | 36.5 |
| videomae | حركية-400 | ✓ | VIT-H | 16x4 | 39.5 |
| videomae | حركية 700 | ✗ | VIT-L | 16x4 | 36.1 |
| videomae | حركية 700 | ✓ | VIT-L | 16x4 | 39.3 |
| طريقة | بيانات إضافية | العمود الفقري | UCF101 | HMDB51 |
|---|---|---|---|---|
| videomae | لا | فيت ب | 91.3 | 62.6 |
| videomae | حركية-400 | فيت ب | 96.1 | 73.3 |
يرجى اتباع التعليمات في install.md.
يرجى اتباع الإرشادات الموجودة في Dataset.md لإعداد البيانات.
تعليمات ما قبل التدريب في presrain.md.
تعليمات الضبط في finetune.md.
نحن نقدم نماذج مدربة وضبطها مسبقًا في Model_zoo.md.
نحن نقدم البرنامج النصي للتصور في vis.sh Colab Notebook لتحسين التصور سيأتي قريبًا.
Zhan Tong: [email protected]
بفضل Ziteng Gao و Lei Chen و Chongjian Ge و Zhiyu Zhao لدعمهم اللطيف.
تم بناء هذا المشروع على Mae-Pytorch و Beit. بفضل المساهمين في هذه الأدوات الرمزية الرائعة.
يتم إصدار غالبية هذا المشروع بموجب ترخيص CC-By-NC 4.0 كما هو موجود في ملف الترخيص. تتوفر أجزاء من المشروع بموجب شروط ترخيص منفصلة: تم ترخيص نموذجات الصور البطيئة و PYTORCH بموجب ترخيص Apache 2.0. BEIT مرخصة بموجب ترخيص معهد ماساتشوستس للتكنولوجيا.
إذا كنت تعتقد أن هذا المشروع مفيد ، فلا تتردد في ترك نجم واستشهد بورقة:
@inproceedings{tong2022videomae,
title={Video{MAE}: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training},
author={Zhan Tong and Yibing Song and Jue Wang and Limin Wang},
booktitle={Advances in Neural Information Processing Systems},
year={2022}
}
@article{videomae,
title={VideoMAE: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training},
author={Tong, Zhan and Song, Yibing and Wang, Jue and Wang, Limin},
journal={arXiv preprint arXiv:2203.12602},
year={2022}
}


